Qué es la ventana de contexto
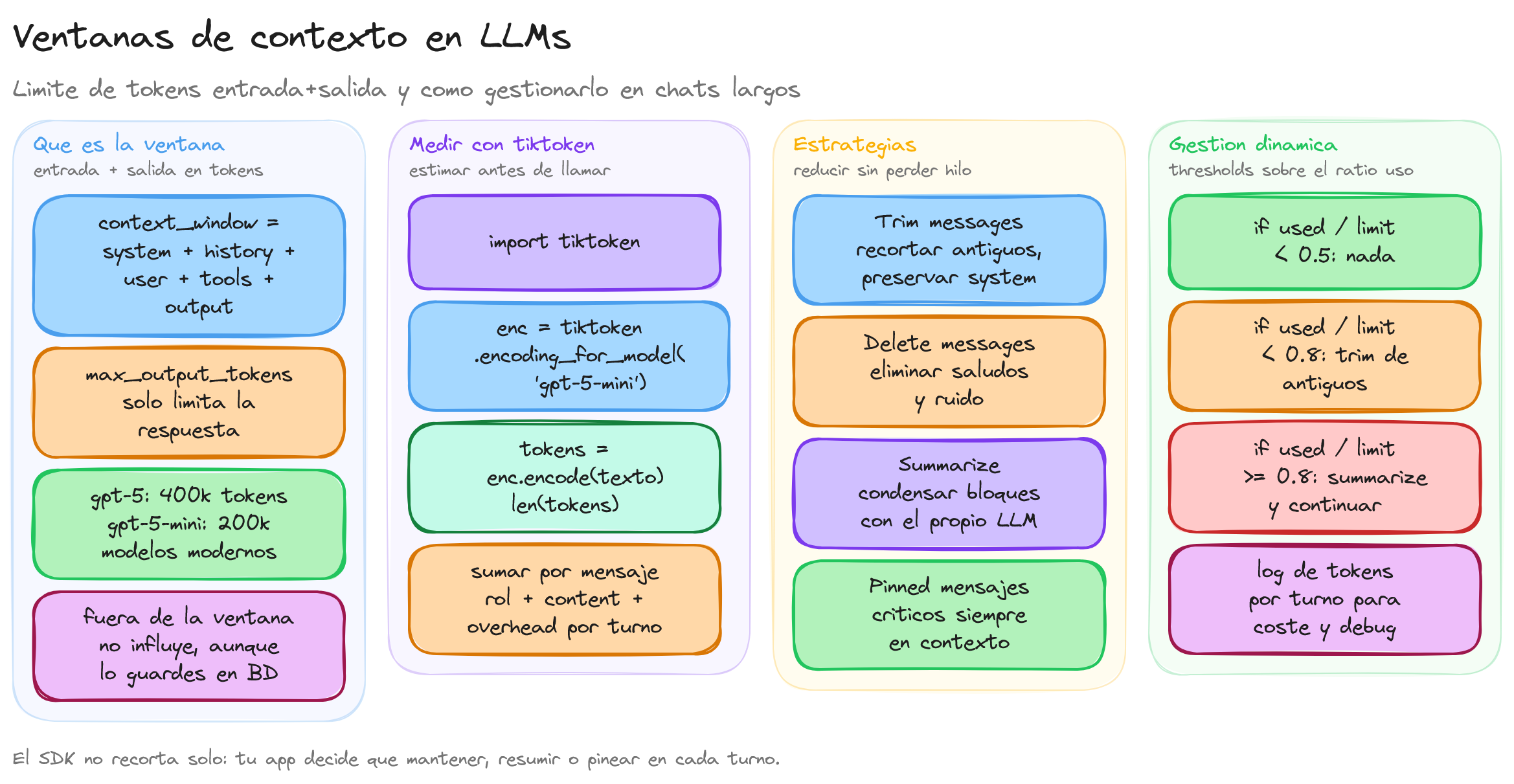
En los LLMs, la ventana de contexto es la cantidad máxima de tokens que el modelo puede tener en cuenta en una única petición, incluyendo tanto la entrada (mensajes anteriores, instrucciones, herramientas) como la salida generada. En la práctica, la ventana de contexto actúa como una memoria de corto plazo: todo lo que queda fuera de esa ventana deja de ser visible para el modelo, por lo que no puede influir en la siguiente respuesta aunque siga existiendo en tu aplicación.
Cada token representa una porción pequeña de texto (palabras, subpalabras o signos de puntuación), por lo que hablar de 4096 o 1.000.000 de tokens no es lo mismo que hablar de caracteres o palabras. Esta unidad basada en tokens es la que utilizan tanto los modelos como las librerías de conteo, y es la que determina de forma precisa cuánto cabe dentro de la ventana de contexto de un modelo concreto.
Context window vs max output tokens
Es importante distinguir entre context window y max output tokens, porque aunque ambos se midan en tokens, no representan lo mismo. La context window indica el máximo de tokens totales en una interacción (entrada + salida), mientras que max output tokens limita únicamente la longitud de la respuesta que el modelo puede generar en una única llamada.
En la práctica, el número máximo de tokens que el modelo puede devolver en una respuesta depende de cuántos tokens ocupa ya tu entrada. Cuantos más tokens uses en el prompt y en el historial, menos margen quedará disponible para la salida dentro de la ventana de contexto, aunque hayas configurado un valor alto en max output tokens. Esta es la razón por la que, cuando el prompt es muy largo, el modelo puede devolver menos texto del máximo configurado: está obligado a respetar siempre el límite global de la ventana de contexto.
