Modo background
Cuando trabajamos con tareas complejas sobre modelos de la familia GPT-5, especialmente variantes pensadas para razonamiento profundo, las respuestas pueden tardar varios minutos en completarse. Esto plantea un desafío técnico: las conexiones HTTP tradicionales pueden sufrir timeouts, los usuarios pueden perder la paciencia esperando, y mantener una conexión abierta durante largo tiempo consume recursos innecesariamente.
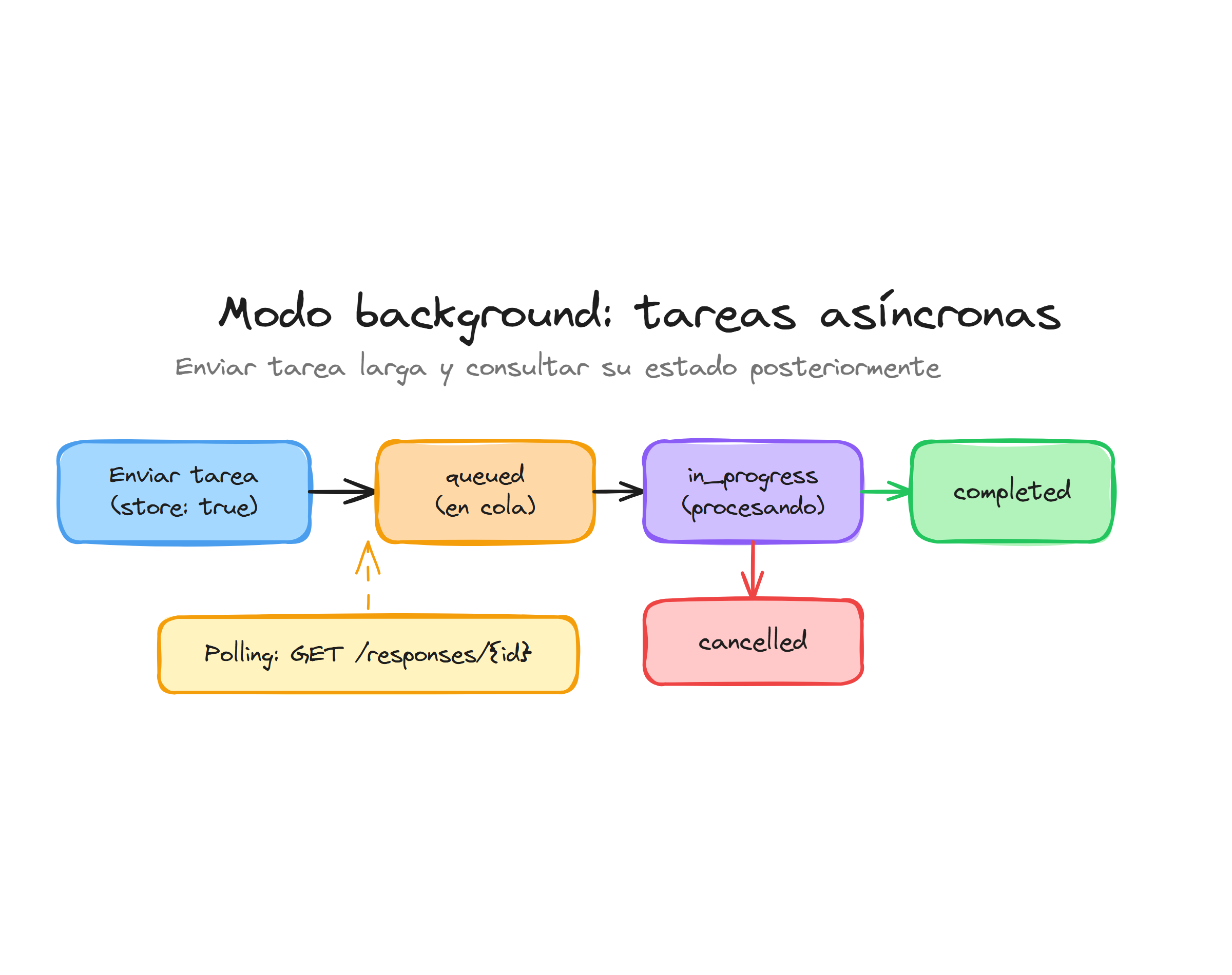
El modo background resuelve estos problemas ejecutando las tareas de manera asíncrona. En lugar de mantener una conexión abierta hasta que el modelo termine, la API devuelve inmediatamente un identificador del trabajo y permite consultar su estado cuando sea conveniente.
