
Qué es Ollama
Ollama es una plataforma que permite ejecutar modelos de lenguaje grandes (LLM) en tu propio equipo o en infraestructura en la nube gestionada por Ollama. Simplifica la descarga, la configuración y el arranque de modelos open source (Llama, Mistral, Qwen, Gemma y muchos otros) sin necesidad de gestionar servidores de inferencia ni APIs de terceros.
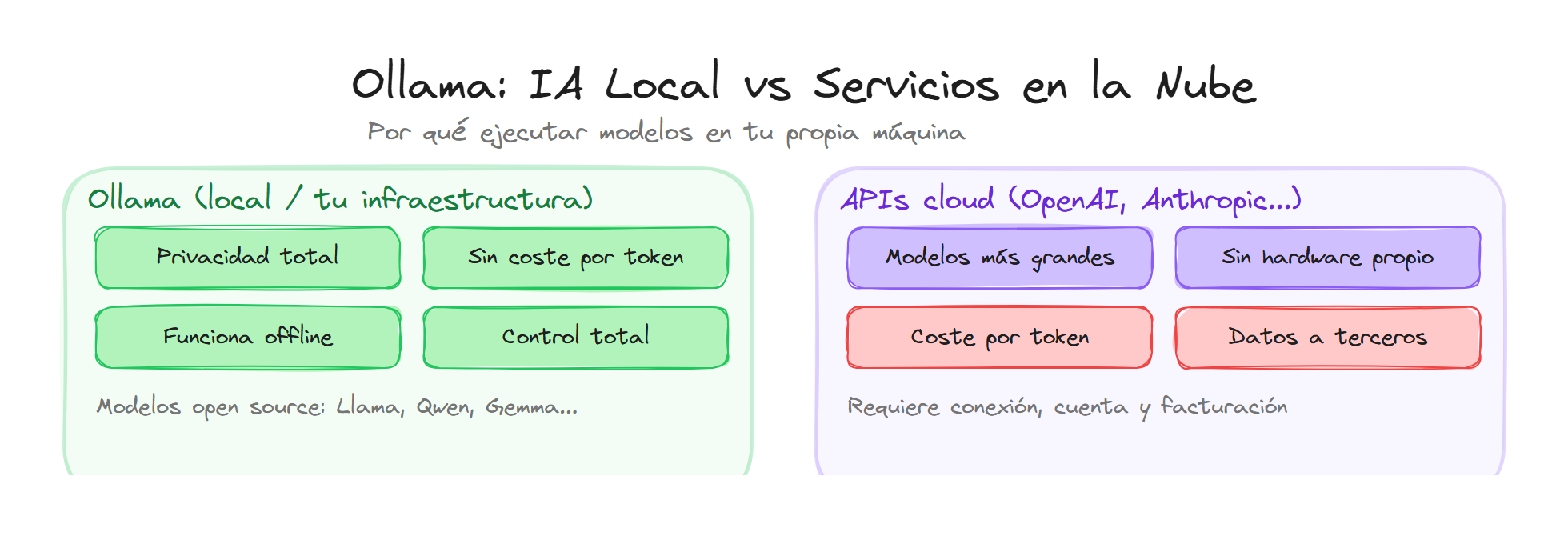
A diferencia de servicios cerrados que solo exponen una API remota, Ollama te da control sobre dónde corre el modelo: en tu portátil, en un servidor propio o, si lo eliges, usando los modelos alojados en Ollama Cloud. Ese rango de opciones es lo que define su valor para desarrolladores y equipos que priorizan privacidad, coste o trabajo sin conexión.
El problema que resuelve
Usar LLMs solo a través de APIs de proveedores externos implica dependencia de su disponibilidad, sus precios y sus políticas de datos. Los datos que envías para generar respuestas salen de tu red, y en entornos sensibles o regulados eso puede ser inaceptable. Además, el coste por token puede crecer rápido en proyectos con mucho uso.
Ollama aborda esto de dos maneras complementarias:
-
Ejecución local: el modelo corre en tu hardware. Los datos no salen de tu máquina y no pagas por uso una vez instalado, y puedes trabajar sin internet después de haber descargado el modelo.
-
Ollama Cloud: si no tienes GPU o prefieres no gestionar infraestructura, puedes usar modelos alojados por Ollama con autenticación y API key, manteniendo una interfaz y flujo de trabajo coherentes con el uso local.
Así puedes elegir el mismo ecosistema (CLI, API, aplicaciones) tanto para desarrollo en local como para despliegues o pruebas en la nube.
flowchart TD
A{"¿Dónde ejecutar el modelo?"} -->|"Privacidad, sin coste<br/>por token, sin conexión"| B["Ejecución local<br/>tu CPU / GPU"]
A -->|"Sin GPU, escalar,<br/>modelos grandes"| C["Ollama Cloud<br/>servidores remotos"]
B --> D["Misma CLI, API<br/>y convenciones"]
C --> D
Ventajas de ejecutar en local
Cuando el modelo corre en tu máquina, obtienes varias ventajas claras:
-
Privacidad: las conversaciones y los prompts no se envían a servidores externos. Resulta adecuado para código propietario, datos internos o entornos con requisitos de confidencialidad.
