
Base URL y acceso en local
El servidor de Ollama expone una API REST sobre HTTP. En una instalación local, por defecto escucha en http://localhost:11434. Cualquier cliente que pueda hacer peticiones HTTP (curl, Postman, código en Python o JavaScript, etc.) puede hablar con el servidor usando esa base URL.
No necesitas API key en local: el servidor acepta peticiones desde la misma máquina sin autenticación. Eso facilita probar la API desde scripts o desde herramientas de desarrollo. Si cambias el puerto o el host (por ejemplo al desplegar en Docker o en otra máquina), la base URL será la que hayas configurado (por ejemplo http://host:11434).
En local, la API está pensada para uso en tu entorno de desarrollo o en tu red. Si expones el puerto a internet, conviene proteger el acceso (proxy, firewall o autenticación adicional).
Endpoints principales
La API de Ollama organiza la funcionalidad en endpoints concretos. Los más usados son:
| Endpoint | Método | Uso |
|----------|--------|-----|
| /api/generate | POST | Generar texto a partir de un prompt (una sola vuelta, con o sin streaming). |
| /api/chat | POST | Conversación con historial de mensajes (user/assistant/system), ideal para chatbots. |
| /api/embed | POST | Obtener embeddings (vectores) de un texto para RAG o búsqueda semántica. |
| /api/tags | GET | Listar los modelos disponibles en el servidor (equivalente a ollama list). |
| /api/ps | GET | Ver qué modelos están cargados en memoria en ese momento. |
Todas las peticiones de generación o embeddings van con POST y cuerpo en JSON. Las respuestas son también JSON (o líneas de JSON si usas streaming). En las siguientes lecciones se verá en detalle cómo usar /api/generate, /api/chat, /api/embed y la compatibilidad con la API de OpenAI.
Comprobar que la API responde
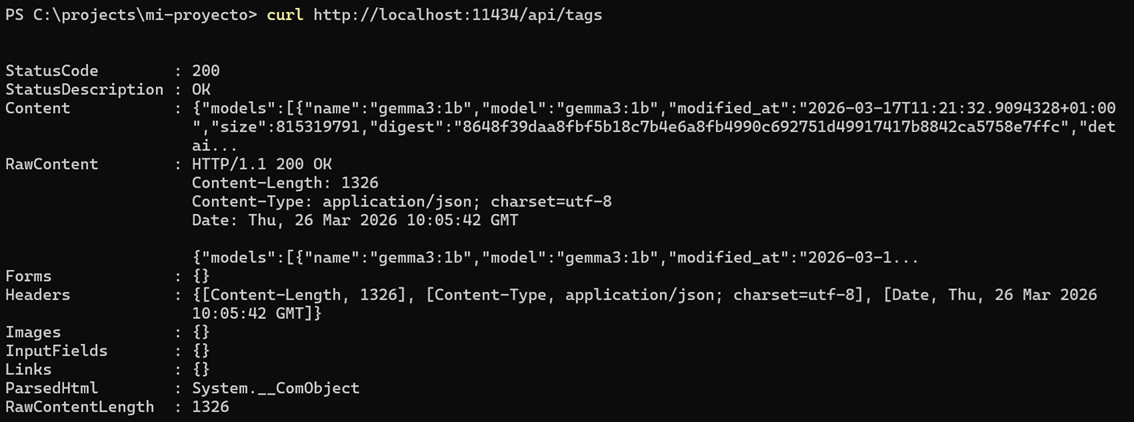
Puedes comprobar que el servidor está en marcha y que la API responde haciendo una petición GET al endpoint de listado de modelos:
curl http://localhost:11434/api/tags
Si el servidor está activo, recibirás un JSON con la lista de modelos instalados (o disponibles en la nube si aplica). Si no está en marcha, obtendrás un error de conexión. En ese caso, arranca Ollama (por ejemplo abriendo la aplicación de escritorio o ejecutando ollama serve) y vuelve a probar.
flowchart LR
subgraph Cliente
C[Cliente HTTP]
end
subgraph Servidor
T["/api/tags"]
G["/api/generate"]
H["/api/chat"]
E["/api/embed"]
end
C -->|GET| T
C -->|POST| G
C -->|POST| H
C -->|POST| E
El cliente envía peticiones a la base URL y el servidor enruta cada petición al endpoint correspondiente según el path.
