Optimización de costes con Flex processing
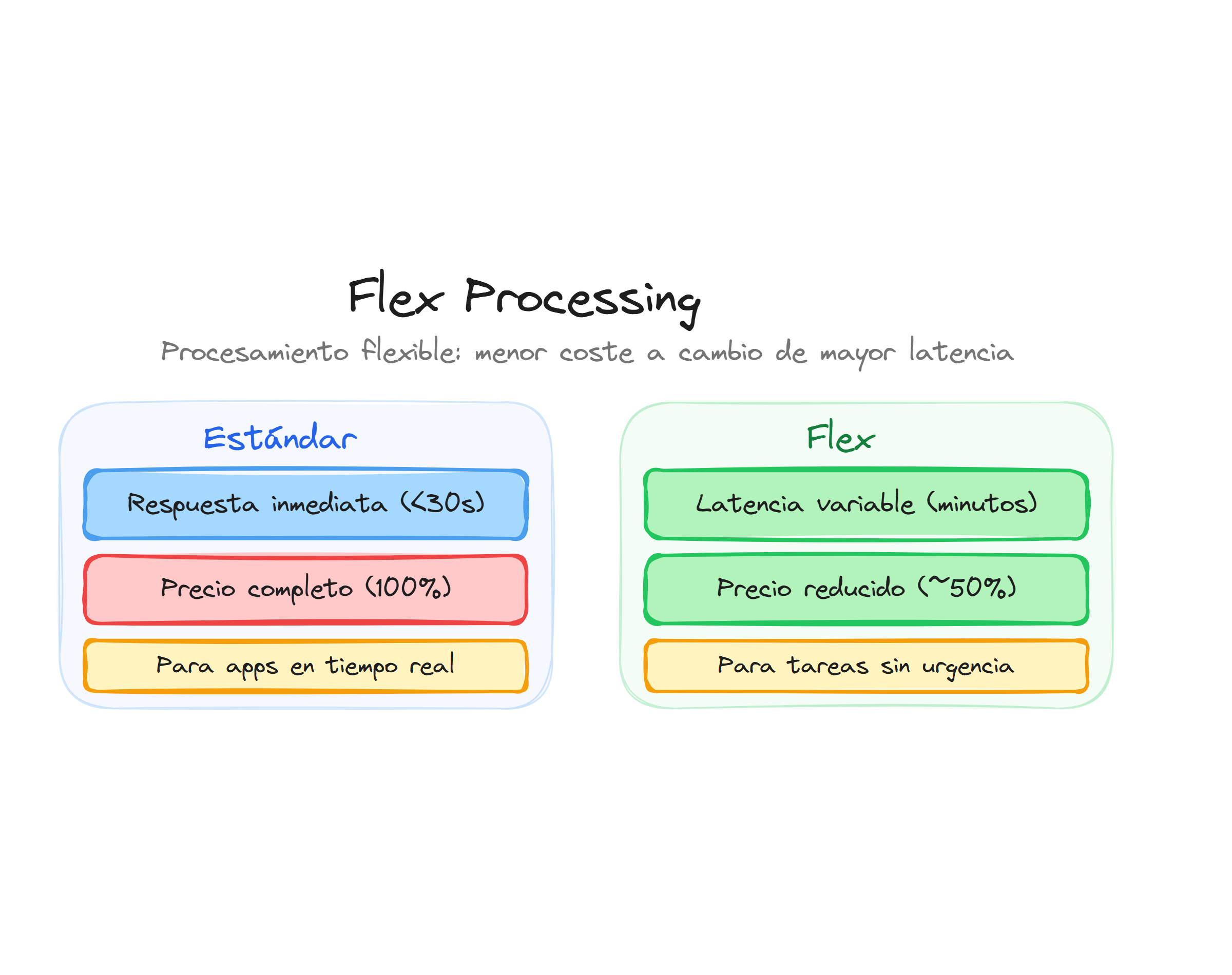
Flex processing es una opción de procesamiento flexible que OpenAI ofrece en su API para reducir costes en cargas de trabajo no urgentes. En lugar de memorizar una lista cerrada de modelos compatibles, conviene revisar la página de pricing y compatibilidad vigente antes de desplegarlo, porque tanto el soporte como las tarifas pueden cambiar con el tiempo.
