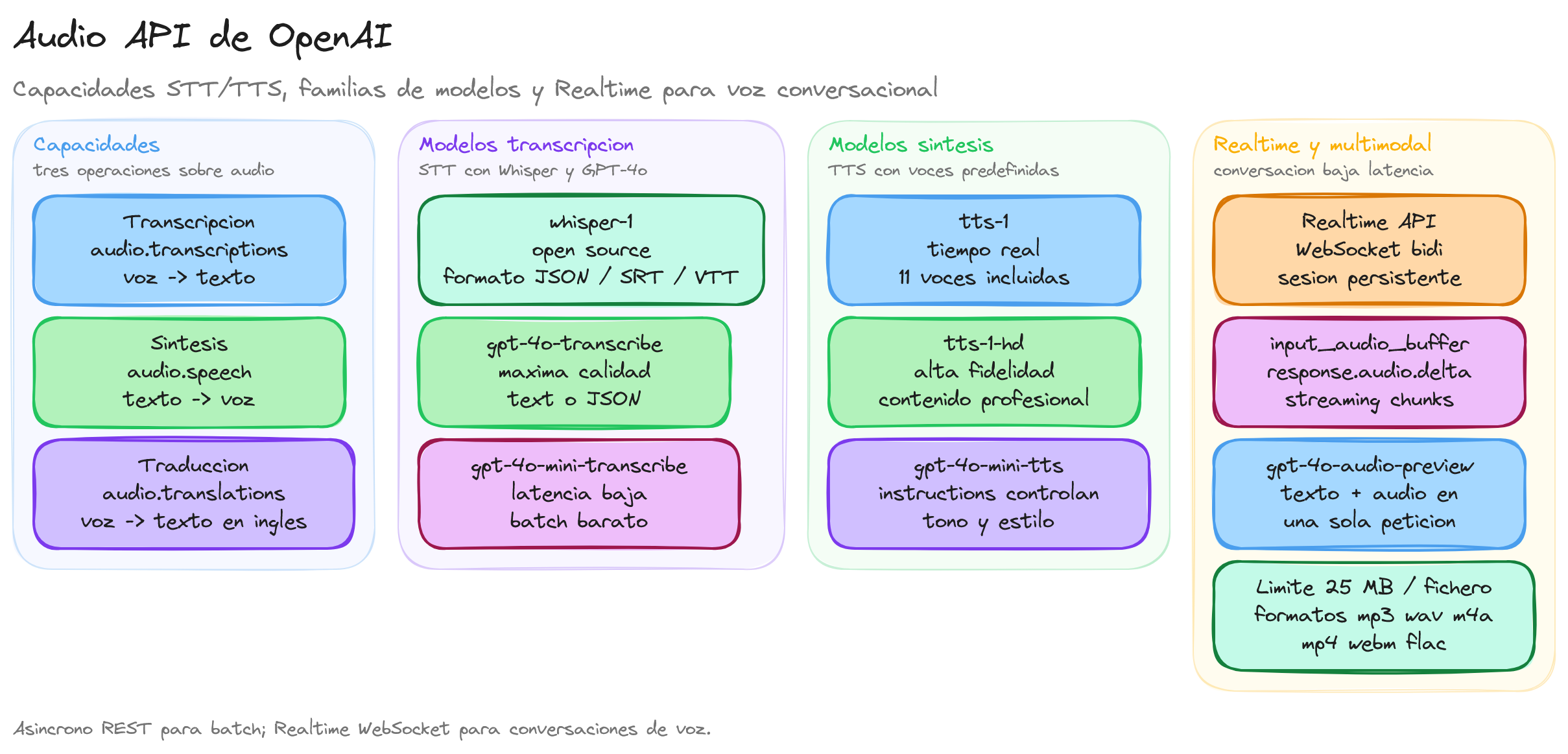
Audio API: capacidades y modelos disponibles
La Audio API de OpenAI representa una interfaz unificada para trabajar con contenido de audio mediante inteligencia artificial. Esta API proporciona acceso a múltiples capacidades de procesamiento de audio que van desde la comprensión hasta la generación, permitiendo crear aplicaciones que pueden escuchar, entender y responder con voz natural.
