
Visión general de la arquitectura
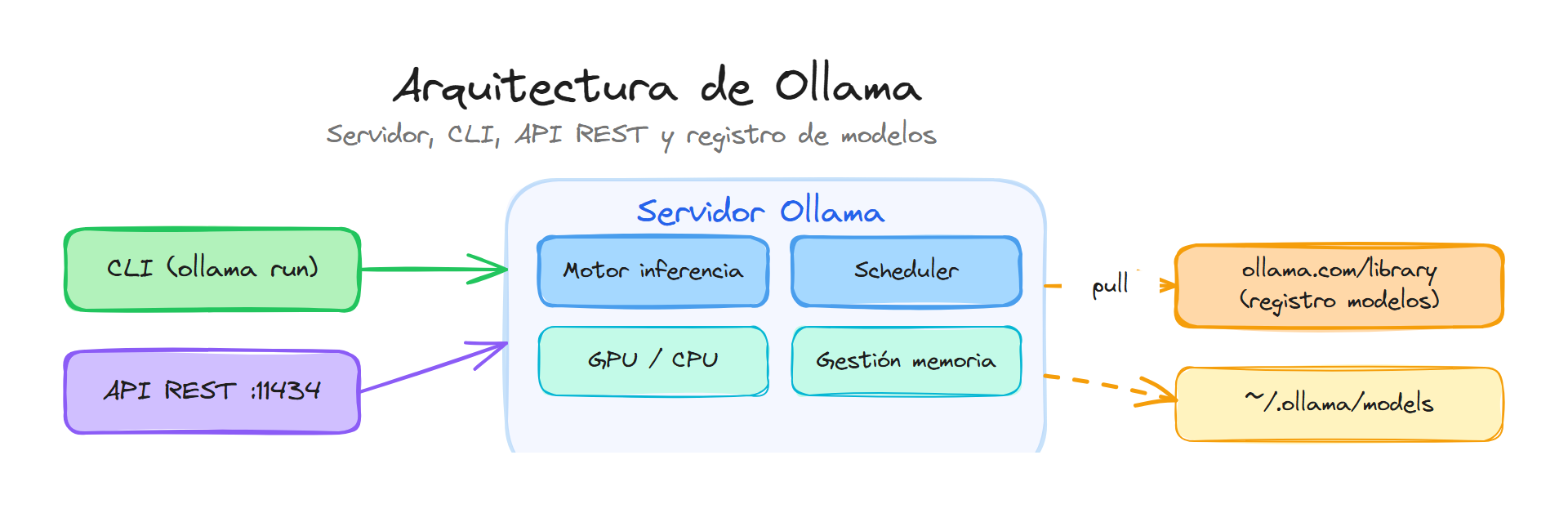
Ollama sigue una arquitectura cliente-servidor: un servidor (proceso en segundo plano) es el que realmente carga los modelos, ejecuta la inferencia y responde a las peticiones. Las aplicaciones y el usuario no hablan directamente con el modelo, sino con ese servidor a través de dos interfaces principales: la CLI (ollama en terminal) y la API REST.
Tanto si usas modelos locales como si usas Ollama Cloud, la idea es la misma: hay un "backend" que gestiona los modelos y un "cliente" (CLI, aplicación, script) que envía peticiones y recibe respuestas. Entender esta separación te ayuda a ver por qué la misma herramienta sirve para uso interactivo en terminal y para integraciones desde código o desde otras aplicaciones.
El servidor: local y en la nube
El servidor es el componente que:
- Carga los modelos (desde disco en local o desde la infraestructura de Ollama en la nube).
- Ejecuta la inferencia (generación de texto, chat, embeddings, etc.).
- Escucha peticiones en un puerto (en local, por defecto el 11434) o recibe peticiones hacia los endpoints de Ollama Cloud.
En una instalación local, el servidor suele arrancar automáticamente cuando usas la aplicación de escritorio o el comando ollama por primera vez. Se ejecuta en tu máquina y solo atiende peticiones desde el mismo equipo (o desde la red si se configura así). Los modelos se descargan y se guardan en tu disco.
En Ollama Cloud, el servidor está en los centros de datos de Ollama. Tú no lo instalas ni lo mantienes, solo te autenticas (cuenta, API key) y envías peticiones a sus endpoints. Los modelos están en su infraestructura y la inferencia se hace allí.
En ambos casos, la lógica es la misma: un servidor que recibe peticiones, elige el modelo adecuado (local o :cloud) y devuelve la respuesta. La diferencia está en dónde corre ese servidor y dónde están almacenados los modelos.
Registro de modelos
Ollama mantiene un registro (lista) de modelos disponibles para esa instalación. En local, ese registro refleja los modelos que has descargado en tu máquina (con ollama pull u otras vías). Cada modelo tiene un nombre y, opcionalmente, una etiqueta o tag (por ejemplo, versión o variante). Cuando pides usar un modelo por nombre, el servidor local busca en ese registro y carga el modelo desde disco si está disponible.