Cuándo usar background mode
El modo background está diseñado específicamente para:
- Modelos de razonamiento complejos que requieren varios minutos de procesamiento
- Tareas largas y complejas como análisis exhaustivos, investigación profunda o generación de contenido extenso
- Aplicaciones donde la latencia no es crítica y el usuario puede esperar o realizar otras acciones mientras tanto
- Evitar problemas de infraestructura relacionados con timeouts de conexión
Activar el modo background
Para ejecutar una respuesta en segundo plano, simplemente establece el parámetro background=True al crear la respuesta:
from openai import OpenAI
client = OpenAI()
response = client.responses.create(
model="gpt-5.4-pro",
input="Escribe una novela completa sobre nutrias espaciales con estructura de tres actos.",
background=True
)
print(f"Estado inicial: {response.status}")
print(f"ID de la respuesta: {response.id}")
La respuesta devuelta inmediatamente incluye:
- id: Identificador único para consultar el estado
- status: Estado inicial (normalmente
queued) - model: Modelo utilizado
- Otros metadatos relevantes
Estados del proceso
Una respuesta en background puede estar en varios estados durante su ciclo de vida:
| Estado | Descripción | |--------|-------------| | queued | La solicitud está en cola esperando procesamiento | | in_progress | El modelo está generando activamente la respuesta | | completed | Generación completada exitosamente | | failed | Error durante el procesamiento | | cancelled | Cancelada manualmente por el usuario |
Consultar el estado con polling
Para verificar el progreso de una respuesta en background, utiliza el método retrieve() con el ID de la respuesta:
from time import sleep
# Crear respuesta en background
response = client.responses.create(
model="gpt-5.4-pro",
input="Analiza en profundidad las implicaciones éticas de la IA en la medicina moderna.",
background=True
)
# Polling para verificar estado
while response.status in {"queued", "in_progress"}:
print(f"Estado actual: {response.status}")
sleep(5) # Esperar 5 segundos entre consultas
response = client.responses.retrieve(response.id)
# Una vez completado
if response.status == "completed":
print("¡Respuesta completada!")
print(response.output_text)
else:
print(f"Estado final: {response.status}")
Buenas prácticas para el polling:
- Usa intervalos razonables (5-10 segundos) para no saturar la API
- Implementa backoff exponencial si la tarea se prolonga mucho
- Proporciona feedback visual al usuario sobre el progreso
- Maneja adecuadamente los estados de error
Cancelar una respuesta en background
Si ya no necesitas el resultado de una tarea en progreso, puedes cancelarla explícitamente:
# Cancelar una respuesta
cancelled_response = client.responses.cancel("resp_123")
print(f"Estado después de cancelar: {cancelled_response.status}")
Cancelar una respuesta es una operación idempotente: si intentas cancelar la misma respuesta varias veces, simplemente obtendrás el objeto final sin errores adicionales.
Streaming con background mode
Puedes combinar el modo background con streaming para comenzar a recibir eventos inmediatamente mientras la respuesta se genera de forma asíncrona:
# Crear y hacer streaming de una respuesta en background
stream = client.responses.create(
model="gpt-5.4-pro",
input="Genera un análisis detallado del mercado europeo de semiconductores.",
background=True,
stream=True
)
cursor = None
for event in stream:
print(event)
cursor = event.sequence_number
Esta combinación es útil cuando:
- Quieres mostrar progreso parcial al usuario inmediatamente
- La conexión puede interrumpirse pero quieres que el trabajo continúe
- Necesitas la opción de reconectar usando el cursor si se pierde la conexión
Importante: Si creas una respuesta con background=True y stream=True, puedes reconectarte más tarde usando el cursor (sequence_number) para reanudar desde donde quedó el stream.
