Analizar archivos subidos
Cuando hablamos de file inputs en OpenAI nos referimos a la capacidad de que un modelo lea directamente el contenido de un archivo (PDF, presentación, imagen escaneada, etc.) para responder preguntas muy específicas sobre él. En lugar de copiar y pegar texto en el prompt, el archivo se envía como entrada estructurada y el LLM se encarga de extraer tanto el texto como las imágenes relevantes.
Esta forma de trabajar es especialmente útil cuando queremos hacer preguntas puntuales sobre un documento concreto: revisar una cláusula de un contrato, localizar un fragmento de código en unos apuntes en PDF o verificar un cálculo dentro de un informe técnico. A diferencia de un sistema de RAG completo, aquí no construimos un índice de muchos documentos, sino que analizamos uno o varios archivos concretos de manera directa.
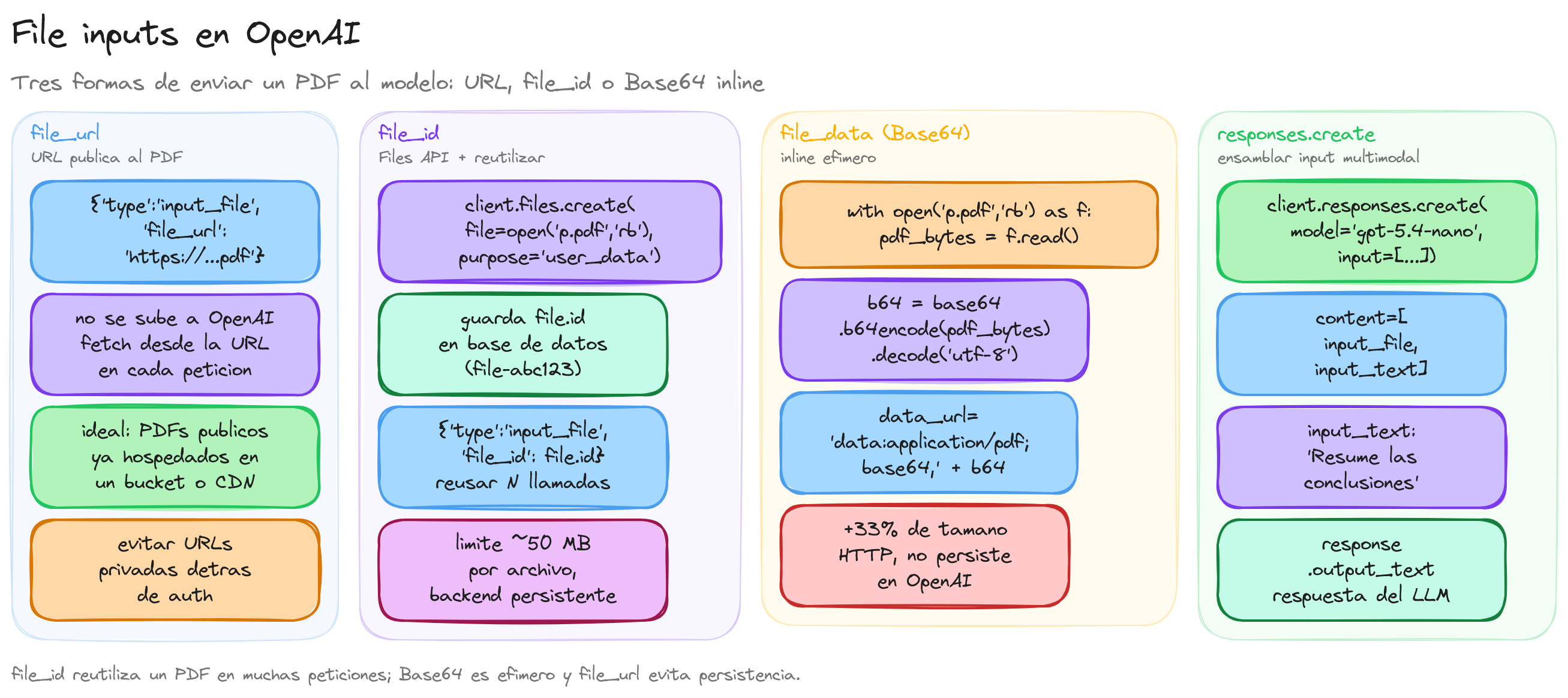
La documentación oficial de OpenAI plantea tres maneras principales de proporcionar un archivo al modelo:
- 1. URL de archivo (
file_url): el contenido se obtiene desde una URL pública que apunta al PDF o documento que queremos analizar, lo que resulta cómodo cuando el archivo ya está disponible en un servidor accesible. - 2. Archivo subido a la File API (
file_id): primero se sube el archivo con la File API y después se referencia su identificador en la llamada al modelo, lo que facilita la reutilización del mismo archivo en muchas peticiones. - 3. Archivo enviado en la propia petición (
file_data): el archivo se manda codificado (por ejemplo en Base64) dentro de la solicitud, algo útil cuando no queremos persistir el archivo en el almacenamiento de OpenAI.
En esta primera parte nos centraremos en la opción 2, que es la más habitual en aplicaciones de backend que necesitan volver a usar el mismo documento varias veces.
