Text-to-Speech: voces y configuración
La personalización de la síntesis de voz es fundamental para crear experiencias de audio que se adapten al contexto y audiencia de tu aplicación. OpenAI ofrece múltiples opciones de configuración que permiten controlar tanto las características de la voz como los parámetros técnicos de la generación de audio.
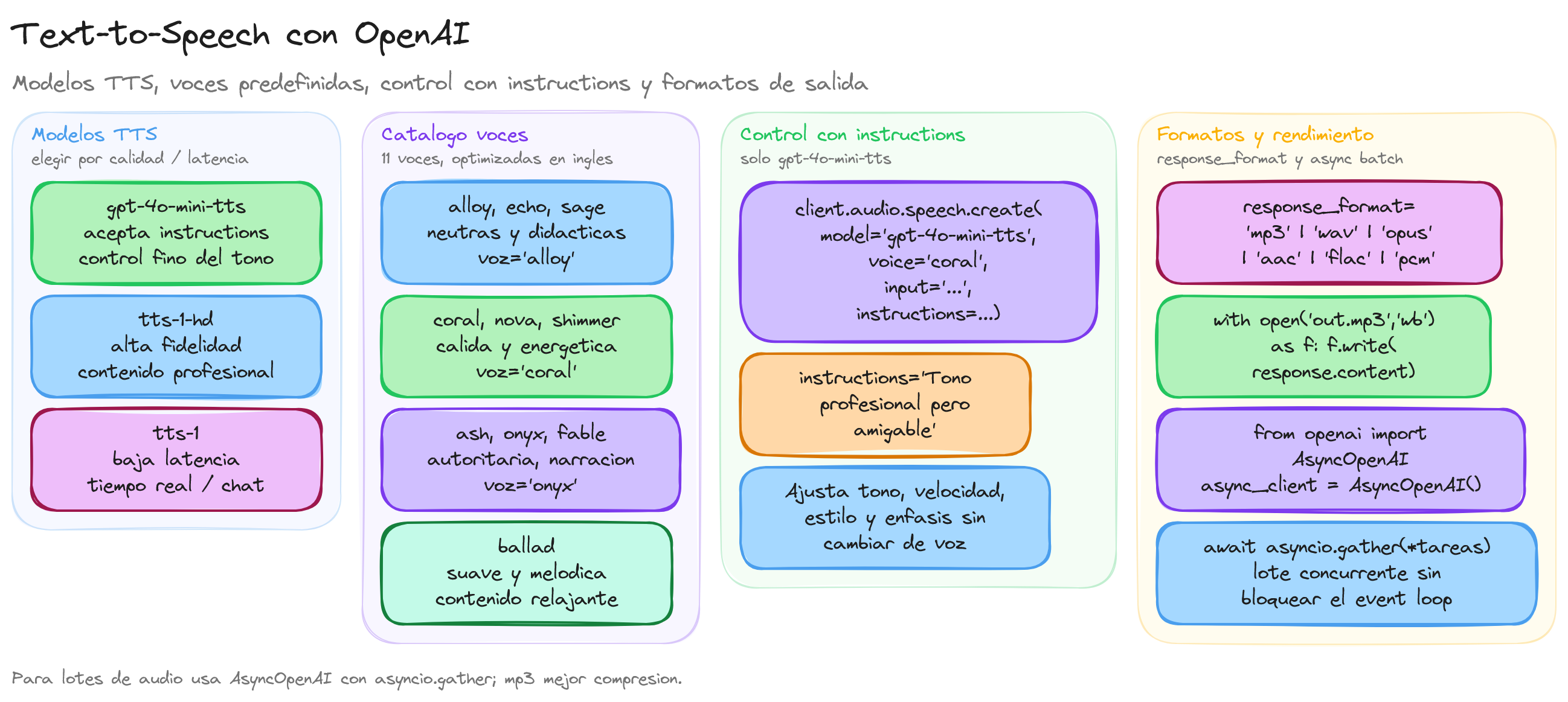
Modelos disponibles para TTS
OpenAI proporciona tres modelos especializados para text-to-speech, cada uno optimizado para diferentes casos de uso:
- gpt-4o-mini-tts: El modelo más avanzado que permite control inteligente sobre aspectos del habla mediante instrucciones en lenguaje natural
- tts-1-hd: Modelo de alta calidad con mejor fidelidad de audio, ideal para contenido profesional
- tts-1: Modelo optimizado para baja latencia, perfecto para aplicaciones en tiempo real
from openai import OpenAI
client = OpenAI()
# Usando el modelo más avanzado con instrucciones
response = client.audio.speech.create(
model="gpt-4o-mini-tts",
voice="coral",
input="Bienvenido a nuestra aplicación de aprendizaje",
instructions="Habla con un tono profesional pero amigable, como un instructor experimentado"
)
# Guardando el audio generado
with open("bienvenida.mp3", "wb") as f:
f.write(response.content)
Catálogo de voces
La API incluye 11 voces predefinidas optimizadas para inglés pero compatibles con múltiples idiomas. Cada voz tiene características distintivas que las hacen apropiadas para diferentes contextos:
- alloy: Voz neutra y versátil, ideal para aplicaciones generales
- ash: Tono más grave y autoritario, perfecto para narraciones serias
- ballad: Voz suave y melódica, excelente para contenido relajante
- coral: Tono cálido y amigable, ideal para interfaces de usuario
- echo: Voz clara y directa, apropiada para instrucciones
- fable: Tono expresivo y dinámico, perfecto para storytelling
- nova: Voz joven y energética, ideal para contenido juvenil
- onyx: Tono profundo y resonante, excelente para presentaciones
- sage: Voz madura y confiable, apropiada para contenido educativo
- shimmer: Tono brillante y optimista, perfecto para marketing
# Comparando diferentes voces para el mismo contenido
voces_disponibles = ["alloy", "coral", "nova", "sage"]
texto = "Esta es una demostración de las diferentes voces disponibles"
for voz in voces_disponibles:
response = client.audio.speech.create(
model="tts-1",
voice=voz,
input=texto
)
with open(f"demo_{voz}.mp3", "wb") as f:
f.write(response.content)
print(f"Audio generado con voz {voz}")
Control avanzado con instrucciones
El modelo gpt-4o-mini-tts permite un control granular sobre la síntesis mediante instrucciones en lenguaje natural. Puedes especificar aspectos como:
