Qué es la IA Generativa
La IA generativa es una rama de la inteligencia artificial que se centra en crear contenido nuevo a partir de datos de entrada, en lugar de limitarse a clasificarlos o evaluarlos. Estos modelos aprenden patrones a gran escala a partir de grandes volúmenes de texto, imágenes o audio, y después son capaces de producir ejemplos que siguen esos mismos patrones sin copiarlos literalmente.
A diferencia de muchos sistemas de IA tradicionales, que responden con una etiqueta o un número (por ejemplo, "spam" o "no spam"), la IA generativa produce salidas estructuradas como párrafos de texto, fragmentos de código o descripciones de imágenes. La clave está en que el modelo ha aprendido cómo suele "continuar" la información en el mundo real y utiliza ese conocimiento para generar contenido nuevo.
En el caso del lenguaje natural, el flujo es siempre parecido: damos un texto de entrada (el prompt) y el modelo lo completa palabra a palabra, o más exactamente token a token. Internamente, cada token se convierte en números, se procesa con una red neuronal y se transforma de nuevo en texto legible.
Un resumen visual de este proceso puede verse así:
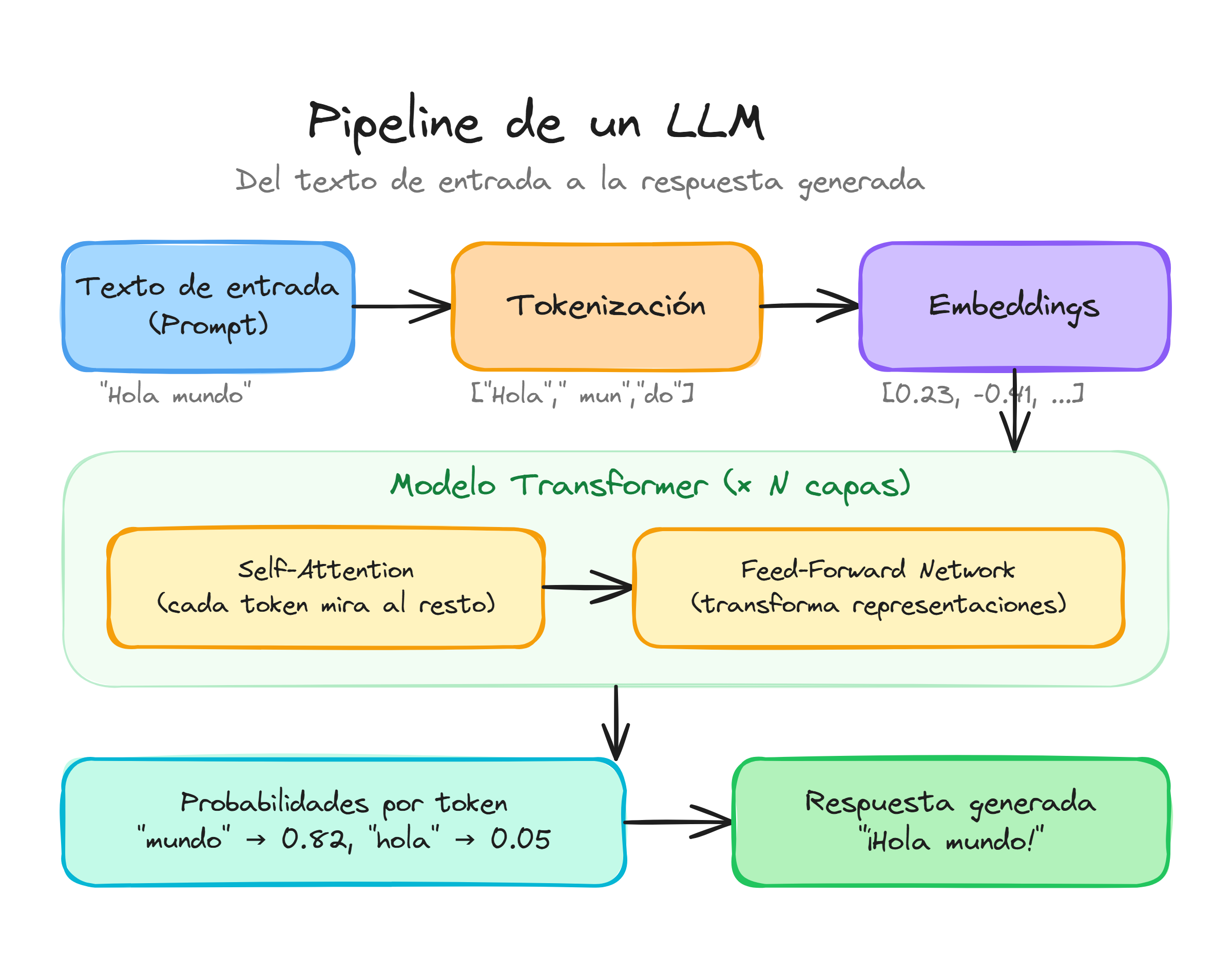
En este curso trabajaremos con modelos de texto ya entrenados, a los que accederemos mediante el SDK de Python de OpenAI. Desde el punto de vista de nuestra aplicación, estos modelos son una especie de "motor de redacción" al que enviamos un prompt y del que recibimos una respuesta generada.
