
Generar texto con /api/generate
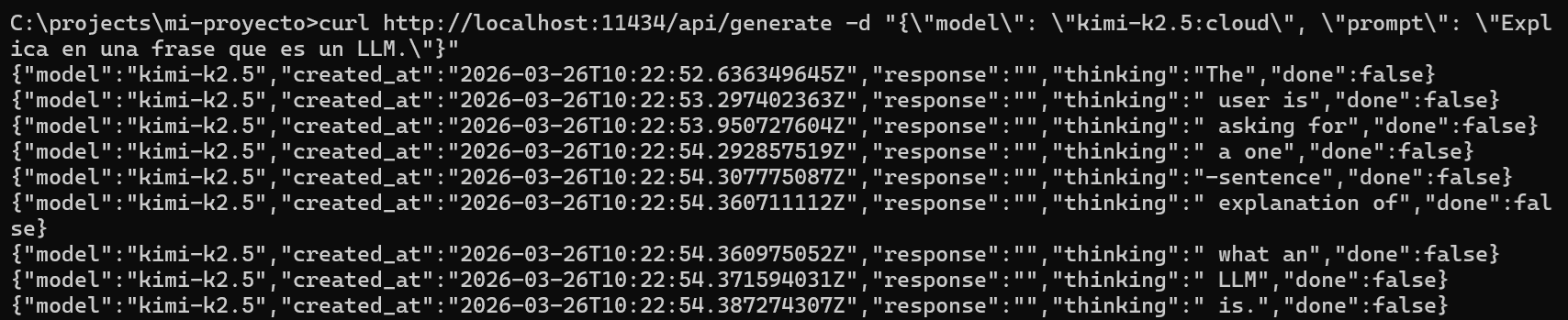
El endpoint /api/generate sirve para generar texto a partir de un prompt único. Envías un JSON con el nombre del modelo y el texto a completar. El servidor devuelve la respuesta (por defecto en streaming, es decir, trozos de texto conforme se generan).
Petición mínima con curl:
curl http://localhost:11434/api/generate -d '{
"model": "llama3.2",
"prompt": "Explica en una frase qué es un LLM."
}'
El cuerpo debe incluir al menos model (nombre del modelo, con tag si aplica, por ejemplo llama3.2:3b) y prompt (el texto que quieres que el modelo complete o responda). La respuesta por defecto es streaming: cada línea es un objeto JSON con un fragmento de la salida (por ejemplo el campo response con el texto generado). Al final suele llegar un objeto con done: true.
Para recibir la respuesta completa en un solo JSON (sin streaming), añade "stream": false:
curl http://localhost:11434/api/generate -d '{
"model": "llama3.2",
"prompt": "Explica en una frase qué es un LLM.",
"stream": false
}'

El streaming reduce la latencia percibida en respuestas largas y permite mostrar el texto al usuario mientras se genera. Usa
stream: falsecuando prefieras procesar la respuesta de una vez (por ejemplo en scripts o para parsear un JSON único).
Parámetros de generación (options)
Puedes ajustar el comportamiento del modelo pasando un objeto options en el cuerpo. Los parámetros más habituales son:
temperature: controla la aleatoriedad. Valores bajos (cercanos a 0) dan salidas más deterministas, y valores altos (cercanos a 2) más variadas. Para respuestas precisas o código suele usarse bajo, y para ideas o redacción creativa, algo más alto.top_p: nucleus sampling. Limita la elección de tokens a un subconjunto por probabilidad acumulada. Valores más bajos suelen hacer la salida más coherente y predecible.num_predict: número máximo de tokens que el modelo puede generar. Útil para limitar longitud y tiempo.
Ejemplo con opciones:
{
"model": "llama3.2",
"prompt": "Escribe un haiku sobre la programación.",
"stream": false,
"options": {
"temperature": 0.8,
"top_p": 0.9,
"num_predict": 100
}
}
Estos parámetros se envían dentro de options, no en la raíz del JSON.
Conversación con /api/chat
Para mantener un historial de mensajes (usuario, asistente, sistema), usa el endpoint /api/chat. Es el adecuado para chatbots, asistentes o cualquier flujo donde el contexto de la conversación importe.
El cuerpo incluye model y messages: una lista de objetos con role y content. Los roles típicos son user, assistant y system. El mensaje con rol system suele usarse para fijar el comportamiento o el tono del asistente (por ejemplo "Eres un ayudante técnico. Responde en español de forma breve.").
