Batch API para ahorro de costes
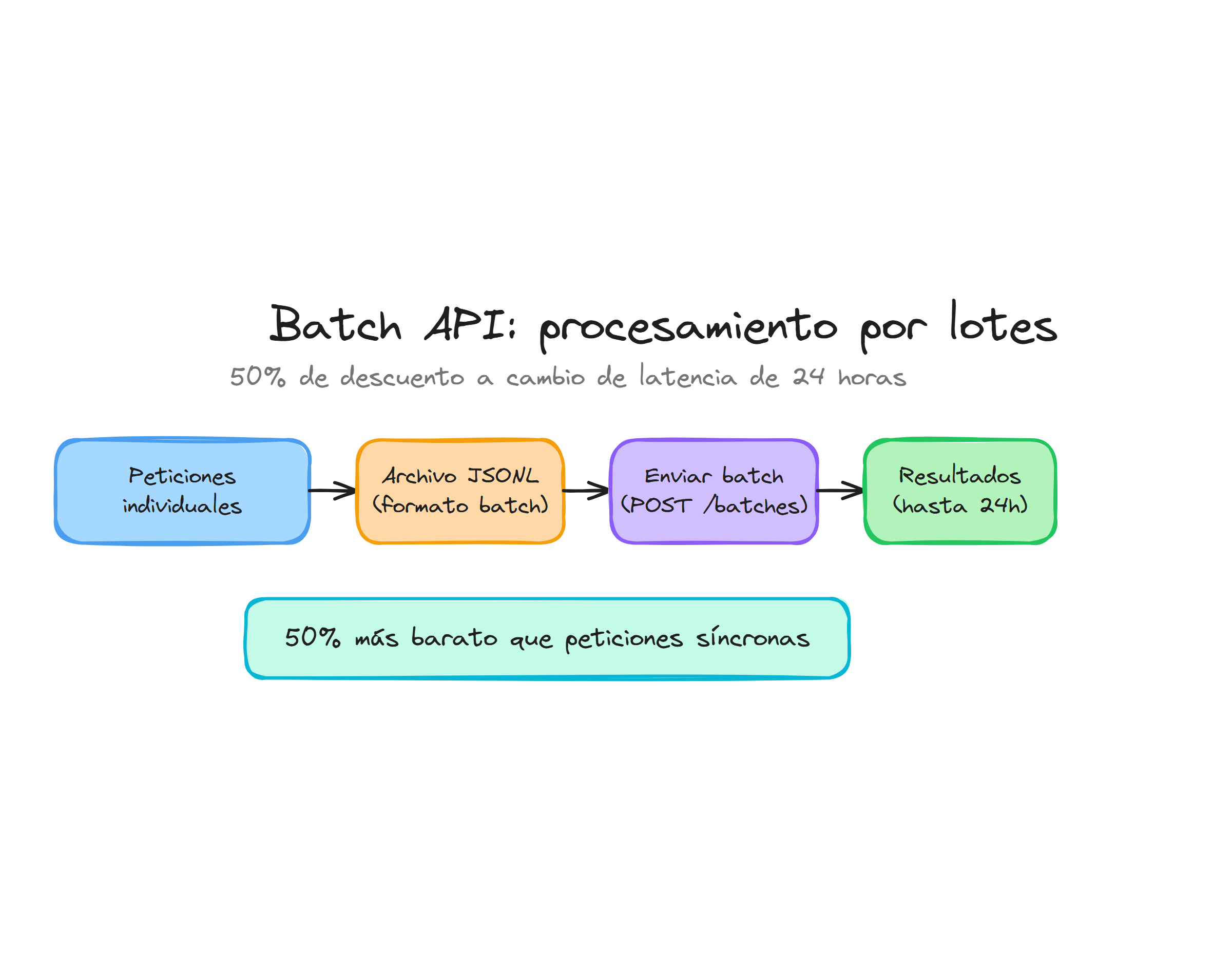
La Batch API de OpenAI representa una estrategia fundamental para optimizar costes cuando trabajas con grandes volúmenes de solicitudes que no requieren respuesta inmediata. Esta API está diseñada específicamente para procesamiento asíncrono, permitiéndote enviar grupos de peticiones con un descuento del 50% en el coste tanto de tokens de entrada como de salida, además de ofrecer límites de tasa significativamente más altos y un tiempo de finalización garantizado de 24 horas.