La principal ventaja de Flex processing es que utiliza la misma interfaz de API que el procesamiento estándar, lo que significa que puedes trabajar con las API Responses o Chat Completions de forma habitual, simplemente añadiendo un parámetro adicional para activar el modo flexible.
Casos de uso recomendados
Flex processing está diseñado específicamente para tareas no críticas en tiempo real y cargas de trabajo asíncronas. Los escenarios más apropiados incluyen:
- Evaluaciones de modelos: cuando necesitas ejecutar conjuntos de pruebas para evaluar el rendimiento de tus prompts o flujos de trabajo
- Enriquecimiento de datos: procesos de etiquetado, clasificación o análisis de grandes volúmenes de datos donde el tiempo no es crítico
- Tareas de fondo: trabajos que pueden ejecutarse en segundo plano sin necesidad de respuesta inmediata
- Entornos no productivos: desarrollo, testing o experimentación donde la latencia no afecta a usuarios finales
Por el contrario, no debes usar Flex processing para aplicaciones interactivas, chatbots en tiempo real o cualquier caso donde la experiencia de usuario dependa de respuestas rápidas.
Diferencias con Batch API
Aunque tanto Batch API como Flex processing ofrecen un descuento del 50%, existen diferencias importantes entre ambas opciones:
Batch API procesa múltiples peticiones agrupadas en un archivo .jsonl con un tiempo de entrega de hasta 24 horas. Es ideal para procesar grandes volúmenes de peticiones de una vez, pero requiere preparar un archivo de entrada específico y esperar a que se complete todo el lote.
Flex processing, en cambio, funciona petición a petición usando la API estándar. Puedes enviar una sola petición con service_tier="flex" y recibir la respuesta cuando esté lista, sin necesidad de agrupar múltiples peticiones ni esperar 24 horas. La respuesta suele llegar en minutos, aunque puede tardar más que el modo estándar.
Activación de Flex processing
Para activar Flex processing, simplemente añade el parámetro service_tier con el valor "flex" en tu petición. Este parámetro funciona tanto con la API Responses como con Chat Completions.
Ejemplo con API Responses:
from openai import OpenAI
client = OpenAI(
timeout=900.0 # 15 minutos
)
response = client.responses.create(
model="gpt-5.4", # O el modelo compatible con Flex que indique la documentación actual
input="Analiza las tendencias de este conjunto de datos de ventas...",
service_tier="flex"
)
print(response.output_text)
Ejemplo con Chat Completions:
import OpenAI from "openai";
const client = new OpenAI({
timeout: 15 * 1000 * 60 // 15 minutos
});
const response = await client.chat.completions.create({
model: "gpt-5.4",
messages: [{
role: "user",
content: "Clasifica estos comentarios de usuarios..."
}],
service_tier: "flex"
});
console.log(response.choices[0].message.content);
Estructura de precios
La reducción de costes con Flex processing puede ser significativa, pero las tarifas exactas dependen del modelo y del momento. Por eso, en materiales evergreen es mejor evitar tablas fijas y consultar siempre la pricing page antes de estimar costes o diseñar una arquitectura alrededor de un porcentaje concreto de ahorro.
Gestión de timeouts
Uno de los aspectos más importantes al usar Flex processing es configurar correctamente los timeouts. Debido a que las peticiones Flex tienen menor prioridad en la cola de procesamiento, es más probable que excedan el timeout por defecto de 10 minutos del SDK.
