
Qué es el thinking en los modelos
Algunos modelos de lenguaje están entrenados para mostrar un rastro de razonamiento antes de dar la respuesta final. En lugar de generar solo el texto de salida, emiten primero un bloque de thinking (pensamiento interno) y después el content (respuesta al usuario). Eso permite que el modelo "piense paso a paso" en tareas de lógica, matemáticas o razonamiento complejo, lo que suele mejorar la precisión y la trazabilidad del proceso.
En Ollama, los modelos que soportan esta capacidad exponen un campo thinking en la respuesta, distinto del campo content (o response en /api/generate). Puedes usar el thinking para auditar los pasos del modelo, mostrarlo en una interfaz o ocultarlo cuando solo te interese la respuesta final.
El thinking está pensado para tareas que requieren razonamiento extendido. En preguntas triviales o muy cortas puede no aportar mucho, y en problemas de lógica, matemáticas o análisis detallado suele marcar la diferencia.
Modelos que soportan thinking
No todos los modelos de la biblioteca de Ollama incluyen thinking. Los que lo hacen suelen estar etiquetados en la web de Ollama bajo la categoría de thinking models. Algunos ejemplos habituales son:
- DeepSeek R1 y DeepSeek-v3.1: modelos orientados a razonamiento.
- Qwen 3: soporta thinking con el parámetro booleano
think. - GPT-OSS: en lugar de
true/false, usa niveleslow,mediumohighpara controlar la longitud del rastro, y el thinking no se puede desactivar por completo.
Puedes consultar el listado actual en la sección de thinking models en el sitio de Ollama. Antes de usar thinking en producción, comprueba que el modelo que tienes instalado (por ejemplo con ollama list) soporte esta capacidad.
Activar thinking en la API
En los endpoints /api/chat y /api/generate puedes activar el thinking añadiendo el campo think en el cuerpo de la petición. La mayoría de modelos aceptan un booleano (true o false). En la respuesta, el razonamiento va en message.thinking (chat) o thinking (generate), y la respuesta final en message.content o response.
Ejemplo con curl y /api/chat:
curl http://localhost:11434/api/chat -d '{
"model": "qwen3",
"messages": [{
"role": "user",
"content": "¿Cuántas letras r hay en la palabra strawberry?"
}],
"think": true,
"stream": false
}'
En Python con la librería oficial:
from ollama import chat
response = chat(
model='qwen3',
messages=[{'role': 'user', 'content': '¿Cuántas letras r hay en strawberry?'}],
think=True,
stream=False,
)
print('Razonamiento:', response.message.thinking)
print('Respuesta:', response.message.content)
Si usas streaming, los fragmentos de thinking y de content pueden llegar entremezclados. El primer fragmento que tenga message.thinking indica que ha empezado el bloque de razonamiento. Cuando empiece a llegar message.content, puedes cambiar a mostrar la respuesta final. Así puedes animar el "pensamiento" en la interfaz y luego la contestación.
Para GPT-OSS debes usar
thinkcon el valor"low","medium"o"high". Pasartrueofalseno tiene efecto en ese modelo.