Ejemplo mínimo:
curl http://localhost:11434/api/chat -d '{
"model": "llama3.2",
"messages": [
{"role": "system", "content": "Responde siempre en una sola frase."},
{"role": "user", "content": "¿Qué es Python?"}
]
}'
La respuesta incluye el mensaje del assistant generado (en streaming por defecto, línea a línea, o en un solo bloque si usas "stream": false). Para la siguiente réplica del usuario, debes añadir ese mensaje del asistente y el nuevo mensaje del usuario a messages y volver a llamar a /api/chat. Así el modelo tiene todo el historial.
flowchart LR
A[Cliente] -->|POST /api/chat| B[Servidor]
B --> C[Modelo]
C --> B
B -->|JSON stream o completo| A
El cliente envía la lista de mensajes. El servidor la pasa al modelo y devuelve la respuesta del asistente. Las options (temperature, top_p, num_predict) se pueden usar también en /api/chat dentro del objeto options en el cuerpo, igual que en /api/generate.
Cuándo usar generate frente a chat
/api/generate: una sola pregunta o prompt, sin historial. Ideal para completar texto, traducir una frase o generar algo a partir de un único input./api/chat: conversación con varios turnos. Necesario cuando la respuesta debe depender de mensajes anteriores (seguir el hilo, corregir, dar contexto).
En ambos casos puedes usar streaming (por defecto) o stream: false y configurar temperature, top_p y num_predict en options para afinar el resultado.
Ejemplo completo en Python
Además de curl, puedes usar cualquier librería HTTP para llamar a la API. Este ejemplo en Python con requests muestra una conversación de varios turnos usando /api/chat:
import requests
url = "http://localhost:11434/api/chat"
messages = [
{"role": "system", "content": "Eres un asistente técnico. Responde en español de forma breve."},
{"role": "user", "content": "¿Qué es un LLM?"},
]
# Primer turno
r = requests.post(url, json={"model": "llama3.2", "messages": messages, "stream": False})
assistant_msg = r.json()["message"]
print("Asistente:", assistant_msg["content"])
# Segundo turno: añadir respuesta y nueva pregunta
messages.append(assistant_msg)
messages.append({"role": "user", "content": "¿Y qué ventaja tiene ejecutarlo en local?"})
r = requests.post(url, json={"model": "llama3.2", "messages": messages, "stream": False})
print("Asistente:", r.json()["message"]["content"])
El historial de mensajes se gestiona en el cliente: tú eres responsable de añadir cada respuesta del asistente y cada nuevo mensaje del usuario a la lista messages antes de enviar la siguiente petición. El servidor no mantiene estado entre peticiones.
Parámetro keep_alive
El parámetro keep_alive controla cuánto tiempo permanece el modelo cargado en memoria después de una petición. Por defecto suele ser 5 minutos. Puedes ajustarlo en cada petición:
"keep_alive": "10m": mantener 10 minutos."keep_alive": "1h": mantener 1 hora."keep_alive": 0: descargar el modelo inmediatamente tras la respuesta."keep_alive": -1: mantener el modelo cargado indefinidamente.
Esto es útil para optimizar recursos: si haces muchas peticiones seguidas, un keep_alive largo evita recargar el modelo. Si solo necesitas una respuesta puntual, un valor de 0 libera la memoria inmediatamente.
Métricas de rendimiento en la respuesta
Cuando usas "stream": false, la respuesta incluye campos de métricas que permiten medir el rendimiento de la generación:
{
"model": "llama3.2",
"message": {"role": "assistant", "content": "..."},
"done": true,
"total_duration": 1234567890,
"eval_count": 42,
"eval_duration": 987654321
}
La velocidad de generación se calcula como eval_count / eval_duration * 10^9 y se expresa en tokens por segundo. Estas métricas son útiles para comparar modelos, validar que la GPU se está usando correctamente o detectar si el modelo es demasiado grande para tu hardware.

Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, Ollama es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de Ollama
Explora más contenido relacionado con Ollama y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Usar POST /api/generate y POST /api/chat para generar texto, con y sin streaming, y configurar parámetros como temperature y top_p.
Cursos que incluyen esta lección
Esta lección forma parte de los siguientes cursos estructurados con rutas de aprendizaje