Model Spec y catálogo de modelos
El Model Spec no describe la arquitectura interna del modelo. Es una especificación de comportamiento que explica cómo debe priorizar instrucciones, cómo tratar información dudosa y qué límites de seguridad o estilo debe respetar el sistema.
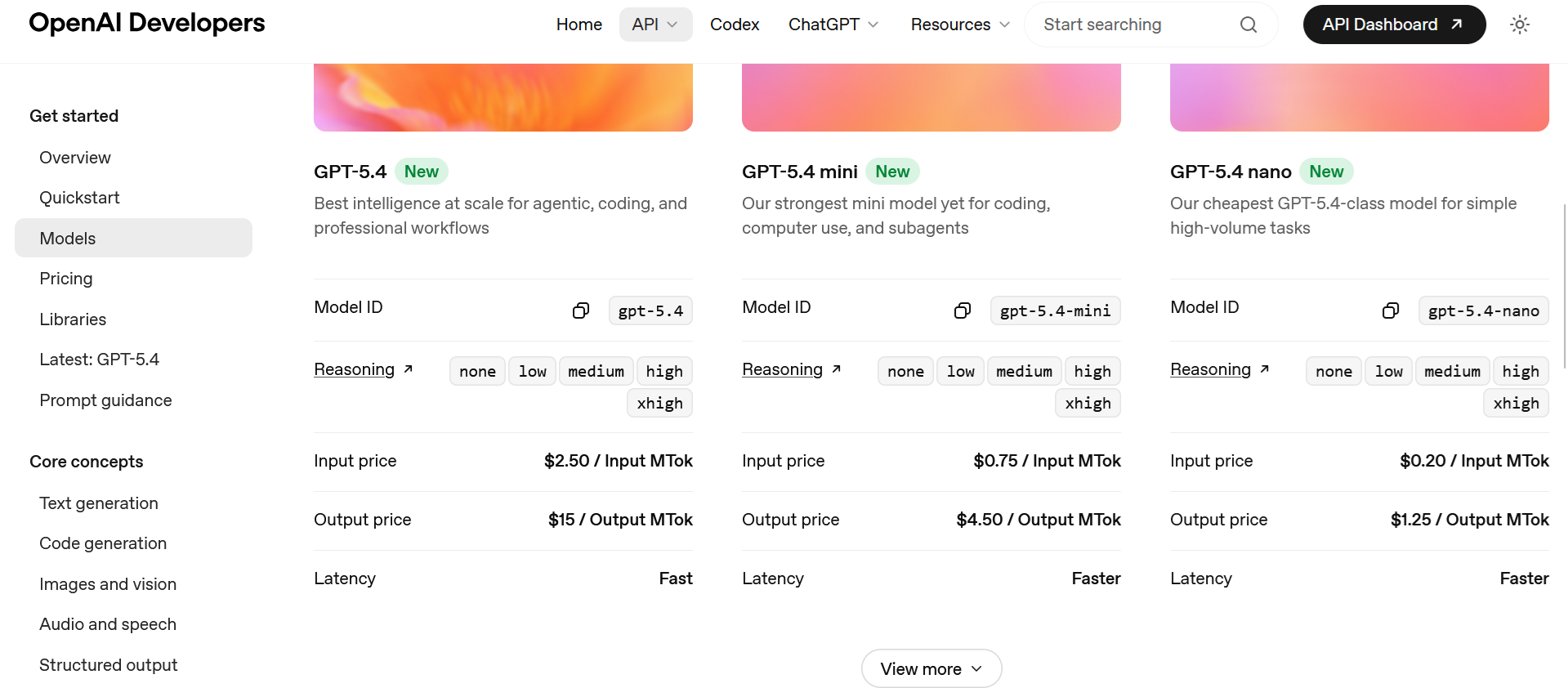
Para elegir un modelo concreto, la referencia práctica es la documentación oficial de modelos de OpenAI. Ahí se publican los alias recomendados, los snapshots disponibles y los cambios de catálogo.
Una cosa es el comportamiento esperado del modelo y otra distinta qué alias conviene usar en tu código.