Capacidades principales
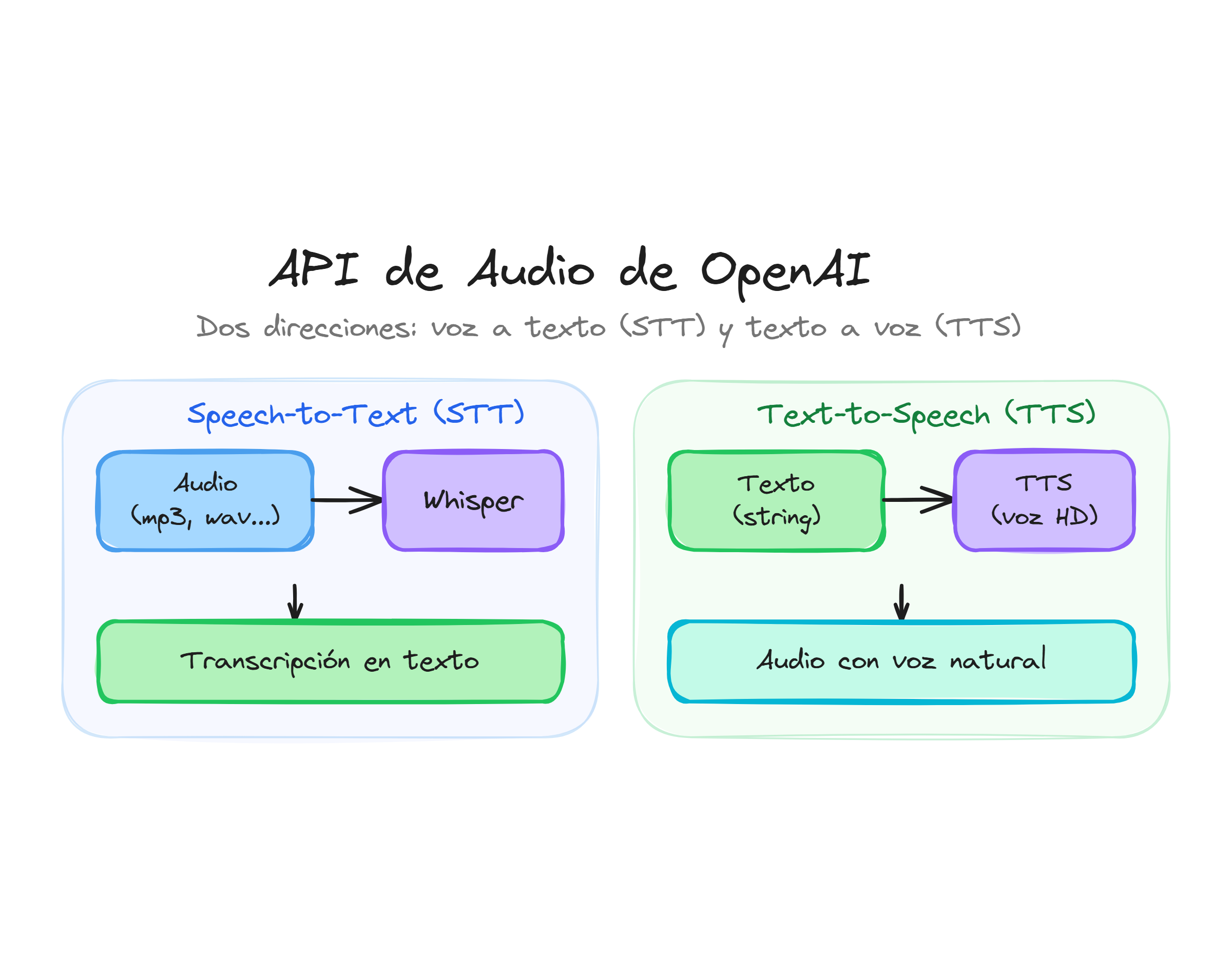
OpenAI ofrece tres capacidades fundamentales para el procesamiento de audio:
- Transcripción de audio: Convierte audio hablado en texto escrito con alta precisión
- Síntesis de voz: Transforma texto en audio hablado con voces naturales
- Traducción de audio: Traduce contenido hablado de un idioma a otro manteniendo el contexto
Estas capacidades pueden utilizarse de forma independiente para tareas específicas o combinarse para crear experiencias más complejas como agentes de voz conversacionales.