Configuración de timeout en Python:
from openai import OpenAI
# Configuración global del cliente
client = OpenAI(timeout=900.0)
# O configuración por petición
response = client.with_options(timeout=900.0).responses.create(
model="gpt-5.4",
input="Prompt largo que requiere procesamiento...",
service_tier="flex"
)
Configuración de timeout en JavaScript:
import OpenAI from "openai";
const client = new OpenAI({
timeout: 15 * 60 * 1000 // 15 minutos en milisegundos
});
// O por petición específica
const response = await client.responses.create({
model: "gpt-5.4",
input: "Análisis detallado...",
service_tier: "flex"
}, {
timeout: 15 * 60 * 1000
});
El SDK de OpenAI incluye reintentos automáticos para errores de timeout (código 408). Si una petición falla por timeout, el SDK reintentará automáticamente hasta dos veces antes de lanzar una excepción.
Manejo de errores de recursos no disponibles
Con Flex processing, puede ocurrir que los recursos del servidor no estén disponibles temporalmente, lo que resulta en un error 429 con el mensaje "Resource Unavailable". Cuando esto sucede, no se te cobra por la petición fallida.
Existen dos estrategias principales para manejar estos errores:
1 - Reintento con backoff exponencial:
import time
from openai import OpenAI, APIError
client = OpenAI()
def procesar_con_flex(prompt, max_reintentos=5):
espera = 1 # Segundo inicial de espera
for intento in range(max_reintentos):
try:
response = client.responses.create(
model="gpt-5.4",
input=prompt,
service_tier="flex",
timeout=900.0
)
return response.output_text
except APIError as e:
if e.status_code == 429 and intento < max_reintentos - 1:
print(f"Recursos no disponibles. Reintentando en {espera}s...")
time.sleep(espera)
espera *= 2 # Duplicar tiempo de espera
else:
raise
raise Exception("No se pudieron obtener recursos después de varios intentos")
2 - Fallback a procesamiento estándar:
from openai import OpenAI, APIError
client = OpenAI()
def procesar_con_fallback(prompt):
try:
# Intentar con Flex primero
response = client.responses.create(
model="gpt-5.4",
input=prompt,
service_tier="flex",
timeout=900.0
)
return response.output_text, "flex"
except APIError as e:
if e.status_code == 429:
# Si falla, usar modo estándar
print("Cambiando a modo estándar...")
response = client.responses.create(
model="gpt-5.4",
input=prompt,
service_tier="auto"
)
return response.output_text, "standard"
else:
raise
Estrategia de enrutamiento inteligente
Para optimizar costes manteniendo la fiabilidad, puedes implementar un sistema que decida automáticamente qué tipo de procesamiento usar según la urgencia de la tarea:
from openai import OpenAI
from enum import Enum
class PrioridadTarea(Enum):
BAJA = "flex"
MEDIA = "auto"
ALTA = "auto"
class EnrutadorIA:
def __init__(self):
self.client = OpenAI()
def procesar(self, prompt, prioridad=PrioridadTarea.BAJA):
config = {
"model": "gpt-5.4",
"input": prompt,
"service_tier": prioridad.value
}
if prioridad == PrioridadTarea.BAJA:
config["timeout"] = 900.0
try:
response = self.client.responses.create(**config)
return {
"resultado": response.output_text,
"tier_usado": prioridad.value,
"tokens": response.usage.total_tokens
}
except Exception as e:
if prioridad == PrioridadTarea.BAJA:
# Reintentar con prioridad media si Flex falla
return self.procesar(prompt, PrioridadTarea.MEDIA)
raise
# Uso del enrutador
enrutador = EnrutadorIA()
# Tarea no urgente - usar Flex
analisis_historico = enrutador.procesar(
"Analiza las tendencias de los últimos 5 años...",
prioridad=PrioridadTarea.BAJA
)
# Tarea interactiva - usar modo estándar
respuesta_chatbot = enrutador.procesar(
"Responde a la pregunta del usuario...",
prioridad=PrioridadTarea.ALTA
)
Monitorización de costes y rendimiento
