Qué es Hugging Face
Hugging Face es una plataforma centrada en el intercambio de modelos de inteligencia artificial, especialmente modelos de lenguaje natural, visión y audio. Su ecosistema combina un enorme repositorio de modelos abiertos con servicios de inferencia en la nube, lo que permite integrar modelos de proveedores muy distintos desde una única interfaz.
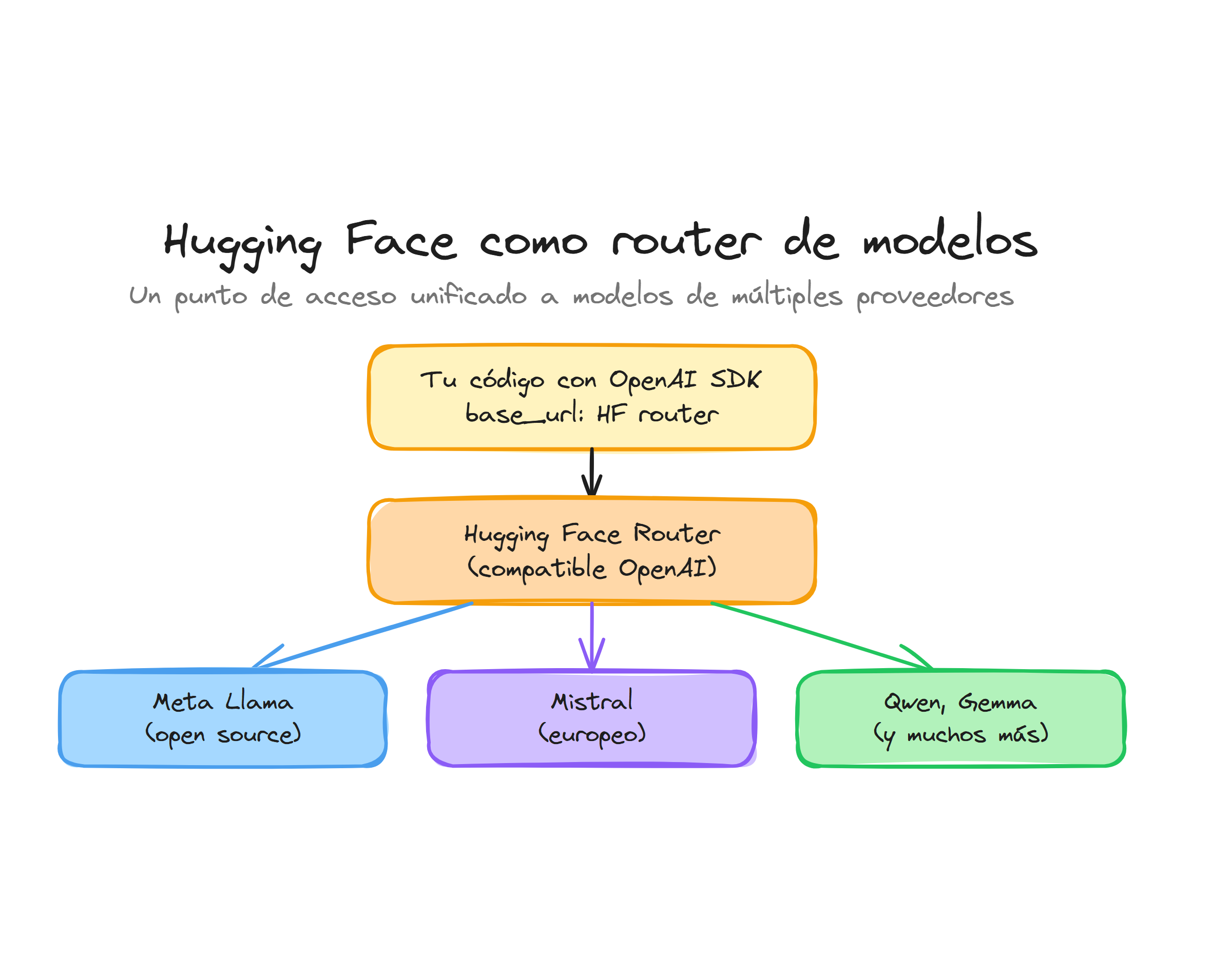
Para este curso nos interesa especialmente la compatibilidad de Hugging Face con la API de estilo OpenAI, que te permite consumir ciertos modelos a través de un endpoint v1 con la misma interfaz de chat.completions.create. De esta forma puedes alternar entre modelos alojados en Hugging Face y modelos de OpenAI o de otros proveedores casi sin cambiar tu código.
Invocar modelos de Hugging Face
Cuando usas Hugging Face como “router” de modelos, en lugar de llamar directamente a la API de OpenAI llamas al endpoint de Hugging Face configurado para exponer una API compatible con OpenAI. El parámetro model identifica tanto el modelo como el proveedor que lo sirve (por ejemplo, Nebius o Groq), y la autenticación se realiza con un token de Hugging Face.