Arquitectura de APIs disponibles
OpenAI proporciona diferentes puntos de acceso según el tipo de aplicación que desees construir:
APIs de uso general:
- Chat Completions API: Permite entrada y salida de audio junto con texto, ideal para aplicaciones conversacionales
- Realtime API: Diseñada para interacciones en tiempo real con streaming de audio bidireccional
APIs especializadas:
- Transcription API: Específica para convertir audio a texto
- Speech API: Dedicada exclusivamente a síntesis de voz
- Translation API: Enfocada en traducción de contenido hablado
La elección entre APIs generales y especializadas depende del nivel de control y las funcionalidades adicionales que requiera tu aplicación.
Modelos de audio disponibles
OpenAI mantiene diferentes familias de modelos optimizados para distintas tareas de audio:
Importante: en audio siguen existiendo slugs especializados como
gpt-4o-transcribeogpt-4o-mini-tts. Aunque en generación de texto general se tienda a priorizar la familia GPT-5, en audio no conviene aplicar esa sustitución de forma automática porque estos modelos siguen estando ligados a endpoints y capacidades concretas.
Modelos multimodales:
- gpt-4o-audio-preview: Modelo principal para aplicaciones que requieren comprensión y generación de audio
- gpt-4o-mini: Versión optimizada para casos de uso que priorizan velocidad y eficiencia
Modelos especializados en transcripción:
- gpt-4o-transcribe: Modelo avanzado para transcripción de alta calidad
- gpt-4o-mini-transcribe: Versión ligera para transcripción rápida
- whisper-1: Modelo especializado en reconocimiento de voz multiidioma
Modelos de síntesis de voz:
- gpt-4o-mini-tts: Modelo moderno con capacidades de control tonal
- tts-1: Modelo estándar para síntesis de voz
- tts-1-hd: Versión de alta definición para mayor calidad de audio
Características técnicas
Los modelos de audio de OpenAI soportan múltiples formatos de archivo incluyendo WAV, MP3, FLAC y otros formatos estándar. La API maneja automáticamente la codificación base64 para la transmisión de datos de audio a través de HTTP.
Para aplicaciones que requieren baja latencia, los modelos soportan streaming tanto de entrada como de salida, permitiendo procesar audio en tiempo real sin esperar a que se complete la grabación completa.
Los modelos multimodales pueden procesar múltiples modalidades simultáneamente, lo que significa que pueden recibir tanto texto como audio en la misma solicitud y generar respuestas que combinen ambos tipos de contenido.
Consideraciones de rendimiento
Cada modelo está optimizado para diferentes escenarios de uso. Los modelos "mini" priorizan la velocidad de respuesta y el menor consumo de recursos, mientras que los modelos estándar ofrecen mayor precisión y calidad de salida.
La selección del modelo apropiado depende de factores como la latencia requerida, la calidad de audio necesaria, el volumen de procesamiento y las restricciones de recursos de tu aplicación.
Fuentes y referencias
Documentación oficial y recursos externos para profundizar en OpenAI SDK
Documentación oficial de OpenAI SDK
Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, OpenAI SDK es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de OpenAI SDK
Explora más contenido relacionado con OpenAI SDK y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Comprender las capacidades principales de la Audio API: transcripción, síntesis y traducción de audio. Identificar las diferentes APIs disponibles y su uso según el tipo de aplicación. Conocer las familias de modelos de audio y sus características específicas. Entender las características técnicas como formatos soportados y streaming en tiempo real. Evaluar criterios para seleccionar el modelo de audio adecuado según necesidades de rendimiento y calidad.