La API Responses
La API Responses es la interfaz recomendada de OpenAI para trabajar con modelos de texto, razonamiento y herramientas desde Python. Su diseño es más simple que APIs anteriores porque concentra la interacción en unos pocos conceptos: modelo, entrada y respuesta.
En la práctica, si hoy empiezas una integración nueva con OpenAI para texto, lo normal es partir de
client.responses.create().
Estructura básica
La forma más sencilla de usar la API consiste en indicar un modelo y un input. El texto generado queda accesible en response.output_text.
from openai import OpenAI
client = OpenAI()
response = client.responses.create(
model="gpt-5.4",
input="Explica qué es la fotosíntesis en términos simples."
)
print(response.output_text)
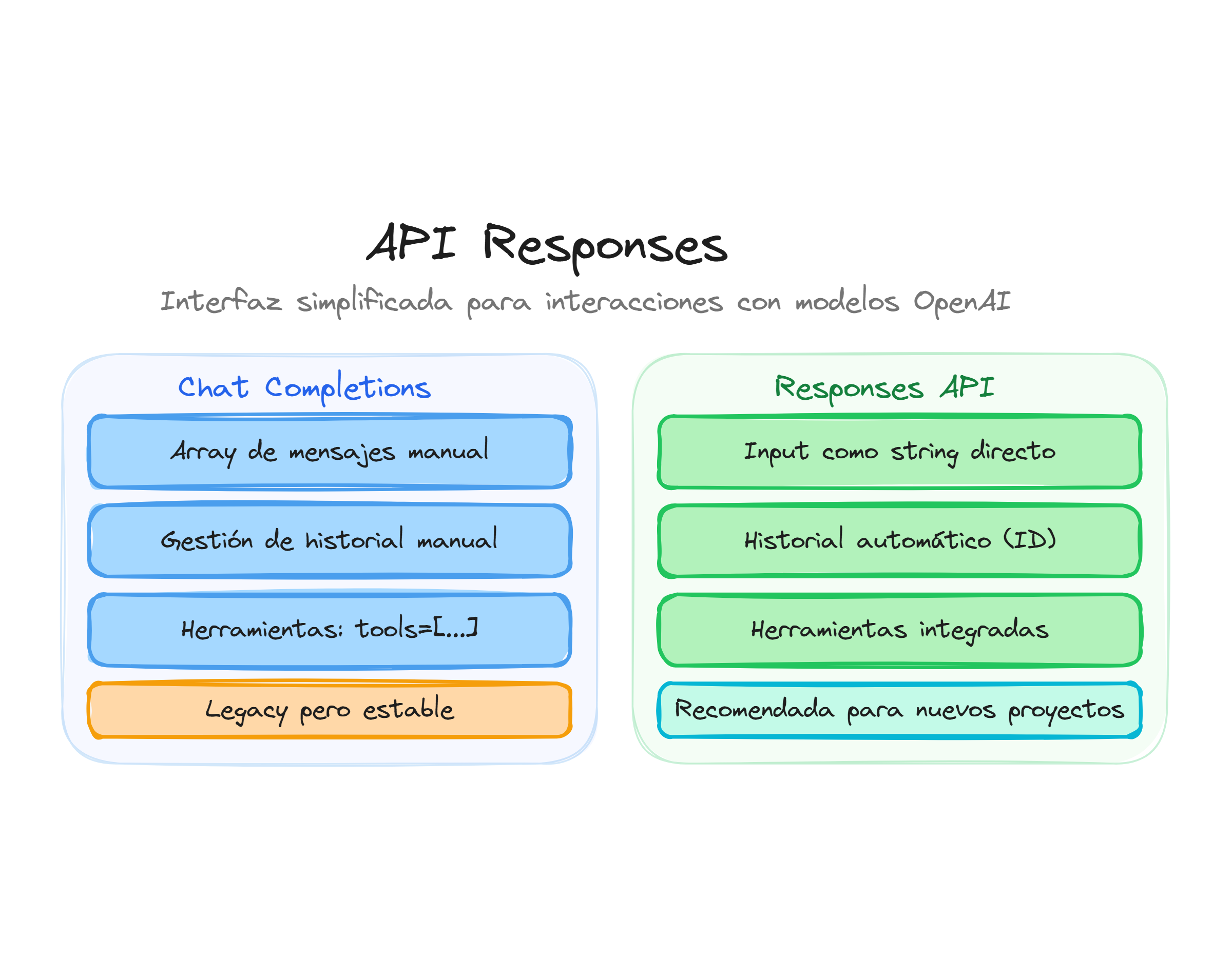

El siguiente diagrama compara las dos APIs de generación de texto del SDK openai 1.55+: la clásica chat.completions.create() con array de messages y la moderna responses.create() con input simple, parámetros como previous_response_id para hilos persistentes y soporte nativo de tools y reasoning.
flowchart TB
SDK["openai SDK 1.55+"]
subgraph CC["chat.completions (legacy)"]
CC_IN["messages: list["role, content"]"]
CC_PARAMS["temperature, max_tokens"]
CC_OUT["choices[0].message.content"]
end
subgraph RESP["responses (recomendada)"]
R_IN["input: str | list[message]"]
R_PARAMS["instructions, reasoning"]
R_TOOLS["tools nativos"]
R_PERSIST["previous_response_id"]
R_OUT["output_text + output[]"]
end
SDK --> CC
SDK --> RESP
CC_IN --> CC_PARAMS --> CC_OUT
R_IN --> R_PARAMS
R_PARAMS --> R_TOOLS
R_PARAMS --> R_PERSIST
R_TOOLS --> R_OUT
R_PERSIST --> R_OUT
El campo input puede ser una cadena simple, pero también puede ser una lista de mensajes si necesitas conservar varios turnos de conversación dentro de la misma llamada.
response = client.responses.create(
model="gpt-5.4-mini",
input=[
{"role": "user", "content": "Knock knock."},
{"role": "assistant", "content": "Who's there?"},
{"role": "user", "content": "Orange."}
]
)
print(response.output_text)
Instrucciones y estado conversacional
Además de input, la API permite fijar instrucciones globales con instructions. Este campo cumple el papel de un mensaje de sistema o developer que orienta el comportamiento del modelo.
response = client.responses.create(
model="gpt-5.4",
instructions="Responde con tono docente y ejemplos breves.",
input="¿Qué diferencia hay entre una lista y una tupla en Python?"
