Parámetros de generación
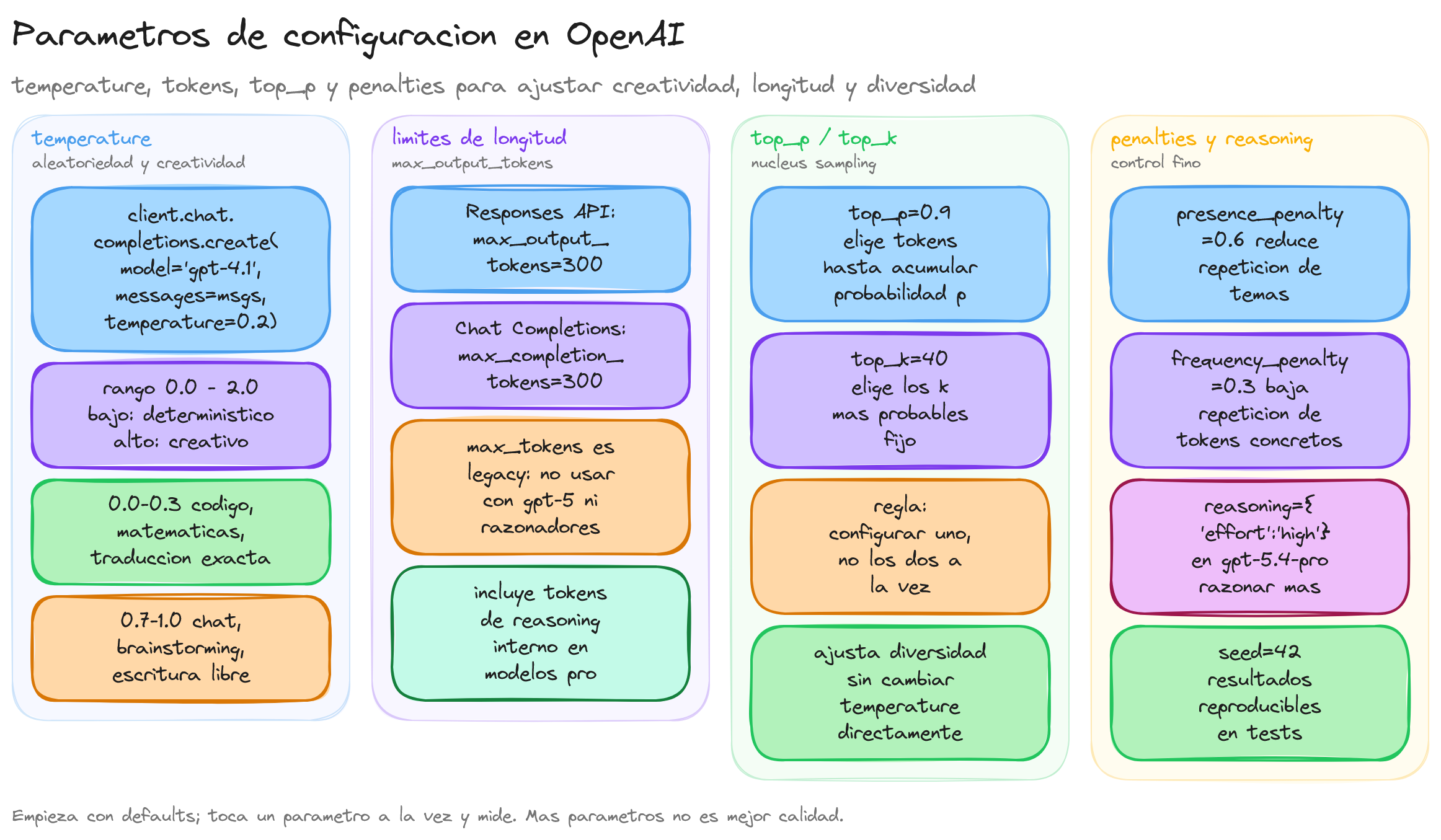
Los parámetros de configuración son valores que controlan el comportamiento del modelo durante la generación de texto. Cada parámetro influye en aspectos específicos como la creatividad, longitud y coherencia de las respuestas. Comprender estos parámetros te permitirá ajustar finamente el comportamiento del modelo según tus necesidades específicas.

