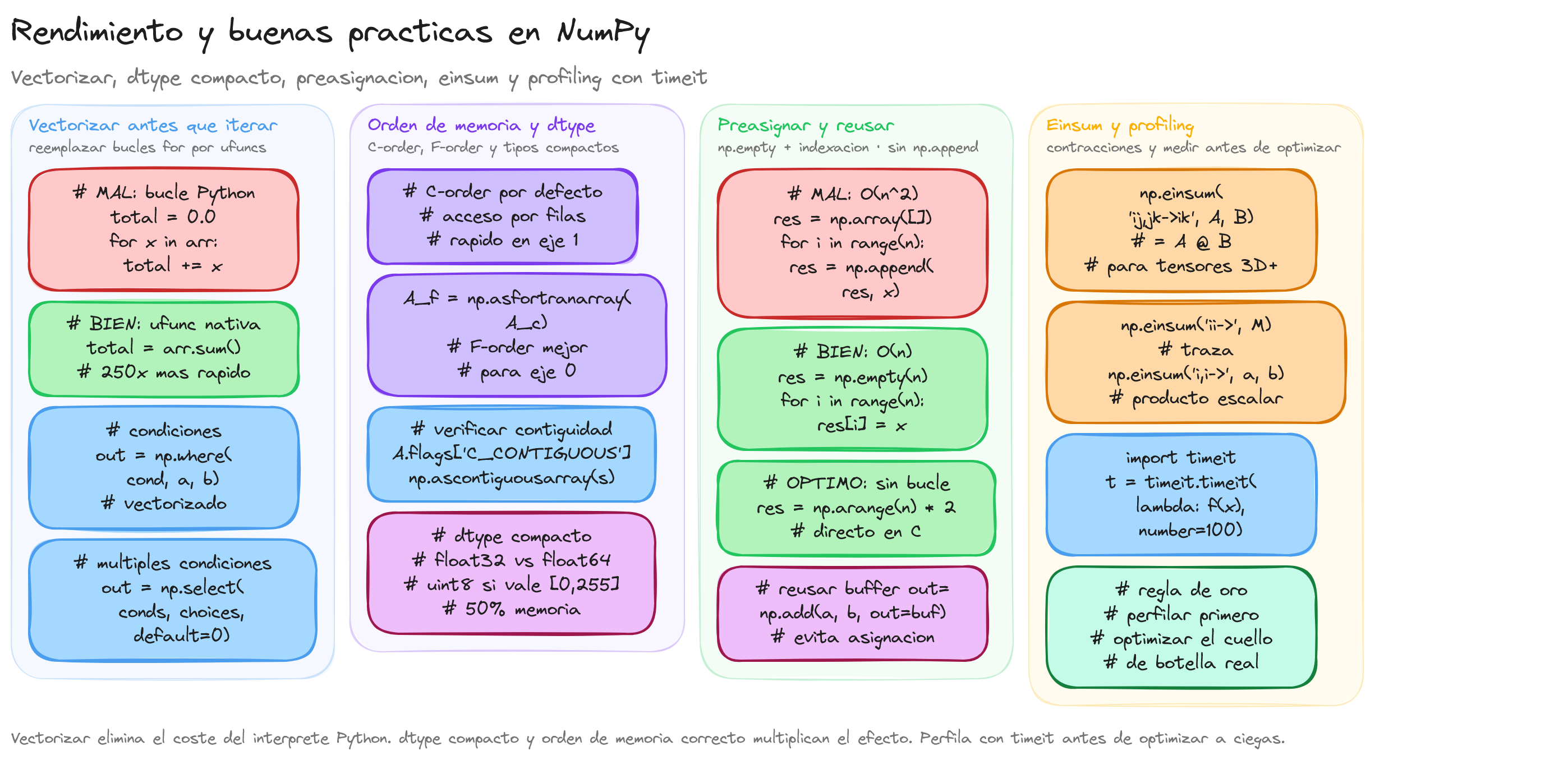
Principio fundamental: vectorización frente a bucles
La regla de oro de NumPy es evitar bucles Python. Cada iteración de un bucle for pasa por el intérprete Python, que tiene un coste fijo por instrucción. Las operaciones vectorizadas de NumPy ejecutan la misma lógica en código C compilado, lo que puede ser entre 10 y 1000 veces más rápido dependiendo del tamaño del array.