Cuándo utilizar Batch API
Batch API resulta especialmente útil en escenarios donde la latencia no es crítica. Los casos de uso más comunes incluyen:
- Evaluaciones de modelos: ejecutar conjuntos de pruebas exhaustivos para validar el rendimiento de tus prompts o analizar diferentes configuraciones
- Clasificación de grandes datasets: etiquetar miles de registros, analizar sentimientos en reviews de productos o categorizar documentos
- Generación de embeddings: procesar repositorios completos de contenido para búsqueda semántica o sistemas de recomendación
- Enriquecimiento de datos: generar resúmenes, traducciones o metadatos para bases de datos existentes
La clave está en identificar tareas que pueden ejecutarse durante la noche o en momentos de baja actividad, donde esperar hasta 24 horas por los resultados no afecta tu flujo de trabajo.
Estructura del proceso batch
El proceso de trabajo con Batch API sigue un flujo bien definido que consta de varios pasos. Primero debes preparar un archivo JSONL donde cada línea representa una solicitud individual con su identificador único. Luego subes el archivo usando la Files API, creas el batch job con client.batches.create(), monitorizas su estado periódicamente, y finalmente recuperas los resultados cuando el estado cambia a completed.
Batch API admite varios endpoints de la plataforma, entre ellos /v1/chat/completions, /v1/responses, /v1/embeddings, /v1/completions y /v1/moderations. Todos comparten el mismo patrón de trabajo con archivos JSONL y se benefician del mismo modelo de descuento y de límites de tasa específicos para procesamiento batch.
Preparar el archivo de entrada
El primer paso consiste en crear un archivo .jsonl donde cada línea contiene una solicitud completa. Cada request debe incluir:
- Un
custom_idúnico que te permita mapear los resultados con las entradas originales - El método HTTP (siempre
POST) - La URL del endpoint (por ejemplo,
/v1/chat/completionso/v1/responses) - El body con los parámetros exactos que usarías en una llamada normal a la API
Aquí tienes un ejemplo de cómo generar este archivo con Python:
import json
# Datos de ejemplo para clasificar
productos = [
{"id": "prod_001", "descripcion": "Portátil gaming con RTX 4080 y 32GB RAM"},
{"id": "prod_002", "descripcion": "Auriculares bluetooth con cancelación de ruido"},
{"id": "prod_003", "descripcion": "Teclado mecánico RGB retroiluminado"}
]
# Preparar las solicitudes en formato batch
tareas = []
for producto in productos:
tarea = {
"custom_id": producto["id"],
"method": "POST",
"url": "/v1/chat/completions",
"body": {
"model": "gpt-5.4-mini",
"messages": [
{
"role": "system",
"content": "Clasifica el producto en una de estas categorías: Informática, Audio, Periféricos"
},
{
"role": "user",
"content": producto["descripcion"]
}
],
"max_tokens": 50
}
}
tareas.append(tarea)
# Guardar en archivo JSONL
with open("clasificacion_productos.jsonl", "w", encoding="utf-8") as f:
for tarea in tareas:
f.write(json.dumps(tarea, ensure_ascii=False) + "\n")
print(f"Archivo preparado con {len(tareas)} solicitudes")
Es importante que cada archivo contenga solicitudes al mismo endpoint y que respete los límites de tamaño: máximo 50,000 solicitudes por batch y un tamaño de archivo de hasta 200 MB.