Familia GPT-5 actual
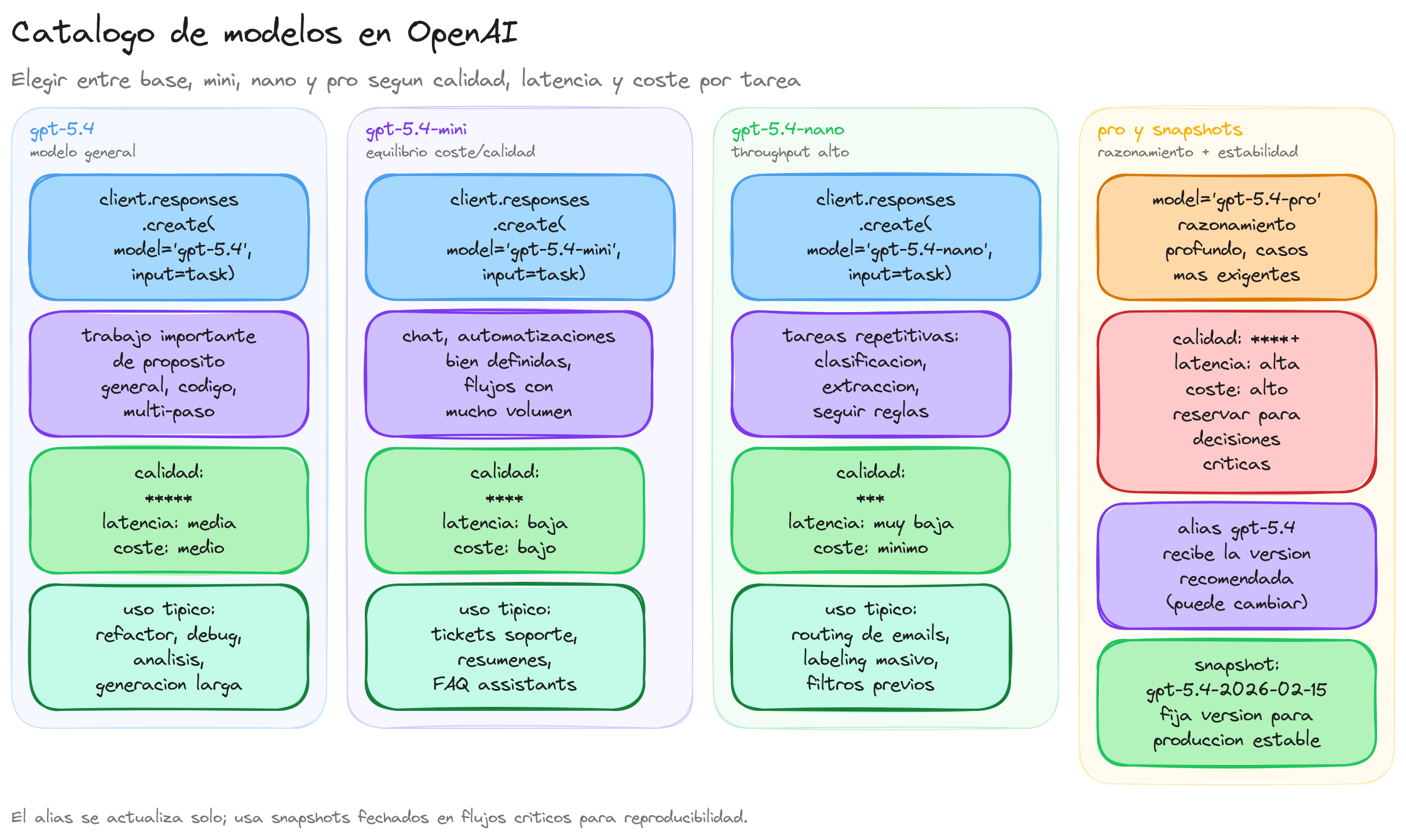
En el catálogo actual, gpt-5.4 es el modelo general recomendado para trabajo importante de propósito general, código y tareas complejas de varios pasos.
Más que memorizar el alias exacto del momento, conviene entender el rol de cada variante: suele haber un modelo principal para trabajo general, una variante mini para equilibrio entre coste y capacidad, una variante nano para tareas sencillas de alto volumen y, en algunos casos, una variante pro para problemas especialmente difíciles.
from openai import OpenAI
client = OpenAI()
response = client.responses.create(
model="gpt-5.4",
input="Analiza pros y contras de migrar una API REST a arquitectura orientada a eventos."
)
print(response.output_text)
Cuando necesitas una versión más pequeña y eficiente en coste, OpenAI recomienda gpt-5.4-mini. Este modelo resulta adecuado para chat, automatizaciones bien definidas y flujos con mucho volumen donde quieres mantener un buen equilibrio entre velocidad, coste y capacidad.
response = client.responses.create(
model="gpt-5.4-mini",
input="Redacta una respuesta breve para un ticket de soporte sobre restablecimiento de contraseña."