import numpy as np
import timeit
n = 1_000_000
a = np.random.default_rng(0).standard_normal(n)
# Enfoque con bucle Python
def suma_bucle(arr):
total = 0.0
for x in arr:
total += x
return total
# Enfoque vectorizado
def suma_numpy(arr):
return arr.sum()
t_bucle = timeit.timeit(lambda: suma_bucle(a), number=5) / 5
t_numpy = timeit.timeit(lambda: suma_numpy(a), number=5) / 5
print(f"Bucle: {t_bucle*1000:.1f} ms")
print(f"NumPy: {t_numpy*1000:.2f} ms")
print(f"Aceleración: {t_bucle/t_numpy:.0f}x")
# Típicamente: Bucle 150 ms → NumPy 0.6 ms → 250x de aceleración
Sustituir bucles comunes
| Patrón con bucle | Equivalente vectorizado |
|------------------|------------------------|
| [x**2 for x in a] | a**2 |
| [f(x) for x in a] | np.vectorize(f)(a) o ufunc nativa |
| sum(a[i]*b[i] for i in range(n)) | np.dot(a, b) |
| Acumulación condicional | np.where, np.select |
| Doble bucle para producto externo | np.outer(a, b) |
Orden de memoria: C-order vs Fortran-order
Los arrays de NumPy almacenan sus datos en memoria de forma contigua. Existen dos convenciones:
- C-order (por filas, predeterminado): el elemento
a[i, j+1]está en la siguiente posición de memoria respecto aa[i, j]. Las operaciones por filas son más rápidas. - Fortran-order (por columnas): el elemento
a[i+1, j]está contiguo aa[i, j]. Las operaciones por columnas son más rápidas.
import numpy as np
n = 2000
# C-order (por defecto)
A_c = np.random.default_rng(1).random((n, n), ) # C-order por defecto
A_f = np.asfortranarray(A_c) # mismos datos, F-order
# Suma por filas (eje 1): favorece C-order
import timeit
tc = timeit.timeit(lambda: A_c.sum(axis=1), number=50) / 50
tf = timeit.timeit(lambda: A_f.sum(axis=1), number=50) / 50
print(f"Suma filas C-order: {tc*1000:.2f} ms")
print(f"Suma filas F-order: {tf*1000:.2f} ms")
# Suma por columnas (eje 0): favorece F-order
tc2 = timeit.timeit(lambda: A_c.sum(axis=0), number=50) / 50
tf2 = timeit.timeit(lambda: A_f.sum(axis=0), number=50) / 50
print(f"Suma cols C-order: {tc2*1000:.2f} ms")
print(f"Suma cols F-order: {tf2*1000:.2f} ms")
Regla práctica: usa C-order (predeterminado) para datos organizados por muestras (filas = muestras). Usa F-order solo cuando la librería destino lo requiera explícitamente (p. ej., algunas rutinas de LAPACK vía SciPy).
Verificar la contigüidad de un array
a = np.arange(12).reshape(3, 4)
print(a.flags)
# C_CONTIGUOUS: True
# F_CONTIGUOUS: False
b = np.asfortranarray(a)
print(b.flags)
# C_CONTIGUOUS: False
# F_CONTIGUOUS: True
# Hacer contiguo un array no contiguo (p.ej., tras un slice)
sliced = a[:, ::2] # no contiguo en memoria
contig = np.ascontiguousarray(sliced)
print(contig.flags["C_CONTIGUOUS"]) # True
Elegir el dtype más pequeño posible
Usar tipos de dato más pequeños reduce el consumo de memoria y mejora el rendimiento de caché de la CPU.
import numpy as np
n = 10_000_000
# Por defecto, NumPy usa float64 (8 bytes por elemento)
a64 = np.ones(n, dtype="float64")
a32 = np.ones(n, dtype="float32")
print(f"float64: {a64.nbytes / 1e6:.0f} MB") # 80 MB
print(f"float32: {a32.nbytes / 1e6:.0f} MB") # 40 MB
# Para enteros, i8 (int64) vs i2 (int16)
idx64 = np.arange(n, dtype="int64")
idx16 = np.arange(n, dtype="int16") # solo si los valores caben en [-32768, 32767]
# Comprobar rango antes de reducir tipo
print(a64.astype("float32").max() == a64.max()) # True si no hay pérdida de precisión
Guía rápida de tipos mínimos
| Rango de valores | Tipo entero | Tipo flotante |
|------------------|-------------|---------------|
| 0-255 | uint8 | - |
| −32768-32767 | int16 | - |
| −2.1e9-2.1e9 | int32 | - |
| Cualquier entero | int64 | - |
| Precisión media | - | float32 |
| Precisión doble | - | float64 |
Preasignación de arrays: evitar np.append en bucles
np.append crea una copia completa del array en cada llamada; usarlo en un bucle produce complejidad cuadrática. La solución es preasignar el array con np.empty o np.zeros y rellenar por indexación.
import numpy as np
n = 100_000
# MAL: np.append en bucle → O(n²)
def acumular_append(n):
resultado = np.array([])
for i in range(n):
resultado = np.append(resultado, i * 2.0)
return resultado
# BIEN: preasignar y rellenar → O(n)
def acumular_prealloc(n):
resultado = np.empty(n)
for i in range(n):
resultado[i] = i * 2.0
return resultado
# ÓPTIMO: sin bucle en absoluto
def acumular_vectorizado(n):
return np.arange(n, dtype=float) * 2.0
# Para n=1000 el bucle con append ya es ~100x más lento que prealloc
np.einsum: contracciones tensoriales eficientes
np.einsum implementa la notación de suma de Einstein, que expresa en una cadena de texto el patrón de multiplicación y suma de índices. Es especialmente útil para operaciones tensorialesque de otro modo requerirían múltiples llamadas a np.dot, np.sum o np.tensordot.