Subir el archivo y crear el batch
Una vez preparado el archivo, el siguiente paso es subirlo a OpenAI y crear el batch job:
from openai import OpenAI
client = OpenAI()
# Paso 1: Subir el archivo JSONL
print("Subiendo archivo...")
batch_file = client.files.create(
file=open("clasificacion_productos.jsonl", "rb"),
purpose="batch"
)
print(f"Archivo subido: {batch_file.id}")
# Paso 2: Crear el batch job
print("Creando batch job...")
batch_job = client.batches.create(
input_file_id=batch_file.id,
endpoint="/v1/chat/completions",
completion_window="24h",
metadata={
"description": "Clasificación de catálogo de productos",
"proyecto": "ecommerce_v2"
}
)
print(f"Batch job creado: {batch_job.id}")
print(f"Estado inicial: {batch_job.status}")
El parámetro metadata es opcional pero muy recomendable para organizar y rastrear tus batches. El completion_window actualmente solo acepta el valor "24h".
Monitorizar el progreso
Una vez iniciado el batch job, necesitas verificar periódicamente su estado. El batch puede pasar por varios estados:
validating: se está validando el archivo de entradafailed: la validación falló (revisa el formato de tu archivo)in_progress: el batch se está procesando activamentefinalizing: el procesamiento terminó y se están preparando los resultadoscompleted: el batch finalizó exitosamenteexpired: no se completó en el plazo de 24 horascancelling/cancelled: el batch fue cancelado manualmente
Aquí tienes una forma eficiente de monitorizar el progreso:
import time
def esperar_batch_completado(batch_id, intervalo=30):
"""
Monitoriza un batch hasta que se complete o falle.
Args:
batch_id: ID del batch a monitorizar
intervalo: Segundos entre cada verificación
"""
print(f"Monitorizando batch {batch_id}...")
while True:
batch = client.batches.retrieve(batch_id)
# Mostrar progreso si está disponible
estado = batch.status
if hasattr(batch, 'request_counts') and batch.request_counts:
total = batch.request_counts.total
completado = batch.request_counts.completed
fallido = batch.request_counts.failed
progreso = (completado / total * 100) if total > 0 else 0
print(f"Estado: {estado} | Progreso: {completado}/{total} ({progreso:.1f}%) | Fallos: {fallido}")
else:
print(f"Estado: {estado}")
# Verificar si terminó
if estado in ["completed", "failed", "expired", "cancelled"]:
return batch
time.sleep(intervalo)
# Usar la función
batch_final = esperar_batch_completado(batch_job.id)
if batch_final.status == "completed":
print("✓ Batch completado exitosamente")
else:
print(f"✗ Batch terminó con estado: {batch_final.status}")
Para aplicaciones en producción, es preferible usar webhooks en lugar de polling. Puedes configurar webhooks en tu panel de OpenAI para recibir notificaciones automáticas cuando un batch cambie de estado, lo cual es más eficiente y reduce la carga en la API.
Recuperar y procesar resultados
Cuando el batch alcanza el estado completed, puedes descargar el archivo de resultados usando el output_file_id:
# Obtener el contenido del archivo de resultados
resultados_content = client.files.content(batch_final.output_file_id)
resultados_texto = resultados_content.text
# Guardar localmente
with open("resultados_clasificacion.jsonl", "w", encoding="utf-8") as f:
f.write(resultados_texto)
# Procesar los resultados
resultados_procesados = []
for linea in resultados_texto.strip().split("\n"):
resultado = json.loads(linea)
# Extraer información relevante
item = {
"custom_id": resultado["custom_id"],
"status": resultado["response"]["status_code"] if resultado["response"] else "error",
"contenido": None,
"error": resultado.get("error")
}
# Obtener la respuesta si fue exitosa
if resultado["response"] and resultado["response"]["status_code"] == 200:
body = resultado["response"]["body"]
item["contenido"] = body["choices"][0]["message"]["content"]
item["tokens_usados"] = body["usage"]["total_tokens"]
resultados_procesados.append(item)
# Mostrar resumen
exitosos = sum(1 for r in resultados_procesados if r["status"] == 200)
print(f"\nResumen: {exitosos}/{len(resultados_procesados)} solicitudes exitosas")
# Ejemplo de procesamiento por custom_id
for resultado in resultados_procesados[:3]:
print(f"\nProducto {resultado['custom_id']}: {resultado['contenido']}")
Es importante destacar que el orden de las líneas en el archivo de salida no coincide necesariamente con el orden del archivo de entrada. Por eso es fundamental usar el custom_id para mapear correctamente cada resultado con su solicitud original.