Limitaciones del modo background
Existen algunas restricciones importantes al usar background mode:
- 1. Requiere
store=true: Las respuestas en background necesitan ser almacenadas. Las solicitudes sin estado (store=false) serán rechazadas.
# Esto fallará
response = client.responses.create(
model="gpt-5.4-pro",
input="Algún texto...",
background=True,
store=False # No compatible con background
)
-
2. Cancelación solo en background: Para cancelar una respuesta síncrona (sin
background=True), simplemente termina la conexión. El endpointcancel()solo funciona para respuestas en background. -
3. Streaming inicial solo si se especificó: Solo puedes iniciar un nuevo stream desde una respuesta background si la creaste originalmente con
stream=True.
Ejemplo práctico completo
from openai import OpenAI
from time import sleep
client = OpenAI()
# Iniciar tarea larga en background
print("Iniciando generación en background...")
response = client.responses.create(
model="gpt-5.4-pro",
input="Desarrolla un plan de negocio completo para una startup de IA médica.",
background=True
)
print(f"Respuesta creada con ID: {response.id}")
print("Puedes cerrar esta ventana y consultar el estado más tarde.\n")
# Simulación de polling con feedback visual
attempts = 0
max_attempts = 60 # Máximo 5 minutos (60 * 5 segundos)
while response.status in {"queued", "in_progress"} and attempts < max_attempts:
attempts += 1
status_icon = "[en cola]" if response.status == "queued" else "[procesando]"
print(f"{status_icon} {response.status.capitalize()}... (intento {attempts})")
sleep(5)
response = client.responses.retrieve(response.id)
print()
# Manejar resultado final
if response.status == "completed":
print("Generacion completada exitosamente")
print(f"\nContenido generado ({len(response.output_text)} caracteres):\n")
print(response.output_text[:500] + "...")
elif response.status == "failed":
print("La generacion fallo")
else:
print(f"Estado final inesperado: {response.status}")
El modo background transforma la experiencia de usar modelos de razonamiento avanzado, haciendo viable el procesamiento de tareas complejas sin sacrificar la estabilidad de la conexión ni la experiencia del usuario.
Impacto en latencia, costes y diseño de arquitectura
El modo background no reduce directamente el precio por token, pero sí te ayuda a controlar mejor la latencia real que perciben los usuarios y la carga sobre tu infraestructura. Al delegar las tareas largas a procesos asíncronos, evitas timeouts en tu backend, liberas hilos de aplicación antes y puedes dedicar tus recursos más rápidos a peticiones interactivas de baja latencia.
En términos de costes, el ahorro viene de evitar trabajo desperdiciado: menos respuestas interrumpidas por timeouts, menos reintentos manuales por parte de los usuarios y mejor planificación del uso de modelos de razonamiento caros. Si combinas background mode con colas de trabajo (por ejemplo, usando Celery, RQ o workers propios en Python), puedes regular cuántas tareas largas procesas en paralelo para no saturar tus rate limits ni los recursos de tu organización.
Un patrón habitual en aplicaciones productivas es separar claramente dos flujos: por un lado, endpoints síncronos con modelos rápidos y streaming para conversación interactiva; por otro, pipelines en background que usan variantes de razonamiento profundo de GPT-5 para análisis extensos o generación de contenido largo. De este modo consigues una experiencia de usuario ágil, mantienes la latencia baja donde importa y concentras el uso intensivo de tokens en procesos controlados y monitorizados.
Fuentes y referencias
Documentación oficial y recursos externos para profundizar en OpenAI SDK
Documentación oficial de OpenAI SDK
Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, OpenAI SDK es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de OpenAI SDK
Explora más contenido relacionado con OpenAI SDK y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Comprender la necesidad del modo background para modelos de razonamiento avanzado. Aprender a activar y gestionar respuestas en background con la API. Conocer los estados de una tarea en background y cómo consultarlos mediante polling. Saber cancelar tareas en background y combinar este modo con streaming. Identificar las limitaciones y buenas prácticas al usar el modo background.