-
Control del coste: no hay facturación por token ni suscripciones por uso. El coste está en el hardware (que ya puede estar disponible) y en la electricidad.
-
Uso sin conexión: una vez descargado el modelo, puedes usarlo sin internet. Útil en desplazamientos, entornos aislados o cuando la conectividad es limitada.
-
Latencia predecible: la inferencia es local, sin depender de la red. La respuesta depende de tu CPU/GPU, no del ancho de banda ni de la carga de un servicio remoto.
Ejecutar en local no es gratis en términos de recursos: un modelo de varios miles de millones de parámetros puede requerir varios GB de RAM y, si quieres velocidad, una GPU adecuada.
Cuándo compensa la nube
Ollama Cloud (o cualquier backend remoto) compensa cuando:
-
No dispones de hardware suficiente para el modelo que necesitas (por ejemplo, modelos muy grandes o con contexto largo).
-
Prefieres no administrar servidores ni actualizaciones de modelos.
-
Necesitas escalar el uso entre varios usuarios o servicios sin duplicar máquinas locales.
-
Quieres combinar local para desarrollo y cloud para demos o entornos compartidos, usando la misma herramienta y la misma forma de invocar modelos (por ejemplo, con el sufijo
:cloud).
Crear cuenta, autenticarte y usar modelos remotos con el mismo flujo que en local es posible gracias a Ollama Cloud.
Casos de uso típicos
Ollama se usa en escenarios muy variados:
-
Desarrollo y prototipado: probar prompts, parámetros y flujos con LLMs sin depender de APIs de pago ni exponer datos.
-
Asistentes y chatbots internos: desplegar un asistente en la red local de una empresa, con los datos quedando dentro del perímetro.
-
Generación y análisis de código: integración en el editor o en scripts (por ejemplo, con LangChain o clientes compatibles con OpenAI) usando un backend local o en la nube según el contexto.
-
Experimentación con modelos abiertos: probar distintas familias (Llama, Qwen, Gemma, Mistral, etc.) y tamaños sin cambiar de proveedor ni de interfaz.
-
RAG y embeddings: usar modelos de embeddings locales para búsqueda semántica o RAG sin enviar documentos a servicios externos.
Cómo se diferencia de otros enfoques
Existen varias formas de ejecutar modelos de lenguaje, y conviene entender en qué se distingue Ollama de las alternativas más habituales:
- APIs de proveedores (OpenAI, Anthropic, Google): ofrecen modelos potentes con mínima configuración, pero los datos viajan a servidores externos y el coste crece con el uso. Ollama te permite usar modelos similares (open source) sin esa dependencia.
- llama.cpp y vLLM: herramientas de bajo nivel para ejecutar modelos en local. Requieren más configuración manual (compilación, gestión de pesos, servir la API). Ollama simplifica todo ese proceso en un único binario con CLI, API y aplicación de escritorio.
- Hugging Face Transformers: ecosistema completo para entrenar, evaluar y ejecutar modelos. Más orientado a investigación y desarrollo que a uso directo en producción. Ollama se centra en la ejecución y la integración, no en el entrenamiento.
Ollama no pretende sustituir a ninguno de estos enfoques, sino ofrecer un camino más directo para ejecutar y usar modelos abiertos sin necesidad de gestionar la infraestructura de bajo nivel.
El ecosistema de Ollama
Ollama no es solo un binario: es un ecosistema que incluye varios componentes que trabajan juntos:
- Servidor: el proceso que carga y ejecuta modelos.
- CLI: la interfaz de línea de comandos para gestionar modelos y chatear en terminal.
- API REST: endpoints HTTP para integrar Ollama en cualquier aplicación.
- Aplicación de escritorio: interfaz gráfica con chat, historial y soporte multimodal.
- Ollama Cloud: ejecución en la nube con autenticación y API key.
- SDK oficiales: librerías para Python y JavaScript que simplifican el uso de la API.
- Registro de modelos: catálogo público con decenas de modelos abiertos listos para descargar.
Todos estos componentes comparten las mismas convenciones de nombres de modelos, los mismos parámetros y el mismo flujo de trabajo, lo que facilita pasar de uno a otro según la tarea.
Ollama sirve como punto único para elegir entre ejecución local y nube, con la misma CLI, la misma API y las mismas convenciones de nombres de modelos, lo que facilita cambiar de uno a otro según el proyecto o el entorno.

Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, Ollama es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de Ollama
Explora más contenido relacionado con Ollama y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Entender qué es Ollama, qué problema resuelve y cuándo compensa ejecutar modelos en local frente a la nube.
Cursos que incluyen esta lección
Esta lección forma parte de los siguientes cursos estructurados con rutas de aprendizaje