- Tono emocional: alegre, serio, melancólico, entusiasta
- Velocidad del habla: rápido, lento, pausado
- Estilo de pronunciación: formal, casual, susurrando
- Características específicas: acento, énfasis, inflexión
# Configuración avanzada para diferentes contextos
configuraciones = {
"presentacion": {
"voice": "sage",
"instructions": "Habla con autoridad y claridad, haciendo pausas apropiadas para enfatizar puntos importantes"
},
"tutorial": {
"voice": "coral",
"instructions": "Usa un tono paciente y didáctico, como si estuvieras enseñando a un principiante"
},
"marketing": {
"voice": "nova",
"instructions": "Habla con entusiasmo y energía, transmitiendo emoción y motivación"
}
}
def generar_audio_contextual(texto, contexto):
config = configuraciones.get(contexto, configuraciones["tutorial"])
response = client.audio.speech.create(
model="gpt-4o-mini-tts",
voice=config["voice"],
input=texto,
instructions=config["instructions"]
)
return response.content
# Uso práctico
audio_presentacion = generar_audio_contextual(
"Los resultados del trimestre muestran un crecimiento del 15%",
"presentacion"
)
Formatos de salida y optimización
La selección del formato de audio impacta directamente en la calidad, tamaño del archivo y latencia de la aplicación:
- MP3: Formato por defecto, equilibrio entre calidad y tamaño
- WAV: Sin compresión, ideal para aplicaciones de baja latencia
- PCM: Datos de audio en bruto, máxima velocidad de procesamiento
- Opus: Optimizado para streaming, excelente compresión
- AAC: Compatible con dispositivos móviles, buena calidad
- FLAC: Compresión sin pérdidas, ideal para archivos de alta calidad
# Configuración optimizada para diferentes casos de uso
def configurar_formato_audio(uso_caso):
configuraciones = {
"tiempo_real": {
"response_format": "wav",
"model": "tts-1" # Menor latencia
},
"streaming": {
"response_format": "opus",
"model": "tts-1-hd"
},
"archivo_final": {
"response_format": "flac",
"model": "tts-1-hd" # Máxima calidad
},
"movil": {
"response_format": "aac",
"model": "tts-1"
}
}
return configuraciones.get(uso_caso, configuraciones["archivo_final"])
# Generación optimizada para streaming
config = configurar_formato_audio("streaming")
response = client.audio.speech.create(
model=config["model"],
voice="coral",
input="Contenido para transmisión en vivo",
response_format=config["response_format"]
)
Configuración para múltiples idiomas
Aunque las voces están optimizadas para inglés, funcionan efectivamente con múltiples idiomas. La calidad puede variar según el idioma y la voz seleccionada:
# Configuración multiidioma
textos_multiidioma = {
"español": "Hola, bienvenido a nuestra aplicación",
