Qué son los embeddings y sus fundamentos
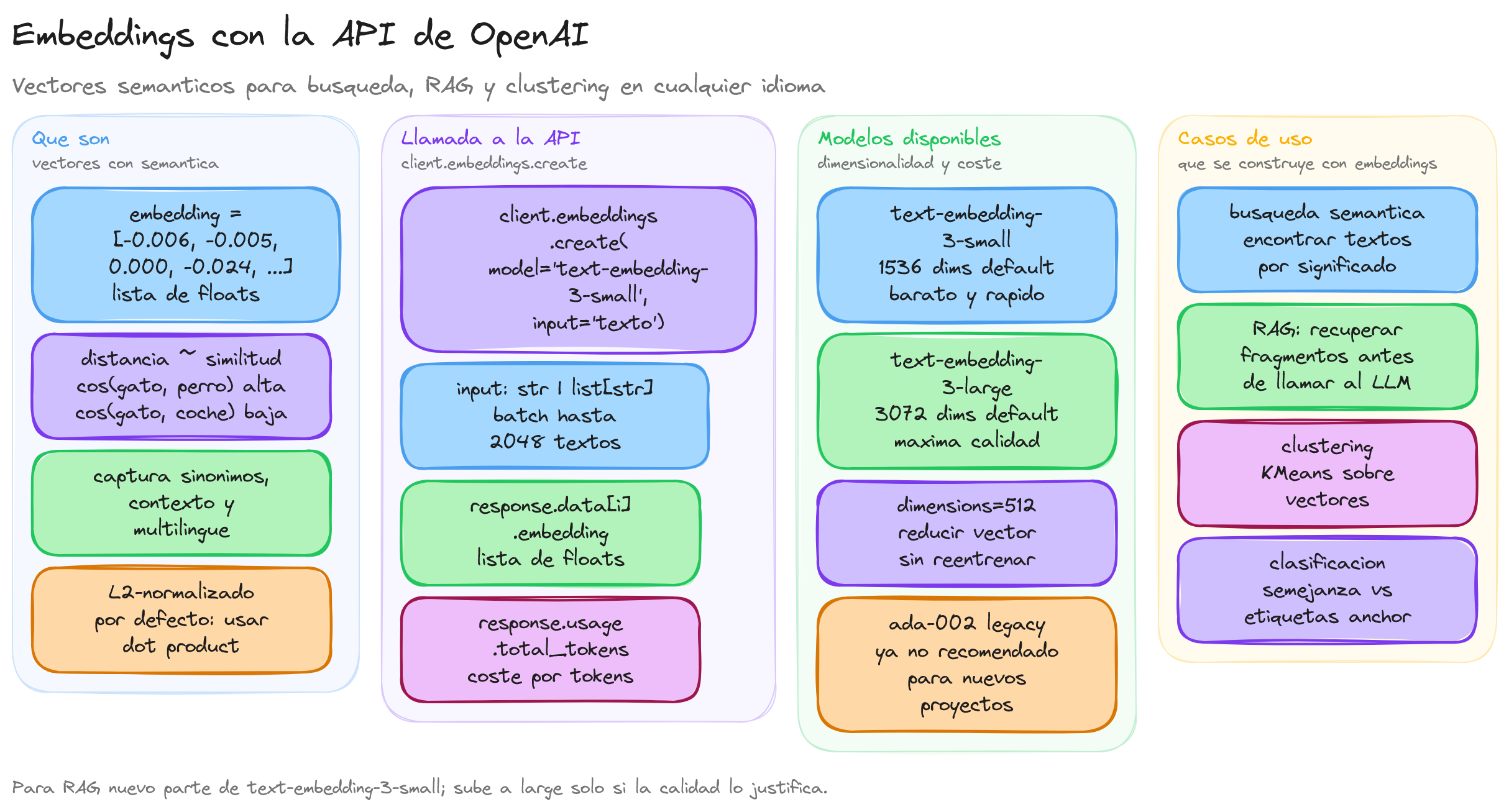
Los embeddings son representaciones numéricas de texto que capturan el significado semántico de las palabras, frases o documentos completos. En lugar de trabajar con texto plano, los embeddings convierten el lenguaje natural en vectores de números decimales que las máquinas pueden procesar y comparar matemáticamente.