Nota legacy: esta lección conserva varios ejemplos con
gpt-4.1ychat.completions.create()porque siguen siendo una forma didáctica de explicar parámetros clásicos comotemperature,top_pomax_completion_tokens. El modelogpt-4.1está deprecado desde 2025. Para proyectos nuevos se recomienda usar la Responses API con modelos de la familia GPT-5.4 (gpt-5.4,gpt-5.4-mini,gpt-5.4-nano), ya que no todos los parámetros se comportan igual en todas las familias.
Temperature
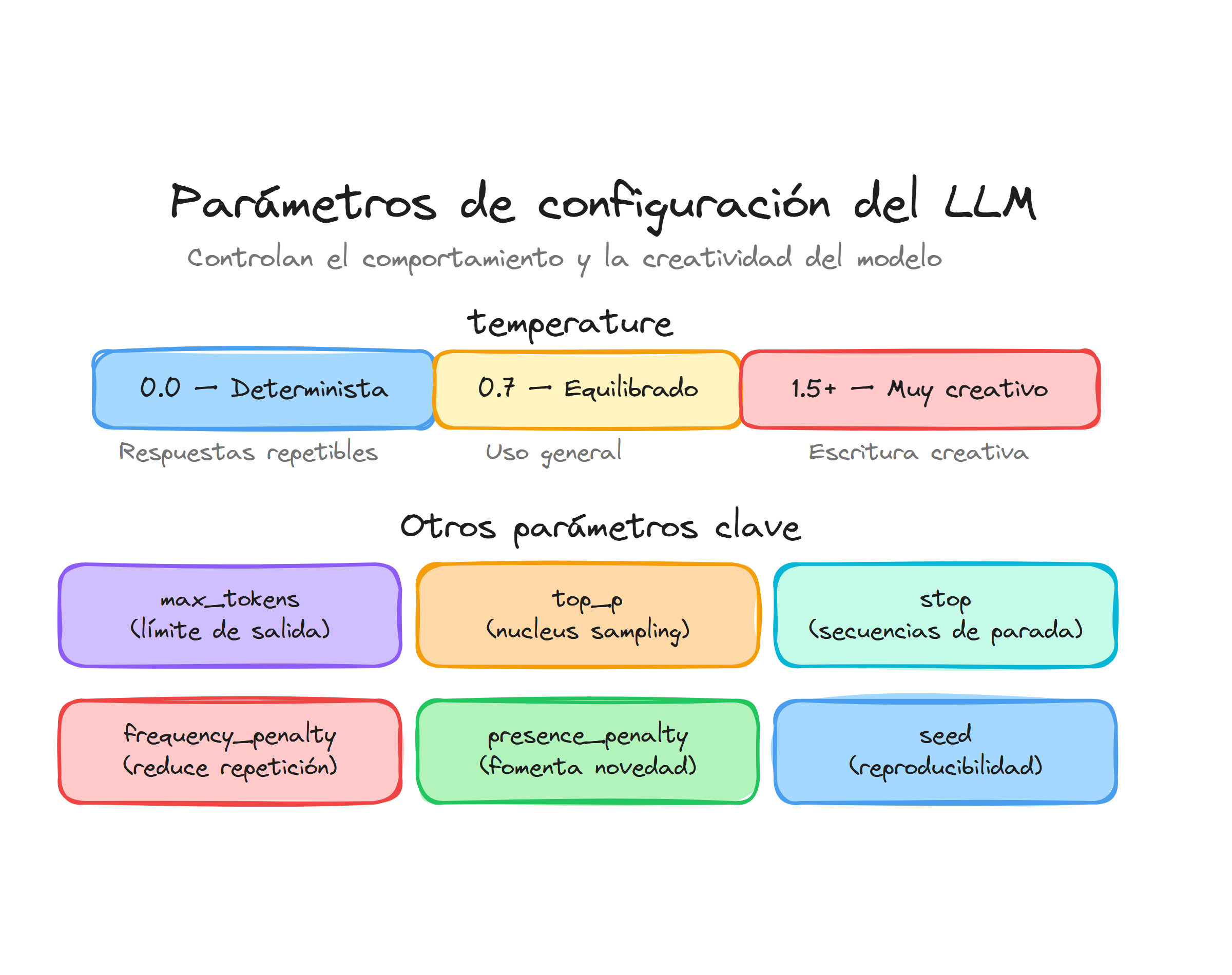
El parámetro temperature controla la aleatoriedad y creatividad en las respuestas del modelo. Su valor oscila entre 0.0 y 2.0, donde valores más bajos producen respuestas más deterministas y predecibles, mientras que valores más altos generan respuestas más creativas y variadas.
