
Modelos open source en Ollama
Ollama no entrena modelos propios: actúa como runtime para ejecutar modelos en formato compatible (por ejemplo GGUF) publicados por laboratorios y comunidades. El catálogo incluye decenas de modelos de Meta (Llama), Google (Gemma), Mistral AI, Alibaba (Qwen), Microsoft (Phi) y otros. Todos ellos son open source o con licencias que permiten uso local y, en muchos casos, comercial. La lista actualizada de modelos está en ollama.com/search, donde puedes filtrar por etiquetas como Cloud, Embedding, Vision, Tools o Thinking.
Conocer las familias principales y cómo se comparan te ayuda a elegir el modelo adecuado para cada tarea (chat general, código, razonamiento, multilingüe, visión, etc.).
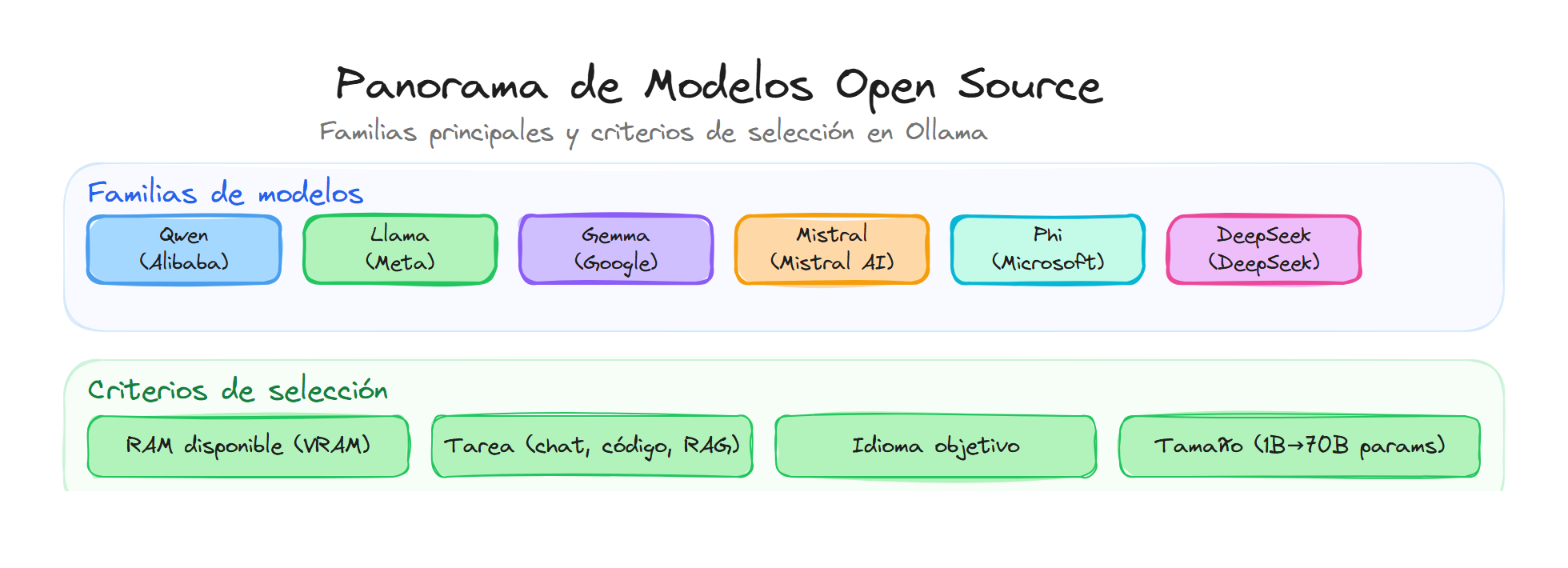
Familias principales
Las familias más representativas en el catálogo de Ollama son:
-
Qwen (Alibaba): la serie Qwen 3.5 y Qwen3 incluye modelos multimodales (visión, herramientas, razonamiento) en tamaños desde 0.8B hasta 122B. Qwen3-Coder-Next está orientado a código y flujos agentes. Qwen3-VL es la línea de visión-lenguaje. Qwen3-Embedding se usa para embeddings. Muy presentes en benchmarks de programación y tareas técnicas.
-
Llama (Meta): modelos como Llama 3.x y variantes. Buenos en conversación, instrucciones y multilingüe, con tamaños desde 8B hasta 70B+ parámetros. Los más grandes exigen más RAM y suelen usarse con GPU.
-
Gemma (Google): línea derivada de la experiencia de Google. Gemma 3 y variantes como Translategemma (traducción sobre Gemma 3) ofrecen buenas relaciones calidad/tamaño para entornos con recursos limitados (4B, 12B, 27B).
-
Mistral (Mistral AI): Ministral 3 está pensado para despliegue en edge (3B, 8B, 14B) con soporte de visión y herramientas. Mistral 7B y Mixtral siguen siendo opciones habituales por velocidad y calidad en tareas generales y de código.
-
LFM2 / LFM2.5 (hybrid): familias híbridas para despliegue en dispositivo. LFM2.5-Thinking (1.2B) y LFM2 (24B) ofrecen razonamiento y herramientas en tamaños contenidos.