Uso con Ollama Cloud
Cuando usas Ollama Cloud (servicio gestionado en la nube), la base URL no es localhost. Debes usar la URL que proporciona el servicio (por ejemplo https://api.ollama.com o la indicada en la documentación actual) y, en ese caso, sí se requiere autenticación mediante API key.
La API key se envía normalmente en la cabecera Authorization (por ejemplo Bearer TU_API_KEY). Sin ella, las peticiones a los endpoints de la nube serán rechazadas. La lógica de los endpoints (generate, chat, embed, etc.) es la misma que en local. Solo cambian la base URL y la necesidad de enviar la API key en cada petición.
Si en tu entorno no debe usarse la nube, puedes definir
OLLAMA_NO_CLOUD=1para que el cliente no intente conectar con Ollama Cloud.
En local usas http://localhost:11434 y no necesitas API key. En Ollama Cloud usas la URL del servicio y envías tu API key en las cabeceras. A partir de ahí, los endpoints y el formato de las peticiones son coherentes en ambos entornos.
Otros endpoints de gestión
Además de los endpoints de generación y consulta, la API incluye endpoints para gestionar modelos sin necesidad de usar la CLI:
| Endpoint | Método | Uso |
|----------|--------|-----|
| /api/pull | POST | Descargar un modelo desde el registro (equivalente a ollama pull). |
| /api/delete | DELETE | Eliminar un modelo del servidor (equivalente a ollama rm). |
| /api/copy | POST | Duplicar un modelo con otro nombre (equivalente a ollama copy). |
| /api/show | POST | Obtener información detallada de un modelo (Modelfile, parámetros, licencia). |
| /api/create | POST | Crear un modelo personalizado desde un Modelfile. |
Estos endpoints permiten automatizar la gestión del catálogo de modelos desde scripts o aplicaciones. Por ejemplo, un sistema de despliegue puede comprobar con /api/tags si un modelo está disponible, descargarlo con /api/pull si no lo está y luego usar /api/chat para generar respuestas.
Formato de las respuestas
Todas las respuestas de la API vienen en JSON. Cuando el streaming está activado (por defecto), cada línea es un objeto JSON independiente. Cuando usas "stream": false, recibes un único objeto JSON con toda la información. Las respuestas de generación incluyen campos de métricas que permiten medir el rendimiento:
total_duration: tiempo total de la petición en nanosegundos.load_duration: tiempo de carga del modelo (solo si se cargó en esa petición).prompt_eval_count: número de tokens en la entrada.eval_count: número de tokens generados.eval_duration: tiempo de generación en nanosegundos.
Para calcular la velocidad de generación en tokens por segundo: eval_count / eval_duration * 10^9. Estas métricas son útiles para comparar modelos, ajustar parámetros o detectar cuellos de botella en tu infraestructura.
Herramientas para probar la API
Puedes probar la API de Ollama con cualquier herramienta que envíe peticiones HTTP:
- curl: la forma más directa desde la terminal, como se ha visto en los ejemplos.
- Postman o Insomnia: interfaces gráficas para construir y enviar peticiones, útiles para explorar endpoints sin escribir código.
- Scripts en Python o JavaScript: usando
requests,httpx(Python) ofetch,axios(JavaScript) para automatizar llamadas. - SDK oficial de Ollama: el paquete
ollamaen Python y JavaScript envuelve la API REST y simplifica el uso desde código (se verá en el módulo de integración).
La API REST es la base sobre la que se construyen todas las integraciones con Ollama: la CLI, la aplicación de escritorio, los SDK y los frameworks como LangChain hablan con el servidor a través de estos mismos endpoints.

Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, Ollama es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de Ollama
Explora más contenido relacionado con Ollama y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Conocer la base URL de la API en local y en la nube, los endpoints principales y cómo enviar peticiones HTTP al servidor de Ollama.
Cursos que incluyen esta lección
Esta lección forma parte de los siguientes cursos estructurados con rutas de aprendizaje