from openai import OpenAI
client = OpenAI()
# Temperature baja (0.2) - Respuestas más conservadoras
response_conservative = client.chat.completions.create(
model="gpt-4.1",
messages=[{"role": "user", "content": "Explica qué es la fotosíntesis"}],
temperature=0.2
)
print("Respuesta conservadora:", response_conservative.choices[0].message.content)
# Temperature alta (1.5) - Respuestas más creativas
response_creative = client.chat.completions.create(
model="gpt-4.1",
messages=[{"role": "user", "content": "Explica qué es la fotosíntesis"}],
temperature=1.5
)
print("Respuesta creativa:", response_creative.choices[0].message.content)
Con temperature=0.2, obtendrás explicaciones técnicas precisas y consistentes. Con temperature=1.5, las respuestas serán más variadas, posiblemente usando analogías creativas o enfoques menos convencionales.
La temperatura controla la aleatoriedad y creatividad de las respuestas. Valores bajos hacen que el modelo sea más determinista y conservador, valores altos lo hacen más creativo pero menos predecible.
0.0 - 0.3: Tareas que requieren precisión (matemáticas, código, análisis técnico, traducción)0.7 - 1.0: Escritura creativa, lluvia de ideas, conversación general1.2 - 2.0: Experimentación extrema, poetry, contenido muy creativo
NOTA sobre compatibilidad: El parámetro
temperaturefunciona de forma más predecible en superficies clásicas como Chat Completions con modelos de texto no razonadores. En la familia GPT-5, el soporte depende del modelo, del endpoint y de la configuración dereasoning, así que conviene verificar siempre la documentación vigente antes de trasladar un ejemplo 1:1.
Límite de tokens en la respuesta
Existen diferentes parámetros para limitar la longitud de las respuestas dependiendo de la API y el modelo que utilices. Un token puede ser una palabra, parte de una palabra, o incluso un carácter, dependiendo del contexto.
En la API Chat Completions se utiliza max_completion_tokens:
from openai import OpenAI
client = OpenAI()
# Respuesta corta limitada a 50 tokens
response_short = client.chat.completions.create(
model="gpt-4.1",
messages=[{"role": "user", "content": "Resume los beneficios del ejercicio físico"}],
max_completion_tokens=50
)
print("Respuesta corta:", response_short.choices[0].message.content)
# Respuesta más extensa con límite de 300 tokens
response_long = client.chat.completions.create(
model="gpt-4.1",
messages=[{"role": "user", "content": "Resume los beneficios del ejercicio físico"}],
max_completion_tokens=300
)
print("Respuesta extensa:", response_long.choices[0].message.content)
En la API Responses se utiliza max_output_tokens:
from openai import OpenAI
client = OpenAI()
# Usando la API Responses
response = client.responses.create(
model="gpt-4.1",
input="Resume los beneficios del ejercicio físico",
max_output_tokens=100
)
print(response.output_text)
El parámetro max_completion_tokens establece un límite superior para los tokens que puede generar el modelo, incluyendo tanto los tokens de salida visibles como los tokens de razonamiento interno en modelos que soportan esta funcionalidad.