Si pensamos en un caso sencillo, como redactar una respuesta a un correo, nuestra aplicación no "inventa" las frases por sí misma, sino que delega en un modelo generativo. A nivel muy simplificado, podríamos expresarlo en Python de esta forma:
def modelo_generativo(prompt: str) -> str:
# En un caso real aquí se llamaría a un modelo de IA generativa (por ejemplo, vía API).
return f"[texto generado a partir de: {prompt}]"
respuesta = modelo_generativo("Redacta una respuesta amable a este correo.")
print(respuesta)
Este fragmento no implementa ninguna red neuronal, pero resume la idea clave: la lógica de nuestra aplicación construye un prompt, lo envía a un modelo generativo y utiliza la salida para resolver un problema concreto. A lo largo del curso nos centraremos en cómo diseñar buenos prompts y cómo integrar estas respuestas en programas reales en Python.
La IA generativa no se limita a recuperar ejemplos del conjunto de datos, sino que aprende una distribución estadística sobre cómo suelen aparecer las palabras, expresiones y estructuras. A partir de esa distribución, el modelo combina tokens para producir respuestas plausibles en función de lo que ha visto durante su entrenamiento y de lo que le pedimos en cada llamada.
Una forma intuitiva de imaginarlo es pensar en un modelo que ha leído millones de textos y ha interiorizado patrones sobre qué palabras suelen seguir a otras en distintos contextos. Cuando le damos un prompt, el modelo intenta continuar ese texto de manera coherente con esos patrones aprendidos, ajustándose al estilo, tono y nivel de detalle que inducen nuestras instrucciones.
Qué es un LLM
Un LLM (Large Language Model o modelo de lenguaje de gran tamaño) es un tipo específico de modelo de IA generativa entrenado para trabajar con texto. Su tarea fundamental es sencilla de describir: dada una secuencia de tokens de entrada, el modelo calcula cuál es el siguiente token más probable, y repitiendo esta operación muchas veces se obtienen frases y párrafos completos.
Cuando hablamos de "gran tamaño" en un LLM nos referimos, sobre todo, a:
-
1. Número de parámetros: la cantidad de pesos internos de la red neuronal que se ajustan durante el entrenamiento.
-
2. Volumen de datos: la cantidad de texto sobre la que se ha entrenado el modelo.
-
3. Vocabulario interno: el número de tokens distintos que el modelo es capaz de manejar.
Esta escala permite que el modelo capture matices finos del lenguaje natural, como diferencias de significado, estructuras gramaticales complejas o variaciones de estilo. Cuanto más rico es el entrenamiento, más flexibles y matizadas pueden ser las respuestas que produce el modelo.
Un LLM no opera directamente con caracteres ni con palabras completas, sino con tokens, que son unidades mínimas de texto: pueden ser palabras, fragmentos de palabra o signos de puntuación. Cada token se transforma en un vector de números (una embedding), lo que permite al modelo tratar el lenguaje como puntos en un espacio matemático donde frases parecidas tienen representaciones cercanas.
Podemos esquematizar esta idea así:
Texto de entrada
↓
[ Tokenización ]
↓
Tokens: [t1, t2, t3, ...]
↓
[ Embeddings ]
↓
Vectores: [v1, v2, v3, ...]
↓
[ Modelo LLM ]
↓
Probabilidades para el siguiente token
De manera muy simplificada, un LLM puede verse como una función que, para un contexto dado, devuelve una distribución de probabilidades sobre todos los posibles tokens siguientes. El modelo no elige manualmente una palabra, sino que asigna un peso a cada opción y, a partir de esos pesos, el sistema de generación decide qué token usar.
