Crear imagen
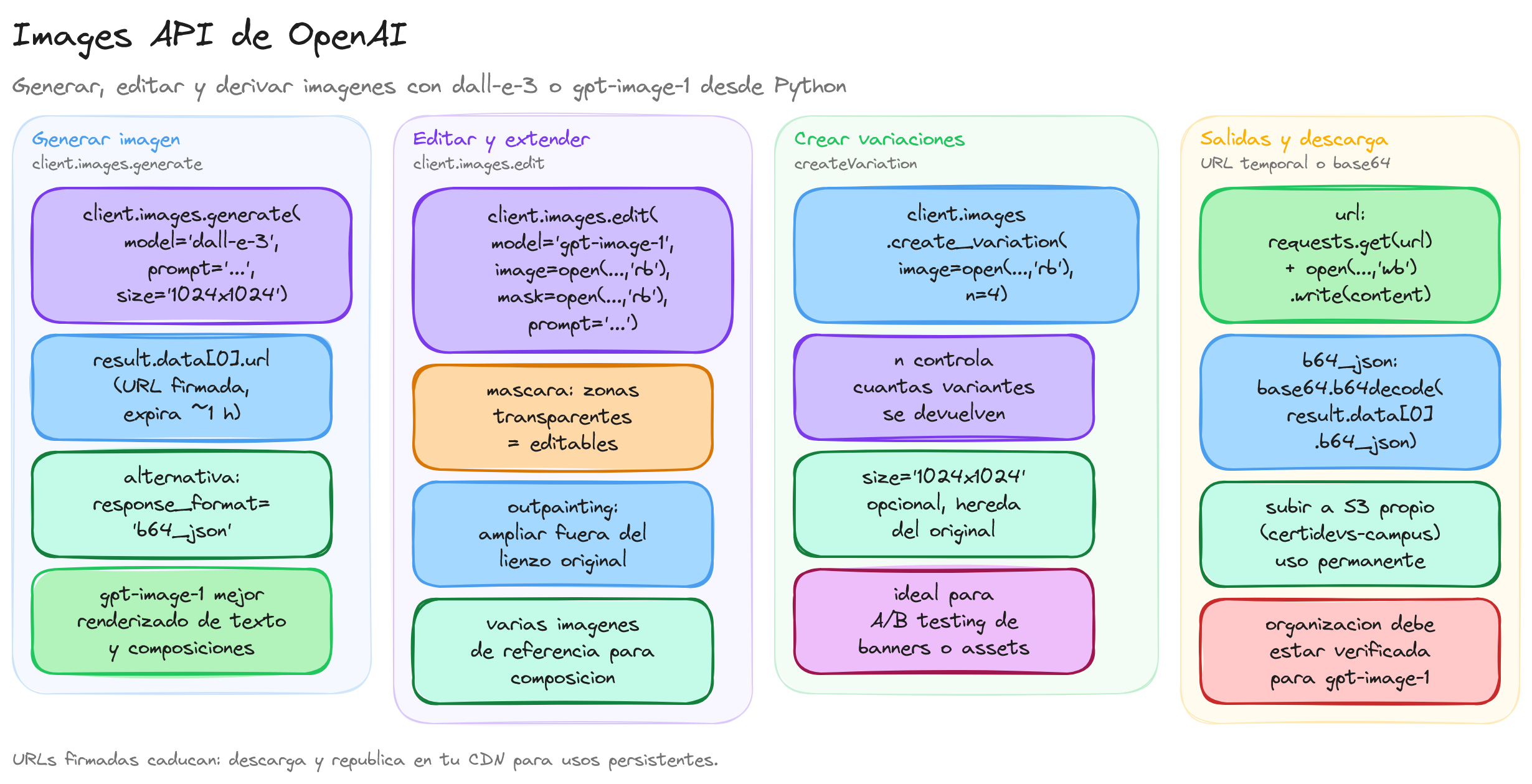
La API de imágenes de OpenAI permite generar ilustraciones, fotografías sintéticas y gráficos a partir de descripciones en lenguaje natural, utilizando el modelo gpt-image-1.
Este modelo interpreta el texto del prompt y produce una imagen coherente con la descripción, lo que resulta especialmente útil para prototipado rápido, materiales de marketing o recursos visuales internos.
La referencia oficial de este endpoint se encuentra en la documentación de creación de imágenes.
A grandes rasgos, el flujo consiste en preparar el entorno, redactar un prompt claro y realizar la llamada images.generate para obtener la imagen en formato base64 o como URL.
Para poder utilizar gpt-image-1 desde la API es necesario que la organización de OpenAI esté verificada; si tu cuenta no está verificada, el modelo no aparecerá disponible en la configuración ni en las llamadas a la API. El proceso de verificación se realiza desde la sección de configuración de la organización en la consola de OpenAI y requiere un documento de identificación válido.