NOTA: El parámetro
max_tokensestá deprecado y no es compatible con los modelos de razonamiento (serie gpt-5.x y o-series). Debes usarmax_completion_tokensen Chat Completions omax_output_tokensen la API Responses.
Budget Tokens
El parámetro budget_tokens es específico de los modelos Claude de Anthropic y controla la cantidad máxima de tokens que el modelo puede utilizar durante su proceso de razonamiento interno o "pensamiento extendido" (Extended Thinking). Este parámetro establece un límite presupuestario para el análisis interno que realiza el modelo antes de generar la respuesta final.
Este parámetro se configura dentro del objeto thinking al realizar una petición y requiere que la función de pensamiento extendido esté habilitada. El valor de budget_tokens debe ser siempre menor que el parámetro max_tokens, ya que representa solo el presupuesto para el razonamiento interno, no para la respuesta visible.
import anthropic
client = anthropic.Anthropic()
# Configurar presupuesto de tokens para razonamiento interno
response = client.messages.create(
model="claude-3-5-sonnet-20241022",
max_tokens=2000,
thinking={
"enabled": True,
"budget_tokens": 10000
},
messages=[
{
"role": "user",
"content": "Analiza las ventajas y desventajas de implementar microservicios"
}
]
)
print(response.content[0].text)
Un valor más alto en budget_tokens permite al modelo realizar un análisis más profundo y elaborado antes de responder, lo que puede mejorar la calidad y precisión de respuestas complejas. Sin embargo, valores superiores a 32000 tokens generalmente no son utilizados en su totalidad por el modelo.
Este parámetro resulta especialmente útil en tareas que requieren razonamiento complejo como análisis técnico profundo, resolución de problemas matemáticos avanzados o evaluación de múltiples alternativas antes de generar una respuesta.
Top P y Top K
Cuando un modelo genera texto, calcula una probabilidad para cada palabra candidata del vocabulario. Los parámetros top_p y top_k determinan qué palabras candidatas se consideran en cada paso de generación.
Supongamos que el modelo debe elegir la siguiente palabra y calcula estas probabilidades:
"gato" → 35%
"perro" → 25%
"animal" → 15%
"mamífero" → 10%
"felino" → 8%
"mascota" → 4%
...miles más con <1%
Top K selecciona un número fijo de candidatos más probables:
Con top_k=3, solo considera las 3 primeras:
"gato" → 35% ✓
"perro" → 25% ✓
"animal" → 15% ✓
(resto descartado)
Limitación: Es rígido. Siempre usa exactamente 3 candidatos, aunque a veces esas 3 sumen el 95% (decisión clara) y otras veces solo el 40% (mucha incertidumbre).
Top P selecciona candidatos hasta alcanzar un porcentaje acumulado de probabilidad:
Con top_p=0.75, suma hasta el 75%:
"gato" → 35% (acum: 35%) ✓
"perro" → 25% (acum: 60%) ✓
"animal" → 15% (acum: 75%) ✓ ← Se detiene
"mamífero" → 10% ✗
Ventaja: Es adaptativo. Si hay mucha certeza, usa pocos candidatos. Si hay incertidumbre, considera más opciones. Esto hace que top_p sea preferible en la mayoría de casos.