)
Si quieres continuar una conversación de forma explícita, puedes reutilizar previous_response_id en la siguiente llamada.
first = client.responses.create(
model="gpt-5.4-mini",
input="Dame tres ideas de proyectos con FastAPI."
)
second = client.responses.create(
model="gpt-5.4-mini",
previous_response_id=first.id,
input="Ahora reduce esas ideas para que pueda hacerlas en un fin de semana."
)
print(second.output_text)
instructionsdefine el marco de comportamiento yprevious_response_idpermite enlazar turnos sin reconstruir manualmente todo el historial.
Parámetros útiles en Responses
Longitud, razonamiento y estilo
En la API Responses, el parámetro actual para limitar la longitud de salida es max_output_tokens. Este campo controla cuántos tokens de salida puede generar el modelo.
response = client.responses.create(
model="gpt-5.4",
input="Resume en cinco líneas qué es una API REST.",
max_output_tokens=120
)
print(response.output_text)
También puedes ajustar el nivel de razonamiento o la extensión verbal de la salida con objetos como reasoning y text.
response = client.responses.create(
model="gpt-5.4",
reasoning={"effort": "medium"},
text={"verbosity": "low"},
input="Propón una estrategia para migrar una API monolítica a microservicios."
)
Sampling cuando el modelo lo soporta
Parámetros como temperature y top_p siguen siendo útiles para controlar la aleatoriedad y la diversidad de la respuesta, pero conviene recordar que no todos los modelos ni todas las configuraciones los aceptan.
En la documentación actual de OpenAI, temperature y top_p están soportados en GPT-5.4 cuando reasoning.effort está en none. En cambio, los modelos GPT-5 anteriores de la familia principal y sus variantes ligeras pueden rechazar estos campos.
response = client.responses.create(
model="gpt-5.4",
reasoning={"effort": "none"},
input="Escribe un título creativo para un artículo sobre automatización.",
temperature=0.8,
top_p=0.9
)
Un valor bajo de temperature produce respuestas más deterministas. Un valor alto genera texto más creativo y menos predecible. Con top_p haces algo parecido, pero mediante muestreo por probabilidad acumulada.
Metadatos de la respuesta
La respuesta no contiene solo texto. También expone datos útiles para monitorización, control de costes y trazabilidad.
response = client.responses.create(
model="gpt-5.4",
input="Resume los beneficios de usar pruebas automatizadas."
)
print("Texto:", response.output_text)
print("ID:", response.id)
print("Modelo:", response.model)
print("Input tokens:", response.usage.input_tokens)
print("Output tokens:", response.usage.output_tokens)
print("Total:", response.usage.total_tokens)
La propiedad usage es la fuente principal para consultar el consumo de tokens. En la API Responses, los nombres actuales son input_tokens, output_tokens y total_tokens.
Si quieres saber cuánto consume realmente tu aplicación, acostúmbrate a inspeccionar
response.usageen lugar de estimarlo solo a ojo.
Elegir modelo en Responses
La elección del modelo depende del tipo de trabajo que vas a realizar:
gpt-5.4: opción general para trabajo importante, razonamiento complejo, conocimiento amplio y tareas de código o agentes.gpt-5.4-mini: equilibrio entre coste, velocidad y capacidad para chat y tareas bien definidas.gpt-5.4-nano: opción de alto rendimiento para clasificación, resumido simple e instrucciones directas a gran escala.
analysis = client.responses.create(
model="gpt-5.4",
input="Analiza riesgos técnicos de una migración a Kubernetes."
)
support = client.responses.create(
model="gpt-5.4-mini",
input="Redacta una respuesta breve para soporte técnico."
)
routing = client.responses.create(
model="gpt-5.4-nano",
input="Clasifica este mensaje como 'factura', 'soporte' o 'ventas'."
)
Manejo básico de errores
Cuando integres la API en una aplicación real, comprueba que response.output_text contiene texto antes de procesarlo y captura excepciones del SDK.
try:
response = client.responses.create(
model="gpt-5.4",
input="Explica la diferencia entre SQL y NoSQL.",
max_output_tokens=180
)
if response.output_text:
print(response.output_text)
else:
print("La respuesta no contiene texto utilizable.")
except Exception as exc:
print(f"Error al llamar a OpenAI: {exc}")
Esta validación evita asumir que toda llamada produce siempre una cadena lista para usar y te obliga a tratar la respuesta como una estructura completa, no solo como texto.
Fuentes y referencias
Documentación oficial y recursos externos para profundizar en OpenAI SDK
Documentación oficial de OpenAI SDK
Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, OpenAI SDK es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de OpenAI SDK
Explora más contenido relacionado con OpenAI SDK y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Comprender la estructura básica y funcionamiento de la API Responses. Aprender a configurar parámetros avanzados como temperature y max_tokens. Saber manejar diferentes tipos de contenido y solicitudes con la API. Conocer cómo acceder y utilizar metadatos de las respuestas para optimización. Implementar gestión de errores para asegurar robustez en las aplicaciones.