En la documentación oficial de modelos de OpenAI (https://platform.openai.com/docs/models) puedes consultar en cada momento la ventana de contexto y el límite de salida de cada alias o snapshot vigente. Estas cifras cambian con relativa frecuencia, así que en un curso evergreen es mejor quedarse con dos ideas:
- la context window depende del modelo concreto y no conviene memorizar una tabla fija;
- los modelos más recientes de la familia GPT-5 suelen ofrecer ventanas muy amplias, pero eso no elimina la necesidad de gestionar bien el historial y el prompt.
La tendencia general ha sido pasar de ventanas relativamente pequeñas en generaciones anteriores a ventanas mucho mayores en modelos modernos. Esta ampliación permite trabajar con historiales largos, documentos extensos o múltiples fuentes de información, a costa de un mayor consumo de recursos y de la necesidad de decidir qué información es realmente relevante dentro de la ventana de contexto.
Ventana de contexto en otros modelos de otros proveedores:
- Google Gemini 3: 1.045.576 context window y 65.536 max output tokens.
- Anthropic Claude Sonnet 4.5: 1M context window y 64k max output tokens.
Estrategias
Cuando el tamaño de nuestros mensajes se acerca al límite de la ventana de contexto, es fundamental medir cuántos tokens estamos enviando y aplicar estrategias para reducir o reorganizar la información. Si no lo hacemos, la llamada puede fallar por exceder el límite del modelo o el proveedor puede recortar el contenido de manera poco controlada, lo que dificulta razonar sobre el comportamiento de la aplicación.
Medir tokens con tiktoken
Para saber si estamos cerca de la ventana de contexto, una práctica habitual es usar tiktoken, la librería de conteo de tokens compatible con los modelos de OpenAI. Esta herramienta permite estimar cuántos tokens ocupará un texto antes de enviarlo a la API, y así ajustar el prompt o el historial de mensajes para que quepa dentro de la ventana de contexto del modelo elegido.
Un ejemplo básico en Python para contar tokens de un texto podría ser:
import tiktoken
def contar_tokens(texto: str, modelo: str = "gpt-5.4-mini") -> int:
# Obtiene el encoding apropiado para el modelo
encoding = tiktoken.encoding_for_model(modelo)
# Codifica el texto en tokens
tokens = encoding.encode(texto)
# Devuelve el número total de tokens
return len(tokens)
prompt = "Analiza este texto y genera un resumen técnico breve."
num_tokens = contar_tokens(prompt)
print(f"Número de tokens en el prompt: {num_tokens}")
En aplicaciones de chat, suele ser útil contar los tokens de cada mensaje (rol + contenido) y sumarlos, para obtener el tamaño total del historial más el mensaje actual. Esta estimación permite decidir si hay que recortar, resumir o filtrar partes del historial antes de invocar al modelo, de forma que siempre nos mantengamos por debajo de la ventana de contexto configurada.
Adaptar los mensajes al tamaño de la ventana de contexto
El SDK oficial de OpenAI no incorpora una gestión automática avanzada de historiales largos, por lo que la responsabilidad de adaptar los mensajes al tamaño de la ventana de contexto recae en la lógica de tu aplicación. Esto significa que debes decidir qué partes del historial conservar, cuáles eliminar y cuándo resumir información para mantener una conversación coherente sin exceder los límites del modelo.
Existen varias estrategias habituales para gestionar historiales extensos, que pueden combinarse según el caso de uso:
-
1. Trim messages (recortar mensajes): consiste en eliminar los mensajes más antiguos cuando el historial se acerca al límite de la ventana de contexto. Una variante muy común es mantener siempre los mensajes iniciales importantes (por ejemplo, el mensaje de sistema y las instrucciones clave) y recortar solo la parte central del historial, preservando también los mensajes más recientes.
-
2. Delete messages (eliminar mensajes irrelevantes): en lugar de recortar por orden temporal, podemos eliminar mensajes que ya no aportan información útil para la tarea actual. Esta estrategia requiere identificar qué mensajes son redundantes, por ejemplo interacciones de saludo, errores ya corregidos o pasos intermedios que no afectan al estado final de la conversación.
-
3. Summarize messages (resumir mensajes): cuando no queremos perder información pero sí reducir tokens, podemos sustituir bloques del historial por un resumen compacto generado por el propio modelo. La idea es mantener una descripción condensada de lo ocurrido (objetivos, decisiones, resultados) en lugar de todos los mensajes detallados, lo que reduce el uso de la ventana de contexto sin perder el hilo de la conversación.
-
4. Filter messages (filtrar mensajes por relevancia): otra aproximación es seleccionar dinámicamente qué mensajes se envían al modelo en cada llamada, en función de su relevancia para la pregunta actual. Esto puede hacerse mediante reglas sencillas (por tipo de mensaje o etiquetas) o mediante técnicas más avanzadas, como búsquedas semánticas o índices vectoriales, para incluir solo la información más relevante en cada interacción.
En entornos donde se requiere una gestión más sofisticada de la memoria de corto plazo, es habitual apoyarse en frameworks como LangChain, que ya incluyen patrones y utilidades para manejar historiales largos.
En la documentación de LangChain sobre short-term memory se describen precisamente estrategias que pueden servir como referencia para implementar soluciones similares incluso cuando se trabaja directamente con el SDK oficial de OpenAI.
Fuentes y referencias
Documentación oficial y recursos externos para profundizar en OpenAI SDK
Documentación oficial de OpenAI SDK
Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, OpenAI SDK es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de OpenAI SDK
Explora más contenido relacionado con OpenAI SDK y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Comprender qué es la ventana de contexto y su importancia en modelos de lenguaje. Aprender a contar tokens y monitorizar su uso en conversaciones. Implementar estrategias de truncamiento para manejar límites de contexto. Aplicar técnicas de resumen para condensar información histórica. Desarrollar una gestión dinámica que combine distintas estrategias según el uso de tokens.