)
Para tareas muy repetitivas y de alto rendimiento, como clasificación, extracción sencilla o seguimiento de instrucciones directas, la opción natural es gpt-5.4-nano.
response = client.responses.create(
model="gpt-5.4-nano",
input="Clasifica este correo como 'ventas', 'soporte' o 'facturación'."
)
Regla rápida:
gpt-5.4para calidad general,gpt-5.4-minipara equilibrio,gpt-5.4-nanopara throughput.
Cuándo usar la variante pro
Si el problema es especialmente difícil y te compensa permitir más cómputo para mejorar la calidad, la familia incorpora gpt-5.4-pro. Su propósito no es sustituir al modelo general en todo, sino resolver casos donde la profundidad adicional merece la latencia y el coste extra.
Razonamiento y variantes especializadas
En la práctica actual, el razonamiento profundo se entiende mejor como una capacidad dentro del ecosistema GPT-5 que como una familia aislada que debas memorizar. Lo importante es distinguir entre:
- una variante general para la mayoría de tareas complejas,
- una variante pro para los problemas más exigentes,
- y variantes mini o nano cuando prima el coste o la latencia.
En series anteriores existieron modelos con nombres como o3 u o4-mini, pero en un curso evergreen conviene tratarlos como referencias históricas o comparativas, no como la forma principal de enseñar hoy la selección de modelos.
response = client.responses.create(
model="gpt-5.4-pro",
input="Evalúa tres estrategias de despliegue y justifica cuál reduce mejor el riesgo operativo."
)
El rasgo distintivo de estas variantes es el razonamiento estructurado. No significa que todos los problemas deban enviarse al modelo más potente, sino que conviene reservar el razonamiento más costoso para casos donde esa profundidad aporta valor real.
Cómo elegir un modelo
El criterio principal para elegir modelo no es la moda ni el nombre más reciente, sino el tipo de tarea.
Una forma útil de pensarlo es esta:
- Si necesitas un modelo generalista para trabajo importante, usa
gpt-5.4. - Si buscas equilibrio entre capacidad, latencia y coste, usa
gpt-5.4-mini. - Si el caso es masivo y sencillo, usa
gpt-5.4-nano. - Si necesitas razonamiento más profundo, valora si compensa subir a
gpt-5.4-pro. - Si el problema es especialmente difícil y el coste importa menos, valora
gpt-5.4-pro.
def seleccionar_modelo(tipo_tarea: str) -> str:
if tipo_tarea == "analisis_profundo":
return "gpt-5.4-pro"
if tipo_tarea == "chat_coste_equilibrado":
return "gpt-5.4-mini"
if tipo_tarea == "clasificacion_masiva":
return "gpt-5.4-nano"
return "gpt-5.4"
Elegir bien el modelo suele dar más resultado que tocar diez parámetros al azar.
Alias y snapshots
Un alias como gpt-5.4 apunta a la referencia recomendada de una familia. Un snapshot fija una versión concreta para que tu aplicación sea reproducible.
# Alias: cómodo para desarrollo y pruebas
response = client.responses.create(
model="gpt-5.4",
input="Resume este documento."
)
# Snapshot: preferible cuando necesitas estabilidad estricta
response = client.responses.create(
model="gpt-5.4-2026-02-15",
input="Resume este documento."
)
Usar snapshots tiene sentido cuando el comportamiento debe permanecer estable en producción. Si empleas un alias genérico, OpenAI puede redirigirlo a una versión más reciente de la misma familia y eso puede cambiar matices de salida, formato o rendimiento.
Por eso, cuando una aplicación depende de respuestas previsibles, conviene documentar la decisión del modelo y fijar snapshots en los flujos críticos.
Fuentes y referencias
Documentación oficial y recursos externos para profundizar en OpenAI SDK
Documentación oficial de OpenAI SDK
Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, OpenAI SDK es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de OpenAI SDK
Explora más contenido relacionado con OpenAI SDK y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Conocer las principales familias de modelos de OpenAI y sus características. Diferenciar entre modelos de propósito general y modelos especializados en razonamiento. Comprender cómo seleccionar un modelo según la naturaleza y complejidad de la tarea. Evaluar la importancia de la velocidad, coste y precisión en la elección del modelo. Aplicar estrategias prácticas para optimizar recursos combinando diferentes modelos.