"francés": "Bonjour, bienvenue dans notre application",
"alemán": "Hallo, willkommen in unserer Anwendung",
"italiano": "Ciao, benvenuto nella nostra applicazione"
}
# Voces recomendadas por idioma
voces_por_idioma = {
"español": "coral",
"francés": "ballad",
"alemán": "onyx",
"italiano": "nova"
}
for idioma, texto in textos_multiidioma.items():
voz_recomendada = voces_por_idioma.get(idioma, "alloy")
response = client.audio.speech.create(
model="gpt-4o-mini-tts",
voice=voz_recomendada,
input=texto,
instructions=f"Pronuncia claramente en {idioma}, adaptando la entonación al idioma"
)
with open(f"saludo_{idioma}.mp3", "wb") as f:
f.write(response.content)
Optimización de rendimiento
Para aplicaciones que requieren múltiples generaciones de audio, es importante implementar estrategias de optimización:
import asyncio
from openai import AsyncOpenAI
async_client = AsyncOpenAI()
async def generar_audio_lote(textos_y_configuraciones):
"""Genera múltiples audios de forma asíncrona"""
tareas = []
for texto, config in textos_y_configuraciones:
tarea = async_client.audio.speech.create(
model=config.get("model", "tts-1"),
voice=config.get("voice", "alloy"),
input=texto,
response_format=config.get("format", "mp3")
)
tareas.append(tarea)
return await asyncio.gather(*tareas)
# Uso para generar múltiples audios
configuraciones_lote = [
("Primer mensaje", {"voice": "coral", "model": "tts-1"}),
("Segundo mensaje", {"voice": "sage", "model": "tts-1-hd"}),
("Tercer mensaje", {"voice": "nova", "model": "gpt-4o-mini-tts"})
]
# Ejecución asíncrona
audios = asyncio.run(generar_audio_lote(configuraciones_lote))
La combinación adecuada de modelo, voz, formato y configuración específica permite crear experiencias de audio que se adapten perfectamente a las necesidades de tu aplicación, desde interfaces conversacionales hasta contenido multimedia profesional.
Fuentes y referencias
Documentación oficial y recursos externos para profundizar en OpenAI SDK
Documentación oficial de OpenAI SDK
Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, OpenAI SDK es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de OpenAI SDK
Explora más contenido relacionado con OpenAI SDK y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Conocer los modelos disponibles para text-to-speech en OpenAI y sus características. Identificar y seleccionar voces predefinidas adecuadas para distintos contextos y idiomas. Aplicar instrucciones en lenguaje natural para controlar el tono, velocidad y estilo de la voz. Configurar formatos de salida de audio según necesidades de calidad, latencia y dispositivo. Implementar estrategias de optimización para generación de audio en aplicaciones con múltiples solicitudes.