En un LLM real, el vocabulario contiene miles de tokens y las probabilidades se calcularían tras pasar por muchas capas de cómputo. Sin embargo, el concepto es el mismo: el modelo sugiere qué token encaja mejor a continuación y un algoritmo de decodificación (por ejemplo, greedy, muestreo, top-k, etc.) selecciona el siguiente token en función de esa distribución.
Repitiendo este proceso token a token, el modelo genera secuencias que mantienen la coherencia con el contexto inicial y con las instrucciones que hemos dado en el prompt. Cuando usemos el SDK de Python de OpenAI, nosotros solo veremos cadenas de texto, pero internamente el LLM estará realizando estas operaciones de probabilidad en cada paso de la generación.
Arquitectura transformer
La mayoría de los LLM actuales se basan en la arquitectura transformer, que resultó especialmente eficaz para trabajar con secuencias de texto largas. En lugar de procesar las palabras una a una en orden estricto, un transformer procesa todos los tokens de una secuencia en paralelo y decide de forma explícita qué partes del contexto son más relevantes en cada momento.
El recorrido interno, de forma simplificada, se puede describir así: los tokens se convierten en vectores mediante una capa de embedding, se les añade información de posición para indicar su lugar en la frase, y después atraviesan varios bloques formados por capas de autoatención y redes neuronales densas. Cada bloque refina la representación interna del texto y le permite al modelo capturar relaciones más complejas.
Un diagrama conceptual puede ayudar a visualizarlo:
Tokens de entrada
↓
[ Embeddings + codificación posicional ]
↓
+------------------------------+
| Bloque Transformer 1 |
| (self-attention + FFN) |
+------------------------------+
↓
+------------------------------+
| Bloque Transformer 2 |
| (self-attention + FFN) |
+------------------------------+
↓
...
↓
+------------------------------+
| Bloque Transformer N |
+------------------------------+
↓
[ Capa de salida ]
↓
Logits → Probabilidades por token
El mecanismo de autoatención (self-attention) permite que cada token "mire" al resto de tokens de la secuencia y asigne un peso a la información de cada uno. De este modo, el modelo puede relacionar palabras que están lejos en la frase, como sujeto y verbo, o una explicación y su consecuencia.
Podemos imaginar esta dinámica con un esquema reducido:
Tokens: [ "modelo", "respondió", "porque", "entendió", "contexto" ]
Autoatención (vista simplificada):
- "porque" presta alta atención a "respondió" y "entendió"
- "contexto" presta atención a "entendió"
- "modelo" presta atención a "respondió"
En la fase de generación, el modelo se invoca de forma iterativa: se le pasa el texto ya generado, procesa la secuencia con sus bloques transformer y devuelve las probabilidades para el siguiente token.
Un bucle muy simplificado que ilustra esta idea podría ser:
def modelo_transformer(tokens):
# Simulación: devolvemos probabilidades ficticias para el ejemplo
return [0.1, 0.7, 0.2] # Tres posibles tokens
def generar_secuencia(num_tokens: int) -> list[int]:
secuencia: list[int] = []
for _ in range(num_tokens):
probs = modelo_transformer(secuencia)
siguiente = max(range(len(probs)), key=lambda i: probs[i]) # decodificación greedy
secuencia.append(siguiente)
return secuencia
Gracias a esta arquitectura, un LLM puede aprovechar un contexto relativamente amplio (la llamada ventana de contexto) y producir respuestas que no solo son correctas palabra a palabra, sino que mantienen una línea argumental consistente.
Entender que detrás de una simple llamada al SDK hay un transformer que aplica autoatención y operaciones matriciales sobre tokens nos ayudará a razonar mejor sobre cómo formular prompts efectivos y cómo interpretar las respuestas a lo largo del curso.

Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, OpenAI SDK es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de OpenAI SDK
Explora más contenido relacionado con OpenAI SDK y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Comprender qué es la IA generativa y cómo produce contenido nuevo a partir de patrones aprendidos. Entender el concepto de LLM, sus parámetros clave y el proceso de generación token a token. Conocer el papel de los tokens, embeddings y distribuciones de probabilidad en la generación de texto. Identificar los componentes principales de la arquitectura transformer y el mecanismo de autoatención. Relacionar estos fundamentos con el uso práctico de prompts y el SDK de Python de OpenAI.
Cursos que incluyen esta lección
Esta lección forma parte de los siguientes cursos estructurados con rutas de aprendizaje