Un embedding es esencialmente una lista de números decimales (vector) donde cada posición representa una característica semántica del texto original. Por ejemplo, el texto "El gato duerme en el sofá" se convierte en un vector como [-0.006929, -0.005336, 0.000045, -0.024047, ...] con cientos o miles de dimensiones.
Fundamentos matemáticos de los embeddings
La característica fundamental de los embeddings es que la distancia matemática entre vectores refleja la similitud semántica entre los textos originales. Dos conceptos relacionados tendrán embeddings con distancias pequeñas, mientras que conceptos no relacionados tendrán distancias grandes.
# Ejemplo conceptual de distancias entre embeddings
embedding_gato = [-0.1, 0.3, 0.8, -0.2]
embedding_perro = [-0.2, 0.4, 0.7, -0.1] # Similar a gato
embedding_coche = [0.9, -0.5, 0.1, 0.6] # Muy diferente
# La distancia entre gato y perro será menor que entre gato y coche
Esta propiedad permite realizar operaciones semánticas como encontrar textos similares, agrupar contenido relacionado o medir la relevancia de un documento respecto a una consulta.
Dimensionalidad y representación
Los embeddings modernos utilizan espacios vectoriales de alta dimensionalidad para capturar matices semánticos complejos. Los modelos de OpenAI generan embeddings con las siguientes características:
- text-embedding-3-small: 1536 dimensiones por defecto
- text-embedding-3-large: 3072 dimensiones por defecto
- Capacidad de reducción: Ambos modelos permiten especificar menos dimensiones sin perder propiedades semánticas significativas
# Estructura típica de un embedding
embedding_ejemplo = [
-0.006929283495992422,
-0.005336422007530928,
-4.547132266452536e-05,
-0.024047505110502243,
# ... continúa hasta 1536 o 3072 valores
]
Propiedades semánticas fundamentales
Los embeddings capturan relaciones semánticas complejas que van más allá de la coincidencia de palabras exactas. Estas propiedades incluyen:
Similitud conceptual: Palabras con significados relacionados tienen embeddings próximos, incluso si no comparten caracteres comunes. "Automóvil" y "vehículo" tendrán embeddings similares.
Contexto semántico: Los embeddings consideran el contexto completo del texto, no solo palabras individuales. "Banco" tendrá diferentes representaciones según se refiera a una institución financiera o a un asiento.
Invariancia lingüística: Los modelos modernos mantienen relaciones semánticas consistentes entre diferentes idiomas, permitiendo búsquedas y comparaciones multilingües.
Casos de uso fundamentales
Los embeddings habilitan múltiples aplicaciones prácticas en el procesamiento de lenguaje natural:
- Búsqueda semántica: Encontrar documentos relevantes basándose en el significado, no solo en palabras clave exactas
- Agrupación de contenido: Clasificar automáticamente textos por temas o categorías similares
- Sistemas de recomendación: Sugerir contenido relacionado basándose en similitudes semánticas
- Detección de anomalías: Identificar textos que se desvían significativamente del patrón esperado
- Análisis de sentimientos: Clasificar textos según su tono emocional o intención
Esto permite recuperar información relevante y añadirla en los prompts que enviamos a los LLM:

Embeddings API de OpenAI
La API de Embeddings de OpenAI proporciona acceso directo a los modelos de embeddings más avanzados disponibles comercialmente. Esta API permite convertir cualquier texto en representaciones vectoriales de alta calidad mediante una interfaz simple y eficiente.