Uso desde la CLI
Desde la línea de comandos puedes activar o desactivar el thinking con las opciones de ollama run:
- Activar thinking en una ejecución:
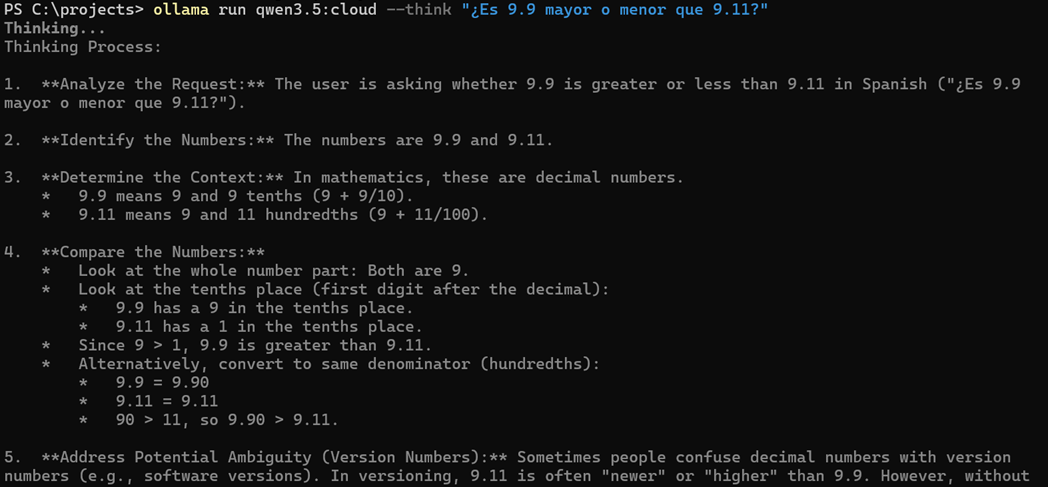
ollama run deepseek-r1 --think "¿Es 9.9 mayor o menor que 9.11?" - Desactivar thinking:
ollama run deepseek-r1 --think=false "Resume este artículo en una frase." - Ocultar el thinking pero seguir usándolo internamente:
ollama run deepseek-r1 --hidethinking "¿Es 9.9 mayor o menor que 9.11?"(útil cuando quieres la precisión del razonamiento pero no mostrar el texto al usuario).
Dentro de una sesión interactiva (ollama run modelo), puedes alternar con /set think y /set nothink.
flowchart LR
U[Usuario] -->|Prompt| C[Cliente]
C -->|think: true| S[Servidor]
S --> M[Modelo thinking]
M --> S
S -->|thinking + content| C
C --> U
El cliente envía la petición con think activado. El servidor ejecuta el modelo y devuelve tanto el thinking como el content, de modo que el cliente puede presentarlos por separado.
Thinking con streaming
Cuando usas thinking con streaming activado, los fragmentos de la respuesta llegan en orden: primero los fragmentos del bloque thinking y después los del bloque content. En la API, cada fragmento JSON incluye el campo correspondiente (message.thinking o message.content), lo que permite mostrar el razonamiento en una sección separada de la interfaz mientras se genera.
En Python con streaming:
from ollama import chat
stream = chat(
model='qwen3',
messages=[{'role': 'user', 'content': '¿Es 9.9 mayor que 9.11?'}],
think=True,
stream=True,
)
for chunk in stream:
if chunk.message.thinking:
print('[Razonamiento]', chunk.message.thinking, end='')
if chunk.message.content:
print('[Respuesta]', chunk.message.content, end='')
Esta separación permite construir interfaces donde el razonamiento se muestra plegado o en un panel lateral, y la respuesta final se destaca. En aplicaciones donde no quieres mostrar el razonamiento pero sí quieres que el modelo lo use internamente, la opción --hidethinking de la CLI o la decisión de ignorar el campo thinking en la respuesta de la API cumplen ese propósito.
Cuándo usar thinking y cuándo no
El thinking es especialmente útil en:
- Problemas de lógica y matemáticas: contar letras, resolver ecuaciones, evaluar condiciones complejas.
- Análisis paso a paso: descomponer un problema en partes, comparar opciones, justificar una decisión.
- Tareas de código: depurar errores, diseñar algoritmos o explicar el flujo de un programa.
- Auditoría y trazabilidad: cuando necesitas que el modelo muestre cómo llegó a la respuesta para poder verificar el razonamiento.
En cambio, thinking no aporta mucho valor en tareas sencillas como traducir una frase, saludar o responder preguntas factuales directas. Además, activar thinking consume más tokens y aumenta la latencia, porque el modelo genera texto adicional para el bloque de razonamiento. En aplicaciones donde la velocidad es prioritaria y las preguntas son simples, desactivar thinking mejora el rendimiento.
En la API y en la CLI, el thinking suele estar activado por defecto para los modelos que lo soportan. Si no quieres el rastro de razonamiento, desactívalo explícitamente con think: false o --think=false.

Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, Ollama es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de Ollama
Explora más contenido relacionado con Ollama y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Entender qué son los modelos con thinking/reasoning, cuáles los soportan en Ollama y cómo activarlos desde la API y la CLI para aprovechar el razonamiento extendido.
Cursos que incluyen esta lección
Esta lección forma parte de los siguientes cursos estructurados con rutas de aprendizaje