Cuando usas el sufijo :cloud, en la práctica estás indicando que el modelo no debe buscarse en el registro local, sino que la petición debe enviarse al servicio en la nube. El registro de modelos en la nube lo gestiona Ollama, y tú solo eliges el nombre del modelo (por ejemplo, llama3.2:cloud) y el servidor remoto se encarga del resto.
Así, el registro es el mecanismo que permite al servidor saber qué modelos tiene disponibles (locales o remotos) y cuál cargar o invocar para cada petición.
La CLI como cliente
La CLI (ollama en la terminal) es un cliente del servidor. Comandos como ollama run, ollama list o ollama pull no ejecutan el modelo por sí mismos: envían peticiones al servidor (local o, en su caso, a la nube) y muestran la respuesta en la terminal.
La CLI sirve para:
- Gestionar modelos (listar, descargar, eliminar).
- Ejecutar modelos de forma interactiva (chat en terminal).
- Lanzar el servidor o comprobar su estado cuando corresponde.
Todo lo que hace la CLI podría hacerse, en principio, llamando directamente a la API: la CLI es una forma cómoda de usar esa API desde la línea de comandos. Los comandos concretos y sus opciones permiten listar, descargar y ejecutar modelos desde la terminal.
La API como interfaz para aplicaciones
La API REST es la interfaz que usan aplicaciones, scripts e integraciones (por ejemplo, un plugin del editor, un backend en Python o una app web). En lugar de teclear comandos, el cliente envía peticiones HTTP (por ejemplo, POST a un endpoint de generación o de chat) y recibe la respuesta en JSON (o en streaming).
Ventajas de basar las integraciones en la API:
- Cualquier lenguaje o herramienta que pueda hacer HTTP puede usar Ollama.
- Se puede implementar streaming (respuestas que van llegando por fragmentos).
- Es la misma API que usan clientes compatibles con OpenAI: configurando la URL base y, en su caso, la API key de Ollama Cloud, muchas librerías funcionan sin cambios.
En local, la API suele estar en localhost en un puerto por defecto (11434). En la nube, la base URL y la autenticación cambian, pero el esquema de peticiones y respuestas es coherente. Los endpoints, parámetros y formato de la API permiten integrar Ollama desde cualquier aplicación que pueda enviar peticiones HTTP.
Cómo encajan los componentes
flowchart LR
subgraph Cliente
CLI[CLI ollama]
APP[App / Script]
end
subgraph Servidor
S[Servidor Ollama]
R[(Registro modelos)]
end
CLI -->|Comandos| S
APP -->|HTTP / API| S
S --> R
R --> Modelo[Modelo local o cloud]
S --> Modelo
El cliente (CLI o aplicación) envía peticiones al servidor. El servidor consulta el registro de modelos para saber qué modelo usar (local o :cloud), lo carga o lo invoca y devuelve la respuesta al cliente. Tanto la CLI como las aplicaciones que usan la API se apoyan en el mismo servidor y en el mismo registro conceptual, y la única diferencia es el canal (comandos frente a HTTP).
Con esta visión general tienes la base para entender la instalación del servidor, los comandos de la CLI y el uso de la API en detalle.
Ciclo de vida de una petición paso a paso
Para fijar la arquitectura conviene seguir lo que ocurre cuando ejecutas un simple ollama run llama3.2 y escribes una pregunta:
- La CLI abre una conexión contra el servidor local en
http://127.0.0.1:11434. - El servidor resuelve el modelo buscando
llama3.2en el registro. Si no está, lanza internamente unpully lo descarga del registro remoto. - Se carga el modelo en memoria (GPU si hay VRAM suficiente, CPU + RAM si no). Esta fase de warm-up puede tardar unos segundos la primera vez.
- El servidor tokeniza el prompt aplicando la plantilla de chat del modelo (por ejemplo la plantilla de Llama 3) y calcula los tokens de entrada.
- Se inicia la inferencia por fragmentos: el servidor va enviando tokens a la CLI a medida que los genera.
- La CLI renderiza el streaming en la terminal. Cuando el modelo termina, el servidor cierra el flujo y registra las estadísticas (tokens de entrada, tokens de salida, duración).
- El modelo permanece cargado durante un tiempo configurable (
OLLAMA_KEEP_ALIVE, 5 minutos por defecto). Si se vuelve a pedir antes de que expire, la respuesta será casi instantánea.
Este flujo es idéntico cuando la petición llega por API: lo único que cambia es que el cliente es un script o una aplicación externa en lugar de la CLI.