Para aprovechar al máximo Flex processing, es recomendable implementar un sistema de seguimiento de métricas que te permita evaluar el ahorro real y los tiempos de respuesta:
from openai import OpenAI
import time
from dataclasses import dataclass
from typing import List
@dataclass
class MetricaPeticion:
modelo: str
tier: str
tokens_entrada: int
tokens_salida: int
tiempo_respuesta: float
coste_estimado: float
class MonitorCostes:
def __init__(self, precios_actuales):
self.client = OpenAI()
self.metricas: List[MetricaPeticion] = []
self.precios = precios_actuales
def procesar_con_metricas(self, modelo, prompt, tier="flex"):
inicio = time.time()
response = self.client.responses.create(
model=modelo,
input=prompt,
service_tier=tier,
timeout=900.0 if tier == "flex" else 600.0
)
tiempo_respuesta = time.time() - inicio
# Calcular coste
precio_entrada, precio_salida = self.precios[modelo][tier]
coste = (
(response.usage.input_tokens / 1_000_000) * precio_entrada +
(response.usage.output_tokens / 1_000_000) * precio_salida
)
# Guardar métrica
self.metricas.append(MetricaPeticion(
modelo=modelo,
tier=tier,
tokens_entrada=response.usage.input_tokens,
tokens_salida=response.usage.output_tokens,
tiempo_respuesta=tiempo_respuesta,
coste_estimado=coste
))
return response.output_text
def resumen_ahorro(self):
coste_flex = sum(m.coste_estimado for m in self.metricas if m.tier == "flex")
# Calcula el equivalente estándar usando tus tarifas vigentes.
coste_standard_equiv = sum(
(
(m.tokens_entrada / 1_000_000) * self.precios[m.modelo]["standard"][0] +
(m.tokens_salida / 1_000_000) * self.precios[m.modelo]["standard"][1]
)
for m in self.metricas if m.tier == "flex"
)
return {
"peticiones_flex": len([m for m in self.metricas if m.tier == "flex"]),
"coste_total_flex": round(coste_flex, 4),
"ahorro_estimado": round(coste_standard_equiv - coste_flex, 4),
"tiempo_medio_respuesta": round(
sum(m.tiempo_respuesta for m in self.metricas) / len(self.metricas), 2
)
}
Consideraciones de implementación
Al implementar Flex processing en tu aplicación, ten en cuenta estos aspectos:
- Separación de flujos: mantén separados los flujos críticos (que usan modo estándar) de los no críticos (que usan Flex)
- Feedback al usuario: si el usuario final podría notar la demora, informa que el procesamiento está en curso
- Batch vs Flex: si tienes más de 100 peticiones similares para procesar sin urgencia, considera usar Batch API en lugar de Flex
- Testing gradual: empieza usando Flex en una pequeña porción de tu tráfico no crítico antes de escalarlo
- Logs detallados: registra qué tier usa cada petición para análisis posterior de rendimiento y costes
Flex processing representa una opción valiosa para optimizar costes en aplicaciones de IA cuando la latencia no es un factor crítico. Al combinar esta funcionalidad con una estrategia de enrutamiento inteligente en tu cliente de Python y un buen manejo de errores, puedes reducir de forma consistente los gastos operativos sin comprometer la calidad del servicio en escenarios que realmente lo requieren.
Fuentes y referencias
Documentación oficial y recursos externos para profundizar en OpenAI SDK
Documentación oficial de OpenAI SDK
Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, OpenAI SDK es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de OpenAI SDK
Explora más contenido relacionado con OpenAI SDK y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Comprender qué es Flex processing y cómo reduce costes en el uso de modelos de IA. Identificar los casos de uso recomendados y cuándo no utilizar Flex processing. Aprender a activar y configurar Flex processing en las peticiones a la API. Conocer las diferencias entre Flex processing y Batch API. Implementar estrategias de manejo de errores, timeouts y enrutamiento inteligente para optimizar costes y rendimiento.