Si algunas solicitudes fallaron, puedes encontrar los detalles de los errores en el archivo indicado por error_file_id:
if batch_final.error_file_id:
errores_content = client.files.content(batch_final.error_file_id)
errores_texto = errores_content.text
print("\nAnalizando errores...")
for linea in errores_texto.strip().split("\n"):
error = json.loads(linea)
print(f"Request {error['custom_id']}: {error['error']['message']}")
Gestión de batches
OpenAI proporciona funciones adicionales para administrar tus batches:
Listar todos los batches:
# Obtener los últimos 10 batches
batches = client.batches.list(limit=10)
for batch in batches.data:
print(f"ID: {batch.id} | Estado: {batch.status} | Creado: {batch.created_at}")
Cancelar un batch en progreso:
# Si necesitas detener un batch antes de que termine
batch_cancelado = client.batches.cancel("batch_abc123")
print(f"Batch {batch_cancelado.id} cancelado. Estado: {batch_cancelado.status}")
El proceso de cancelación puede tardar hasta 10 minutos en completarse, ya que las solicitudes que ya están en proceso terminarán su ejecución.
Límites y consideraciones
La Batch API tiene límites de tasa separados de las APIs síncronas, lo que significa que usar batches no consume tu cuota de rate limits normales. Los límites específicos dependen de tu tier de organización:
- Límites por batch: hasta 50,000 requests por archivo, tamaño máximo de 200 MB
- Tokens encolados: cada modelo tiene un límite máximo de tokens que pueden estar pendientes de procesamiento simultáneamente
- Sin límite de tokens de salida: no hay restricciones en la cantidad de tokens generados por el batch
Los archivos de resultados se mantienen disponibles durante 30 días después de completarse el batch, tras lo cual se eliminan automáticamente. Descarga y almacena los resultados que necesites conservar.
Optimización de costes en la práctica
Para maximizar el ahorro con Batch API, considera estos escenarios de costo comparativo. Por ejemplo, si necesitas clasificar 100,000 productos con un promedio de 500 tokens de entrada y 50 tokens de salida por producto usando gpt-5.4-mini:
-
Coste estándar: $0.40 por 1M tokens de entrada y $1.60 por 1M tokens de salida
-
Entrada: (100,000 × 500 / 1,000,000) × $0.40 = $20
-
Salida: (100,000 × 50 / 1,000,000) × $1.60 = $8
-
Total: $28
-
Coste con Batch API (50% descuento):
-
Entrada: $20 × 0.5 = $10
-
Salida: $8 × 0.5 = $4
-
Total: $14 (ahorro de $14)
Este ahorro del 50% se vuelve especialmente significativo en proyectos con procesamiento recurrente o datasets masivos, donde los costes acumulados pueden representar una parte importante del presupuesto.
Fuentes y referencias
Documentación oficial y recursos externos para profundizar en OpenAI SDK
Documentación oficial de OpenAI SDK
Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, OpenAI SDK es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de OpenAI SDK
Explora más contenido relacionado con OpenAI SDK y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Comprender qué es la Batch API y cuándo es conveniente utilizarla. Aprender a preparar archivos JSONL para enviar solicitudes batch. Conocer el proceso completo: subir archivos, crear batch jobs, monitorizar y recuperar resultados. Saber gestionar errores y administrar batches en producción. Entender los límites, consideraciones y beneficios económicos de la Batch API.