Tabla comparativa: servidor local frente a Ollama Cloud
| Aspecto | Servidor local | Ollama Cloud |
|---------|---------------|--------------|
| Dónde corre | En tu máquina, normalmente localhost:11434 | En la infraestructura de Ollama |
| Privacidad | Máxima: los prompts no salen de tu equipo | Los prompts se envían al servicio remoto |
| Requisitos de hardware | GPU o CPU potente para modelos grandes | Ninguno, solo conexión a internet |
| Coste | Ninguno (fuera del hardware) | Plan de pago según uso |
| Latencia | Muy baja en modelos pequeños | Depende de la red y de la cola del servicio |
| Modelos disponibles | Los que puedas descargar y cargar en RAM/VRAM | Catálogo gestionado por Ollama, normalmente con variantes :cloud |
| Actualizaciones | Manuales (ollama pull modelo) | Gestionadas por el servicio |
La gran ventaja de Ollama es que no tienes que elegir de forma excluyente: el mismo cliente y la misma API sirven para ambos casos, así que puedes empezar en local durante el desarrollo y mover cargas concretas a la nube sin reescribir tu código.
Variables de entorno clave del servidor
El servidor respeta varias variables de entorno que permiten afinar su comportamiento sin tocar ningún archivo de configuración. Las más importantes son:
| Variable | Efecto | Ejemplo |
|----------|--------|---------|
| OLLAMA_HOST | Dirección y puerto donde escucha el servidor | 0.0.0.0:11434 para aceptar conexiones de la red |
| OLLAMA_MODELS | Carpeta donde se guardan los modelos descargados | D:\ollama-models en Windows |
| OLLAMA_KEEP_ALIVE | Tiempo que un modelo permanece en memoria tras la última petición | 30m, 1h, -1 para dejarlo cargado indefinidamente |
| OLLAMA_NUM_PARALLEL | Número de peticiones paralelas que el servidor puede atender | 4 para un equipo con suficiente VRAM |
| OLLAMA_MAX_LOADED_MODELS | Cuántos modelos distintos puede mantener cargados a la vez | 2 si alternas entre un modelo de chat y uno de embeddings |
| OLLAMA_ORIGINS | Lista de orígenes permitidos (CORS) para llamadas desde el navegador | https://mi-app.local |
Definir OLLAMA_KEEP_ALIVE con un valor alto acelera mucho el trabajo interactivo; definir OLLAMA_MODELS es imprescindible si quieres guardar los modelos en un disco distinto al del sistema.
Errores comunes al entender la arquitectura
- Pensar que
ollama run«es» el modelo: no lo es.ollama runes un cliente que habla con el servidor; si matas el proceso de la CLI, el modelo sigue cargado en el servidor hasta que expire el keep-alive. - Abrir un puerto al exterior sin protección: si cambias
OLLAMA_HOSTa0.0.0.0, cualquier equipo con acceso a la red puede enviar peticiones. Usa siempre un firewall, VPN o proxy con autenticación. - Confundir
:cloudcon un modelo local: los modelos con sufijo:cloudnunca se descargan a disco, siempre se ejecutan en la infraestructura de Ollama. Si trabajas con datos sensibles, asegúrate de que el modelo que usas no lleva ese sufijo. - Cambiar
OLLAMA_MODELSy perder los modelos anteriores: al modificar la ruta, el servidor deja de ver los modelos antiguos. Muévelos manualmente a la nueva carpeta o vuelve a hacerpull. - Olvidar que la API es compatible con OpenAI: muchos usuarios reescriben sus clientes desde cero cuando bastaría con cambiar la URL base y la clave para que funcionen con Ollama.
Mejores prácticas
- Arranca el servidor como servicio: en Linux con
systemd, en macOS con el launcher oficial y en Windows con la aplicación de escritorio. Así siempre está disponible sin pasos manuales. - Mantén una sola versión del cliente y del servidor actualizadas en cada máquina: mezclar versiones antiguas y nuevas produce errores sutiles en la API.
- Monitoriza el uso de VRAM y RAM: el servidor informa del modelo cargado en
ollama ps, lo que te permite detectar si un modelo se quedó colgado en memoria. - Separa entornos de desarrollo y producción con variables de entorno distintas, especialmente
OLLAMA_HOST,OLLAMA_NUM_PARALLELyOLLAMA_MODELS. - Documenta tu arquitectura interna: si tu equipo comparte un servidor Ollama, deja claro en el
READMEqué modelos están disponibles, quién los mantiene y cómo se actualizan.
Comprender estos detalles convierte a Ollama de una simple caja negra en una plataforma sobre la que puedes construir sistemas serios de inferencia local o híbrida con plenas garantías.

Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, Ollama es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de Ollama
Explora más contenido relacionado con Ollama y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Comprender la arquitectura de Ollama: servidor local o en la nube, registro de modelos, y el papel de la CLI y la API como interfaces de uso.
Cursos que incluyen esta lección
Esta lección forma parte de los siguientes cursos estructurados con rutas de aprendizaje