
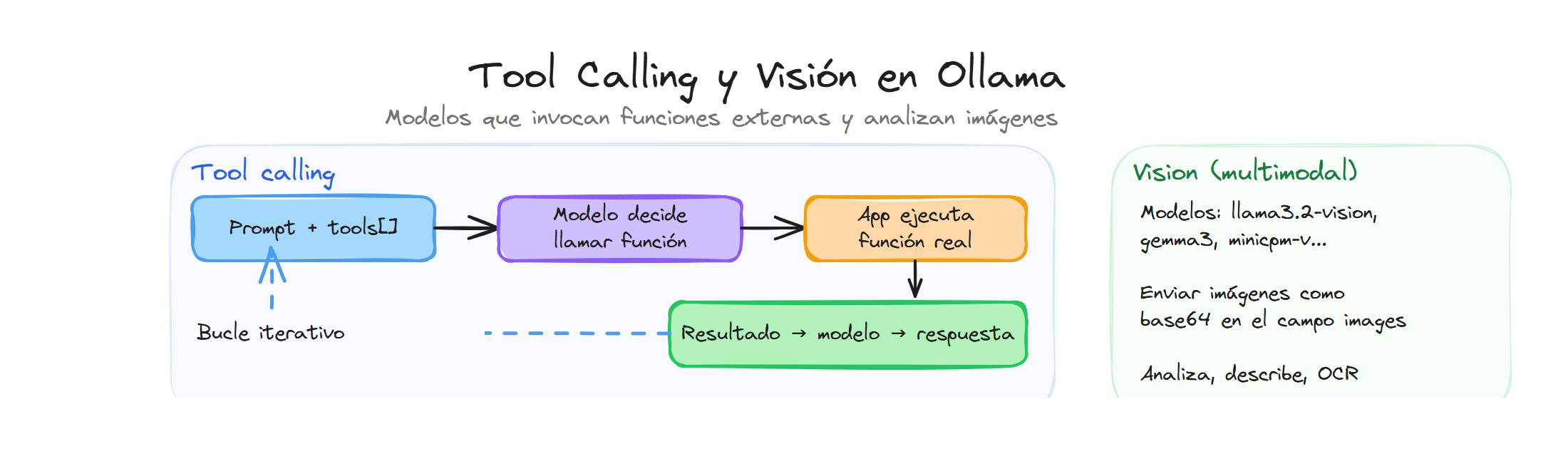
Tool calling (llamadas a herramientas)
Tool calling (o function calling) permite que el modelo invoque herramientas definidas por ti y use su resultado para elaborar la respuesta. Por ejemplo, el modelo puede decidir llamar a una función "obtener_temperatura(ciudad)" y, con el valor devuelto, contestar al usuario. Así puedes conectar el LLM con APIs externas, bases de datos o cualquier lógica que implementes en tu código.
En Ollama esto se hace pasando un array tools en la petición a /api/chat. Cada herramienta se describe con type, function, name, description y parameters (schema JSON). Si el modelo decide usar una herramienta, en la respuesta aparecerá message.tool_calls con el nombre de la función y los argumentos. Tú ejecutas la función, añades el resultado como mensaje con rol tool y vuelves a llamar a /api/chat con el historial actualizado para obtener la respuesta final.
Ejemplo mínimo en curl: definir una herramienta y enviar un mensaje. La respuesta puede contener tool_calls que debes resolver y reenviar.
curl -s http://localhost:11434/api/chat -H "Content-Type: application/json" -d '{
"model": "qwen3",
"messages": [{"role": "user", "content": "¿Qué temperatura hace en Nueva York?"}],
"stream": false,
"tools": [
{
"type": "function",
"function": {
"name": "get_temperature",
"description": "Obtener la temperatura actual de una ciudad",
"parameters": {
"type": "object",
"required": ["city"],
"properties": {
"city": {"type": "string", "description": "Nombre de la ciudad"}
}
}
}
}
]
}'
Si la respuesta incluye tool_calls, añades al historial el mensaje del asistente y un mensaje de rol tool con el resultado, y repites la llamada. En Python, puedes pasar funciones directamente y la librería construye el schema a partir de la firma y los docstrings:
from ollama import chat
def get_temperature(city: str) -> str:
"""Obtener la temperatura actual de una ciudad."""
temperaturas = {"Nueva York": "22°C", "Londres": "15°C", "Tokio": "18°C"}
return temperaturas.get(city, "Desconocido")
messages = [{"role": "user", "content": "¿Qué temperatura hace en Nueva York?"}]
response = chat(model="qwen3", messages=messages, tools=[get_temperature], think=True)
messages.append(response.message)
if response.message.tool_calls:
call = response.message.tool_calls[0]
result = get_temperature(**call.function.arguments)
messages.append({"role": "tool", "tool_name": call.function.name, "content": result})
final = chat(model="qwen3", messages=messages, tools=[get_temperature], think=True)
print(final.message.content)
No todos los modelos soportan tool calling. Modelos como Qwen 3, Llama 3.1, Command-R+ o Mistral Nemo suelen soportarlo. Consulta la documentación del modelo o prueba con
toolsy comprueba si devuelvetool_calls.