-
GLM (Z.ai): GLM-4.7-Flash (30B) y GLM-5 (744B total, 40B activos) destacan en razonamiento y tareas agentes. GLM-5 está disponible sobre todo vía cloud. También hay modelos especializados como GLM-OCR para documentos.
-
Nemotron (NVIDIA): Nemotron 3 Super (120B MoE, 12B activos) para aplicaciones multiagente, y Nemotron 3 Nano (30B) para agentes eficientes. Incluyen herramientas y razonamiento.
-
Phi (Microsoft), DeepSeek, Granite (IBM), Devstral, Kimi, RNJ y otras familias completan un catálogo muy amplio. Conviene consultar ollama.com/search para ver la oferta actual y filtrar por capacidad (vision, tools, thinking, embedding, cloud).
Cada familia tiene variantes por tamaño (0.8B, 3B, 8B, 24B, 80B, 122B…) y por especialización (código, visión, razonamiento, embeddings). Los nombres en Ollama siguen patrones como qwen3.5, qwen3-coder-next, ministral-3, llama3.2, gemma2, glm-5, etc.
La elección depende del hardware (RAM, GPU), del idioma y del tipo de tarea (chat, código, razonamiento, embeddings). No hay un único modelo mejor para todo, así que conviene probar varios en tu caso de uso.
flowchart LR
A["Elegir modelo"] --> B{"Hardware disponible"}
B -->|"8-16 GB RAM"| C["Modelos pequeños<br/>≤ 7B parámetros"]
B -->|"16-32 GB / GPU"| D["Modelos medianos<br/>13B - 34B"]
B -->|"GPU potente o Cloud"| E["Modelos grandes<br/>70B+"]
C --> F{"Tipo de tarea"}
D --> F
E --> F
F -->|"Chat general"| G["Llama, Qwen, Gemma"]
F -->|"Código"| H["Qwen3-Coder, Devstral"]
F -->|"Razonamiento"| I["GLM, Nemotron"]
Cómo comparar modelos: rankings y benchmarks
Los benchmarks públicos permiten comparar rendimiento en tareas estándar (razonamiento, código, comprensión, etc.) sin tener que probar todos los modelos a mano. Una referencia habitual es artificialanalysis.ai, que publica rankings y análisis de modelos open source y propietarios según distintos criterios (capacidad general, código, razonamiento, etc.).
Consultar estos rankings te ayuda a:
-
Reducir la lista de candidatos a unos pocos modelos por familia o por tamaño.
-
Entender qué modelos destacan en código, razonamiento o multilingüe antes de descargarlos.
-
Contrastar con la documentación oficial de cada laboratorio (Meta, Mistral, Qwen, etc.) para licencias y recomendaciones de uso.
No conviene obsesionarse con un único ranking: los resultados dependen de las métricas y de los tests elegidos. Úsalos como guía y valida siempre con pruebas reales en tus propios casos de uso.
Tamaños y recursos
Los modelos se suelen describir por número de parámetros (7B, 13B, 70B…). A más parámetros, en general más capacidad, pero también más memoria y tiempo de inferencia. Ollama utiliza cuantización (pesos en precisión reducida) para que modelos grandes puedan ejecutarse en máquinas con menos RAM. A cambio, puede haber una ligera pérdida de calidad respecto al modelo en precisión completa.
En la práctica:
-
Modelos pequeños (alrededor de 7B parámetros o menos) pueden correr solo con CPU en equipos con 8–16 GB de RAM.
-
Modelos medianos (13B–34B) suelen requerir 16–32 GB de RAM o una GPU con suficiente VRAM.
-
Modelos grandes (70B, 80B, 120B y superiores) casi siempre requieren GPU potente o mucho RAM, aunque muchos están disponibles en Ollama Cloud para usarlos sin ese hardware local.
Los requisitos concretos y la instalación dependen del sistema y del modelo elegido.
Modelos locales frente a modelos en la nube
En Ollama puedes usar:
-
Modelos locales: descargados y ejecutados en tu máquina. Dependen de tu hardware y de tu ancho de banda solo en la descarga inicial.
-
Modelos en la nube (Ollama Cloud): se ejecutan en servidores de Ollama y requieren cuenta y API key. Son útiles cuando no tienes recursos suficientes en local o quieres probar modelos muy grandes sin invertir en hardware.
La misma interfaz (por ejemplo, el nombre del modelo con sufijo :cloud) permite elegir entre uno y otro sin cambiar de herramienta.
El panorama de modelos en Ollama abarca Qwen 3.5, Llama, Gemma 3, Ministral, GLM, Nemotron y muchas otras familias. Para ver el catálogo al día y filtrar por tipo (visión, herramientas, razonamiento, embeddings, cloud), usa ollama.com/search. Sitios como artificialanalysis.ai ofrecen rankings y comparativas para orientar la elección. El tamaño del modelo (desde menos de 1B hasta más de 100B) y la especialización (código, visión, razonamiento, multilingüe) condicionan los recursos necesarios y el tipo de tareas donde cada uno destaca.

Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, Ollama es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de Ollama
Explora más contenido relacionado con Ollama y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Conocer las principales familias de modelos open source disponibles en Ollama y criterios para elegir y comparar modelos.
Cursos que incluyen esta lección
Esta lección forma parte de los siguientes cursos estructurados con rutas de aprendizaje