El flujo típico con archivos subidos es:
- 1. Subir el archivo con
client.files.create, indicando el propósitouser_data. - 2. Guardar el
file_idque devuelve la API para reutilizarlo en futuras llamadas. - 3. Hacer una llamada a
responses.create, combinando el archivo comoinput_filey el enunciado de la pregunta comoinput_text.
Un ejemplo completo de este patrón sería:
from openai import OpenAI
client = OpenAI()
# 1. Subimos el PDF una única vez a la File API
file = client.files.create(
file=open("pandas.pdf", "rb"),
purpose="user_data", # Indicamos que se usará como entrada para modelos
)
print(f"Archivo subido con ID: {file.id}")
# 2. Usamos el archivo en una llamada a Responses
response = client.responses.create(
model="gpt-5.4-nano",
input=[
{
"role": "user",
"content": [
{
"type": "input_file",
"file_id": file.id, # Referencia al archivo ya subido
},
{
"type": "input_text",
"text": "Indica cuál es el código que aparece en el segundo bloque de código de este documento PDF.",
},
],
}
],
)
print(response.output_text)
En este ejemplo el modelo recibe, en un mismo mensaje, tanto el archivo como la instrucción en texto. El bloque input_file le dice al modelo qué documento debe abrir y el bloque input_text define la tarea concreta que debe realizar sobre ese contenido.
En un entorno real es habitual subir el archivo una vez, almacenar el identificador en base de datos y reutilizarlo en múltiples consultas posteriores:
from openai import OpenAI
client = OpenAI()
file_id = "file_abc123" # Recuperado de tu base de datos
response = client.responses.create(
model="gpt-5.4-nano",
input=[
{
"role": "user",
"content": [
{
"type": "input_file",
"file_id": file_id,
},
{
"type": "input_text",
"text": "Resume en 5 puntos las conclusiones del documento.",
},
],
}
],
)
print(response.output_text)
Al trabajar con archivos subidos conviene tener en cuenta varias consideraciones prácticas:
- Tamaño máximo: cada archivo suele tener un límite aproximado de 50 MB, y la suma de todo el contenido enviado en una sola solicitud también está limitada; conviene revisar estos valores en la documentación oficial.
- Modelos compatibles: solo los modelos que aceptan texto e imagen pueden interpretar correctamente PDFs con gráficos o capturas.
- Coste en tokens: el modelo procesa el texto extraído y, en muchos casos, también las imágenes de las páginas, por lo que un informe muy largo puede consumir una cantidad significativa de tokens.
Analizar archivos en base64
Además de subir archivos a la File API, OpenAI permite enviar documentos directamente dentro de la propia petición, codificados en Base64. Esta opción es útil cuando queremos que el archivo sea efímero, por ejemplo en una aplicación web que recibe el PDF desde el navegador y no necesita almacenarlo en el servidor ni en el almacenamiento de OpenAI.
La idea es sencilla: se lee el archivo como bytes, se codifica en Base64 y se envía como un "data URL" mediante el campo file_data. El modelo recibe el contenido completo del documento en esa misma llamada y puede procesarlo igual que si se tratase de un archivo subido previamente.
Un ejemplo de uso con Base64 sería:
import base64
from openai import OpenAI
client = OpenAI()
# Leemos el PDF desde disco (también podría venir de una subida HTTP)
with open("pandas.pdf", "rb") as f:
pdf_bytes = f.read()
# Codificamos el contenido en Base64 y lo convertimos en data URL
base64_string = base64.b64encode(pdf_bytes).decode("utf-8")
data_url = f"data:application/pdf;base64,{base64_string}"
response = client.responses.create(
model="gpt-5.4-nano",
input=[
{
"role": "user",
"content": [
{
"type": "input_file",
"filename": "pandas.pdf",
"file_data": data_url,
},
{
"type": "input_text",
"text": "Indica cuál es el código que aparece en el segundo bloque de código de este documento PDF.",
},
],
}
],
)
print(response.output_text)
Este patrón es especialmente cómodo cuando el archivo solo se va a usar una vez y no necesitamos gestionar su ciclo de vida en la File API. El precio a pagar es que la petición HTTP puede ser significativamente más grande (la codificación Base64 aumenta el tamaño de los datos aproximadamente un 33 %), por lo que es recomendable limitar el tamaño máximo de archivo aceptado por la aplicación cliente.
En aplicaciones de backend es habitual combinar ambos enfoques: usar archivos subidos con file_id para documentos recurrentes y reservar el envío en Base64 para casos puntuales o flujos interactivos donde no tiene sentido persistir el archivo más allá de la propia petición.
Fuentes y referencias
Documentación oficial y recursos externos para profundizar en OpenAI SDK
Documentación oficial de OpenAI SDK
Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, OpenAI SDK es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de OpenAI SDK
Explora más contenido relacionado con OpenAI SDK y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Comprender el proceso de subida de archivos a la API Files de OpenAI. Aprender a manejar diferentes formatos de documentos compatibles. Saber listar y consultar el estado de los archivos subidos. Implementar manejo de errores y validaciones en la subida de archivos. Conocer cómo eliminar archivos para optimizar el almacenamiento y costes.