from openai import OpenAI
client = OpenAI()
# top_p bajo - Respuestas precisas y predecibles
response_precise = client.chat.completions.create(
model="gpt-4.1",
messages=[{"role": "user", "content": "¿Cuál es la capital de Francia?"}],
top_p=0.1
)
print("Respuesta precisa:", response_precise.choices[0].message.content)
# top_p alto - Mayor creatividad y variedad
response_creative = client.chat.completions.create(
model="gpt-4.1",
messages=[{"role": "user", "content": "Escribe un poema sobre el mar"}],
top_p=0.95
)
print("Respuesta creativa:", response_creative.choices[0].message.content)
Valores recomendados:
-
top_p (rango 0.0-1.0):
0.1-0.3: Tareas que requieren precisión (matemáticas, código, datos técnicos)0.8-0.95: Valor estándar que balancea coherencia y creatividad0.95-1.0: Máxima variedad para contenido creativo
-
top_k (número entero):
1-10: Respuestas muy deterministas20-40: Balance para tareas generales50-100: Mayor variedad léxica-1: Desactivado (usar solo top_p)
NOTA: OpenAI no soporta el parámetro top_k en su API, solo top_p. Otros proveedores como Google (Gemini) y Anthropic (Claude) sí permiten configurar ambos parámetros. Al igual que
temperature, el parámetrotop_ptiene las mismas restricciones en modelos de razonamiento.
Ejemplos de configuración por proveedor:
Anthropic permite configurar top_k y top_p:

Google AI Studio ofrece temperature:

Y también top_p:

Frequency Penalty
El parámetro frequency_penalty penaliza tokens en función de su frecuencia de aparición en el texto ya generado. Sus valores oscilan entre -2.0 y 2.0, donde valores positivos reducen la probabilidad de que se repitan palabras que ya han aparecido múltiples veces.
Este parámetro es especialmente útil cuando deseas evitar repeticiones léxicas en textos largos. A diferencia de presence_penalty, frequency_penalty tiene en cuenta cuántas veces ha aparecido un token, no solo si ha aparecido o no.
from openai import OpenAI
client = OpenAI()
# Sin penalty - puede generar texto repetitivo
response_normal = client.chat.completions.create(
model="gpt-4.1",
messages=[
{"role": "user", "content": "Escribe un párrafo sobre la importancia del agua"}
],
frequency_penalty=0.0
)
print("Sin penalty:", response_normal.choices[0].message.content)
# Con frequency_penalty alto - evita repeticiones
response_varied = client.chat.completions.create(
model="gpt-4.1",
messages=[
{"role": "user", "content": "Escribe un párrafo sobre la importancia del agua"}
],
frequency_penalty=1.5
)
print("Con penalty:", response_varied.choices[0].message.content)
Con frequency_penalty=0.0, el modelo puede repetir palabras como "agua", "vital", "importante" varias veces. Con frequency_penalty=1.5, el modelo variará más su vocabulario, utilizando sinónimos y diferentes estructuras para evitar la repetición excesiva.
Los valores recomendados son:
0.0: Sin penalización, útil para respuestas técnicas que requieren terminología específica0.3 - 0.7: Reducción moderada de repeticiones para la mayoría de casos1.0 - 2.0: Máxima diversidad léxica, útil en generación creativa
Presence Penalty
El parámetro presence_penalty penaliza tokens según si ya han aparecido previamente en el texto, independientemente de cuántas veces. Sus valores también oscilan entre -2.0 y 2.0, donde valores positivos animan al modelo a introducir nuevos temas y conceptos.
A diferencia de frequency_penalty que cuenta ocurrencias, presence_penalty simplemente verifica la presencia o ausencia de un token. Esto hace que el modelo sea más propenso a explorar nuevas ideas y cambiar de tema.
from openai import OpenAI
client = OpenAI()
# Sin penalty - puede mantener el mismo tema
response_focused = client.chat.completions.create(
model="gpt-4.1",
messages=[
{"role": "user", "content": "Háblame sobre inteligencia artificial"}
],
presence_penalty=0.0
)
print("Respuesta enfocada:", response_focused.choices[0].message.content)
# Con presence_penalty alto - introduce nuevos conceptos
response_exploratory = client.chat.completions.create(
model="gpt-4.1",
messages=[
{"role": "user", "content": "Háblame sobre inteligencia artificial"}
],
presence_penalty=1.8
)
print("Respuesta exploratoria:", response_exploratory.choices[0].message.content)
Con presence_penalty=0.0, el modelo se centrará en profundizar sobre el mismo tema. Con presence_penalty=1.8, el modelo tenderá a introducir aspectos diferentes y relacionados, como aplicaciones, historia, implicaciones éticas, etc.