import numpy as np
A = np.random.default_rng(0).random((4, 5))
B = np.random.default_rng(1).random((5, 3))
# Producto matricial estándar: igual que A @ B
C1 = np.einsum("ij,jk->ik", A, B)
C2 = A @ B
print(np.allclose(C1, C2)) # True
# Traza de una matriz cuadrada
M = np.arange(9).reshape(3, 3).astype(float)
traza = np.einsum("ii->", M)
print(traza) # 12.0 (= 0+4+8)
print(np.trace(M)) # 12.0
# Producto elemento a elemento y suma (dot product)
a = np.array([1.0, 2.0, 3.0])
b = np.array([4.0, 5.0, 6.0])
dot_einsum = np.einsum("i,i->", a, b)
print(dot_einsum) # 32.0
# Producto externo: resultado (n, m)
outer = np.einsum("i,j->ij", a, b)
print(outer)
# [[ 4. 5. 6.]
# [ 8. 10. 12.]
# [12. 15. 18.]]
Ventajas de np.einsum
- Evita la creación de arrays intermedios gracias a la optimización de rutas (
optimize=True). - Expresa operaciones complejas (como la multiplicación de tensores 3D o 4D) en una sola línea.
- Con
optimize="optimal"ooptimize="greedy", NumPy selecciona el orden de contracción más eficiente.
import numpy as np
# Sin optimización de ruta
A = np.random.random((50, 50))
B = np.random.random((50, 50))
C = np.random.random((50, 50))
# Con optimización
resultado = np.einsum("ij,jk,kl->il", A, B, C, optimize=True)
np.where y np.select para condicionales sin bucles
En lugar de bucles if/else sobre arrays, se usan np.where y np.select:
import numpy as np
temperaturas = np.array([18.5, 24.3, 30.1, 15.0, 35.7, 27.8])
# np.where: condición binaria
categoria = np.where(temperaturas > 25, "caluroso", "fresco")
print(categoria)
# ['fresco' 'fresco' 'caluroso' 'fresco' 'caluroso' 'caluroso']
# np.select: condiciones múltiples (primer match gana)
condiciones = [
temperaturas < 18,
temperaturas < 25,
temperaturas < 32,
]
valores = ["frío", "templado", "caluroso"]
resultado = np.select(condiciones, valores, default="muy caluroso")
print(resultado)
# ['templado' 'templado' 'caluroso' 'frío' 'muy caluroso' 'caluroso']
Perfilar código NumPy con timeit
La optimización prematura es contraproducente. Siempre mide primero con timeit para identificar el cuello de botella real:
import numpy as np
import timeit
rng = np.random.default_rng(42)
A = rng.random((1000, 1000))
B = rng.random((1000, 1000))
# Producto matricial
t_matmul = timeit.timeit(lambda: A @ B, number=10) / 10
print(f"Producto matricial 1000x1000: {t_matmul*1000:.1f} ms")
# Suma reducida
t_sum = timeit.timeit(lambda: A.sum(), number=100) / 100
print(f"Suma total: {t_sum*1000:.2f} ms")
Resumen de las buenas prácticas
flowchart TD
A[Código lento con NumPy] --> B{"¿Hay bucles Python?"}
B -->|Sí| C["Vectorizar con ufuncs, sum, where, einsum"]
B -->|No| D{"¿El dtype es innecesariamente grande?"}
D -->|Sí| E["Reducir a float32/int16 si el rango lo permite"]
D -->|No| F{"¿Hay copias innecesarias?"}
F -->|Sí| G["Preasignar con np.empty, usar vistas en lugar de copias"]
F -->|No| H{"¿El acceso a memoria es ineficiente?"}
H -->|Sí| I["Verificar C/F-order y ascontiguousarray"]
H -->|No| J["Considerar Numba, Cython o C extensión"]
Siguiendo estas prácticas se puede extraer la mayor parte del rendimiento disponible en NumPy sin salir del entorno Python.

Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, NumPy es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de NumPy
Explora más contenido relacionado con NumPy y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Evitar bucles Python y sustituirlos por operaciones vectorizadas. Comprender el impacto del orden de memoria (C vs Fortran) en el rendimiento. Usar np.einsum para contracciones tensoriales eficientes. Aplicar preasignación de arrays con np.empty para evitar copias innecesarias. Perfilar código NumPy con timeit y detectar cuellos de botella.
Cursos que incluyen esta lección
Esta lección forma parte de los siguientes cursos estructurados con rutas de aprendizaje