Modelos disponibles
OpenAI ofrece dos modelos principales de tercera generación optimizados para diferentes necesidades:
text-embedding-3-small:
- 1536 dimensiones por defecto
- Costo optimizado para aplicaciones de gran volumen
- Rendimiento equilibrado para la mayoría de casos de uso
- Máximo 8192 tokens de entrada
text-embedding-3-large:
- 3072 dimensiones por defecto
- Máximo rendimiento en tareas complejas
- Superior precisión en búsquedas semánticas avanzadas
- Máximo 8192 tokens de entrada
from openai import OpenAI
client = OpenAI()
# Usando el modelo pequeño para casos generales
response_small = client.embeddings.create(
input="Análisis de sentimientos en redes sociales",
model="text-embedding-3-small"
)
# Usando el modelo grande para máxima precisión
response_large = client.embeddings.create(
input="Análisis de sentimientos en redes sociales",
model="text-embedding-3-large"
)
Estructura de la respuesta
La API devuelve una estructura JSON que contiene el vector de embedding junto con metadatos útiles para el procesamiento:
response = client.embeddings.create(
input="Ejemplo de texto para embedding",
model="text-embedding-3-small"
)
# Estructura de la respuesta
print(f"Modelo utilizado: {response.model}")
print(f"Tokens procesados: {response.usage.total_tokens}")
print(f"Dimensiones del vector: {len(response.data[0].embedding)}")
# Acceso al vector de embedding
embedding_vector = response.data[0].embedding
print(f"Primeros 5 valores: {embedding_vector[:5]}")
Ejemplo de uso:

Procesamiento de múltiples textos
La API permite procesar múltiples textos simultáneamente en una sola petición, optimizando tanto el rendimiento como los costos:
textos_para_procesar = [
"Inteligencia artificial y machine learning",
"Desarrollo web con Python y Django",
"Análisis de datos con pandas y numpy",
"Sistemas distribuidos y microservicios"
]
response = client.embeddings.create(
input=textos_para_procesar,
model="text-embedding-3-small"
)
# Procesamiento de resultados múltiples
embeddings_resultados = []
for i, item in enumerate(response.data):
embedding = item.embedding
texto_original = textos_para_procesar[i]
embeddings_resultados.append({
'texto': texto_original,
'embedding': embedding,
'indice': item.index
})
print(f"Procesados {len(embeddings_resultados)} textos")
print(f"Total de tokens: {response.usage.total_tokens}")
Además, con librerías como numpy y conceptos de álgebra podemos calcular la métrica de similitud de coseno para saber qué textos se acercan más a lo que pregunta el usuario:
import numpy as np
def get_embedding(text, model="text-embedding-3-small"):
embedding = client.embeddings.create(input=[text], model=model).data[0].embedding
return embedding
def calculate_cosine_similarity(query_vector, vector):
return np.dot(query_vector, vector) / (np.linalg.norm(query_vector) * np.linalg.norm(vector))
Ejemplo de uso:

Control de dimensionalidad
Una característica avanzada permite reducir las dimensiones del embedding sin perder propiedades semánticas significativas:
# Embedding con dimensiones reducidas
response_reducido = client.embeddings.create(
input="Texto de ejemplo para dimensiones reducidas",
model="text-embedding-3-large",
dimensions=1024 # Reducido desde 3072 a 1024
)
embedding_reducido = response_reducido.data[0].embedding
print(f"Dimensiones reducidas: {len(embedding_reducido)}")
# Comparación de rendimiento vs tamaño
response_completo = client.embeddings.create(
input="Texto de ejemplo para dimensiones reducidas",
model="text-embedding-3-large"
)
embedding_completo = response_completo.data[0].embedding
print(f"Dimensiones completas: {len(embedding_completo)}")
Fuentes y referencias
Documentación oficial y recursos externos para profundizar en OpenAI SDK
Documentación oficial de OpenAI SDK
Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, OpenAI SDK es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de OpenAI SDK
Explora más contenido relacionado con OpenAI SDK y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Comprender qué son los embeddings y cómo representan el significado semántico del texto. Conocer los fundamentos matemáticos y propiedades semánticas de los embeddings. Identificar los casos de uso principales de los embeddings en procesamiento de lenguaje natural. Aprender a utilizar la API de embeddings de OpenAI para generar y manipular vectores semánticos. Implementar ejemplos prácticos de búsqueda semántica y optimización en el uso de embeddings.