Valores típicos:
0.0: Sin penalización, mantiene el foco en el tema principal0.5 - 1.0: Balance entre profundidad y variedad temática1.5 - 2.0: Máxima exploración de nuevos temas y conceptos
NOTA: Los parámetros frequency_penalty y presence_penalty están disponibles en la API Chat Completions pero no en la API Responses de OpenAI.
Stop Sequences
El parámetro stop permite definir secuencias de texto donde el modelo debe detener la generación. Cuando el modelo encuentra alguna de estas secuencias, finaliza la respuesta inmediatamente, excluyendo la secuencia de parada del resultado.
Puedes especificar hasta 4 secuencias de parada diferentes, y el modelo se detendrá al encontrar cualquiera de ellas. Este parámetro resulta fundamental para controlar el formato y la estructura de las respuestas.
from openai import OpenAI
client = OpenAI()
# Detener en saltos de línea dobles
response = client.chat.completions.create(
model="gpt-4.1",
messages=[
{"role": "user", "content": "Lista 3 lenguajes de programación"}
],
stop=["\n\n"]
)
print(response.choices[0].message.content)
# Detener en múltiples secuencias
response = client.chat.completions.create(
model="gpt-4.1",
messages=[
{"role": "user", "content": "Genera un diálogo"}
],
stop=["Usuario:", "Fin", "\n---"]
)
print(response.choices[0].message.content)
Las stop sequences son útiles en diversos escenarios:
- Control de formato: Detener la generación en marcadores específicos como "---" o "###"
- Diálogos estructurados: Parar cuando aparezca un nuevo turno de conversación
- Generación por párrafos: Detener en saltos de línea para obtener respuestas concisas
- Plantillas: Finalizar cuando se complete una sección específica de una plantilla
from openai import OpenAI
client = OpenAI()
# Ejemplo práctico: generar solo el título de un artículo
response = client.chat.completions.create(
model="gpt-4.1",
messages=[
{"role": "user", "content": "Escribe un artículo sobre Python:\n\nTítulo:"}
],
stop=["\n"],
max_completion_tokens=100
)
print(response.choices[0].message.content)
# Output: "Domina Python: Guía Completa para Principiantes"
En este ejemplo, el modelo generará solo el título y se detendrá al encontrar el primer salto de línea, evitando que continúe generando el cuerpo del artículo.
Combinación de parámetros
Los parámetros funcionan de manera complementaria y su combinación determina el comportamiento final del modelo. Puedes ajustar múltiples parámetros simultáneamente para lograr el equilibrio deseado:

Fuentes y referencias
Documentación oficial y recursos externos para profundizar en OpenAI SDK
Documentación oficial de OpenAI SDK
Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, OpenAI SDK es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de OpenAI SDK
Explora más contenido relacionado con OpenAI SDK y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
- Comprender el propósito y efecto de los parámetros temperature, max_tokens, top_p y top_k en la generación de texto.
- Aprender a ajustar estos parámetros para controlar la creatividad, coherencia, longitud y estilo de las respuestas.
- Analizar cómo la combinación de parámetros afecta la precisión factual y la repetitividad del contenido.
- Identificar configuraciones óptimas según el tipo de contenido deseado (técnico, creativo, equilibrado).
- Entender la interacción entre parámetros para personalizar el comportamiento del modelo según necesidades específicas.