Requisitos previos
Antes de poder invocar modelos desde código Python necesitas cumplir estos pasos:
-
1. Crear una cuenta y un token en Hugging Face: en tu perfil de Hugging Face debes generar un Access Token con permisos de uso de inferencia, que será el valor que guardarás en la variable de entorno
HF_TOKEN. -
2. Instalar el SDK de OpenAI: igual que en el resto del curso, necesitas el paquete
openaiinstalado para poder usar la interfaz deOpenAIdesde Python. -
3. Localizar modelos compatibles: no todos los modelos del Hub son accesibles mediante la API compatible con OpenAI, por lo que conviene revisar la sección de modelos de inferencia en Hugging Face Inference Models y filtrar por providers que ofrezcan endpoint OpenAI-like.
Configurar el cliente para el router de Hugging Face
La configuración básica consiste en crear un cliente OpenAI que utilice el token de Hugging Face y apunte al router https://router.huggingface.co/v1, en lugar del endpoint de OpenAI. Esta configuración es muy similar a la que usarías con cualquier otro proveedor compatible.
Problema: quieres reutilizar tu código que ya usa el cliente de OpenAI, pero que las peticiones se resuelvan con modelos alojados en Hugging Face.
Solución: cambiar la API key y el base_url del cliente, manteniendo intacta la lógica de negocio.
import os
from openai import OpenAI
# HF_TOKEN debe contener un token de acceso de Hugging Face con permisos de inferencia
client = OpenAI(
api_key=os.getenv("HF_TOKEN"),
base_url="https://router.huggingface.co/v1",
)
Con este cliente, todas las llamadas que hagas a chat.completions.create saldrán hacia el router de Hugging Face, que se encargará de enrutar la petición al modelo que hayas elegido en el parámetro model.
Ejemplo de llamada a modelos servidos por distintos providers
Una de las ventajas de este enfoque es que puedes cambiar de proveedor y de modelo modificando solo el nombre del modelo, sin tocar el resto del código. En el siguiente ejemplo se llaman dos modelos distintos que se sirven desde proveedores diferentes pero comparten la misma interfaz compatible con OpenAI.
Problema: quieres comparar rápidamente la respuesta de dos modelos diferentes ante el mismo prompt sin reescribir tu integración.
Solución: mantener el mismo cliente y cambiar únicamente el nombre del modelo en cada llamada.
response = client.chat.completions.create(
model="google/gemma-2-2b-it:nebius",
messages=[{"role": "user", "content": "Indica cuántas r tiene la palabra strawberry."}],
)
print("Gemma (Nebius):", response.choices[0].message.content)
response = client.chat.completions.create(
model="openai/gpt-oss-20b:groq",
messages=[{"role": "user", "content": "Indica cuántas r tiene la palabra strawberry."}],
)
print("GPT-OSS (Groq):", response.choices[0].message.content)
En este caso la estructura de la llamada es idéntica en ambos casos, pero cambias el modelo entre google/gemma-2-2b-it:nebius y openai/gpt-oss-20b:groq, lo que te permite evaluar rápidamente cuál se adapta mejor a tu caso de uso concreto.
Patrón de utilidad para centralizar el acceso a Hugging Face
Para proyectos algo más grandes es recomendable encapsular la creación del cliente y la llamada al modelo en una función de ayuda, evitando que cada módulo tenga que preocuparse por tokens, endpoints o nombres de modelos.
Problema: el código de configuración del cliente se repite en varios archivos y dificulta mantener las credenciales y la URL de Hugging Face en un único punto.
Solución: crear utilidades que creen el cliente y ejecuten una llamada de chat devolviendo solo el texto resultante.
import os
from openai import OpenAI
def create_hf_client() -> OpenAI:
"""Crea un cliente OpenAI apuntando al router de Hugging Face."""
return OpenAI(
api_key=os.getenv("HF_TOKEN"),
base_url="https://router.huggingface.co/v1",
)
def chat_with_hf_model(model: str, user_message: str) -> str:
"""Envía un mensaje a un modelo de Hugging Face y devuelve solo el contenido de la respuesta."""
client = create_hf_client()
response = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": "Eres un asistente especializado en Python."},
{"role": "user", "content": user_message},
],
max_tokens=256,
temperature=0.2,
)
return response.choices[0].message.content
if __name__ == "__main__":
text = chat_with_hf_model(
model="google/gemma-2-2b-it:nebius",
user_message="Resume en una frase qué es una lista por comprensión en Python.",
)
print(text)
Con este enfoque concentras toda la lógica específica de Hugging Face en un solo módulo, lo que facilita cambiar de modelo, rotar tokens o incluso sustituir el router por otro proveedor compatible con la API de OpenAI sin modificar el resto de la aplicación.

Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, OpenAI SDK es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de OpenAI SDK
Explora más contenido relacionado con OpenAI SDK y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Entender que es Hugging Face y su compatibilidad con la API de estilo OpenAI. Configurar el cliente OpenAI apuntando al router de Hugging Face con HF_TOKEN y base_url. Invocar modelos de distintos proveedores (Nebius, Groq) cambiando solo el parámetro model. Encapsular la configuración y las llamadas en funciones de utilidad reutilizables. Localizar modelos compatibles con la API OpenAI-like en la plataforma de Hugging Face.
Cursos que incluyen esta lección
Esta lección forma parte de los siguientes cursos estructurados con rutas de aprendizaje