Ejemplo de generación de una sola imagen a partir de un prompt:
from openai import OpenAI
client = OpenAI()
result = client.images.generate(
model="dall-e-3",
prompt="Catedral de León España",
size="1024x1024"
)
print(result.data[0].url) # genera una url que podemos descargar
Como alternativa, se puede descargar:
import requests
img = client.images.generate(
model="dall-e-3",
prompt="Catedral de León España",
size="1024x1024"
)
url = img.data[0].url
response = requests.get(url)
with open("output.png", "wb") as f:
f.write(response.content)
Editar / extender imagen
Además de generar imágenes desde cero, la API permite editar y extender imágenes existentes, lo que resulta útil cuando ya tenemos material gráfico y solo queremos ajustar ciertos elementos. La edición se basa en proporcionar una o varias imágenes de entrada, opcionalmente una máscara, y un prompt que explique qué debe cambiar el modelo.
La referencia oficial está disponible en la documentación de edición de imágenes. El flujo típico consiste en subir la imagen original, definir las zonas editables mediante una máscara (donde las zonas transparentes indican qué se puede modificar) y describir el cambio deseado en el prompt.
Supongamos el problema de añadir un logotipo a una fotografía de producto sin tener que rehacer la sesión de fotos. Una solución habitual con la API es crear una máscara que deje transparente la esquina donde irá el logotipo y pedir al modelo que lo integre respetando la estética del resto de la imagen.
import base64
from openai import OpenAI
client = OpenAI()
result = client.images.edit(
model="gpt-image-1",
image=open("producto_original.png", "rb"), # Imagen base
mask=open("mascara_logo.png", "rb"), # Zonas transparentes = zonas editables
prompt="Añade el logotipo de la marca en la esquina superior derecha, estilo limpio y discreto"
)
edited_base64 = result.data[0].b64_json
edited_bytes = base64.b64decode(edited_base64)
with open("producto_con_logo.png", "wb") as f:
f.write(edited_bytes)
En este caso el comportamiento clave del modelo es que respeta la parte opaca de la máscara y solo pinta en las zonas transparentes, manteniendo el resto de la fotografía intacta. Este patrón se puede reutilizar para muchos otros casos: cambiar un fondo, sustituir un objeto por otro, o completar zonas recortadas al extender un lienzo horizontal o verticalmente (lo que suele llamarse outpainting).
El endpoint de edición también permite usar varias imágenes de referencia para construir una escena compuesta. Por ejemplo, se puede pasar una lista de fotografías de productos y pedir al modelo que genere una imagen promocional que los incluya todos en una misma composición, indicando en el prompt el estilo y el encuadre deseados.
Crear variaciones
Cuando la imagen original ya es útil, pero necesitas diferentes versiones con pequeñas variaciones de estilo, color o composición, la API ofrece el endpoint de variaciones. A diferencia de la edición, aquí no se específica una máscara ni un cambio concreto, sino que se piden alternativas coherentes con la imagen de entrada.
La referencia se encuentra en la documentación de variaciones de imágenes. El patrón de uso es sencillo: se envía la imagen base, se indica cuántas variaciones se desean con n y se fijan parámetros como size para controlar la resolución de salida.
Imaginemos el problema de disponer de un único logotipo cuadrado y necesitar varias versiones ligeramente distintas para probar en una interfaz. Una solución efectiva es generar varias variaciones automáticas y seleccionar después las que mejor encajen con la identidad visual.
import base64
from openai import OpenAI
client = OpenAI()
result = client.images.create_variation(
model="gpt-image-1",
image=open("logo_original.png", "rb"),
n=3, # Número de variaciones
size="512x512" # Resolución de salida
)
for i, image in enumerate(result.data, start=1):
image_bytes = base64.b64decode(image.b64_json)
with open(f"logo_variacion_{i}.png", "wb") as f:
f.write(image_bytes)
En la práctica, todas las variaciones preservan la esencia de la imagen de origen (forma general, composición básica), pero el modelo introduce cambios sutiles en color, textura o detalles decorativos. Este enfoque facilita experimentar rápidamente con distintas opciones visuales sin necesidad de encargar múltiples propuestas manuales a un equipo de diseño, manteniendo siempre el control sobre cuántas imágenes se generan y con qué resolución.
Fuentes y referencias
Documentación oficial y recursos externos para profundizar en OpenAI SDK
Documentación oficial de OpenAI SDK
Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, OpenAI SDK es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de OpenAI SDK
Explora más contenido relacionado con OpenAI SDK y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Comprender las capacidades principales de la Images API: generación, análisis y edición de imágenes. Conocer la estructura modular de la API y cómo acceder a sus funcionalidades desde Python. Entender la integración de la Images API con otras APIs de OpenAI para procesamiento multimodal. Familiarizarse con los formatos de entrada y salida soportados y la configuración de parámetros. Reconocer los mecanismos de gestión de recursos y patrones de uso comunes para aplicaciones visuales escalables.