Algunos modelos pueden devolver varias llamadas a herramientas en una misma respuesta. En ese caso debes ejecutar todas, añadir un mensaje tool por cada resultado (respetando el orden) y luego una única llamada a chat con todo el historial para que el modelo integre los resultados y responda.
Visión: modelos que analizan imágenes
Los modelos de visión aceptan imágenes además de texto. Puedes enviar una o varias imágenes en un mensaje y preguntar por su contenido (qué hay en la imagen, describirla, extraer texto, comparar imágenes, etc.). Es útil para descripción de fotos, OCR, clasificación visual o asistentes que combinan texto e imagen.
En la API, las imágenes se envían en el propio mensaje mediante el array images. En la API REST cada imagen va en base64. Con los SDK de Python o JavaScript puedes pasar rutas de archivo, URLs o bytes, y la librería se encarga del formato.
Ejemplo con curl (primero codificar la imagen en base64):
IMG=$(base64 < imagen.jpg | tr -d '\n')
curl -X POST http://localhost:11434/api/chat \
-H "Content-Type: application/json" \
-d '{
"model": "gemma3",
"messages": [{
"role": "user",
"content": "¿Qué hay en esta imagen?",
"images": ["'"$IMG"'"]
}],
"stream": false
}'
En Python, pasando la ruta del archivo:
from ollama import chat
response = chat(
model='gemma3',
messages=[{
'role': 'user',
'content': '¿Qué hay en esta imagen? Responde en una frase.',
'images': ['ruta/a/imagen.jpg'],
}],
)
print(response.message.content)
Desde la CLI puedes usar la app de escritorio o invocar con la ruta del archivo, por ejemplo: ollama run gemma3 ./imagen.png ¿qué hay aquí?
En la aplicación de escritorio puedes adjuntar una imagen y preguntar por su contenido de forma visual.
Modelos típicos con visión son Llama 3.2 Vision, Gemma 3, Qwen2.5-VL o Mistral con soporte multimodal. Descárgalos con
ollama pull(por ejemploollama pull gemma3) antes de usarlos.
Combinar tools y visión
Puedes usar en la misma conversación tools y vision: el modelo recibe mensajes con texto e imágenes y, si tiene tool calling, puede decidir llamar a herramientas (por ejemplo búsqueda web o una API) y luego responder. El flujo es el mismo que solo con tools: si la respuesta trae tool_calls, ejecutas las herramientas, añades los resultados como mensajes tool y vuelves a llamar a chat hasta que la respuesta no contenga más tool calls.
flowchart LR
U[Mensaje user + images] --> C["/api/chat"]
C --> M[Modelo]
M --> R{tool_calls?}
R -->|Sí| E[Ejecutar tools]
E --> T[Mensaje tool]
T --> C
R -->|No| F[Respuesta final]
El usuario envía mensaje (y opcionalmente imágenes). El modelo puede devolver tool_calls, y en ese caso se ejecutan las herramientas y se reenvía el resultado como mensaje tool antes de obtener la respuesta final.
Modelos recomendados para cada capacidad
No todos los modelos soportan tool calling y visión. Esta tabla resume los modelos más habituales y sus capacidades:
| Modelo | Tool calling | Visión | Tamaños disponibles | |--------|:----------:|:------:|---------------------| | Qwen 3 | Sí | No | 0.6B - 235B | | Llama 3.2 | Sí | Sí (variante Vision) | 1B, 3B, 11B, 90B | | Gemma 3 | No | Sí | 1B, 4B, 12B, 27B | | Mistral Nemo | Sí | No | 12B | | GLM-4.7-Flash | Sí | Sí | 30B |
Consulta la web de Ollama (ollama.com/search) y filtra por las etiquetas Tools y Vision para ver el catálogo actualizado. Nuevos modelos con estas capacidades se publican con frecuencia.
Tool calling se configura con el array tools y se completa el flujo procesando tool_calls y reenviando resultados con rol tool. Visión se usa incluyendo el array images en los mensajes y eligiendo un modelo que soporte multimodal.

Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, Ollama es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de Ollama
Explora más contenido relacionado con Ollama y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Usar tool calling (llamadas a herramientas) desde la API de chat y aprovechar modelos con visión para analizar imágenes junto con el texto.
Cursos que incluyen esta lección
Esta lección forma parte de los siguientes cursos estructurados con rutas de aprendizaje