¿Qué es Pandas en Python?
flowchart LR
A[ndarray] --> B[shape]
A --> C[dtype]
A --> D[strides]
B --> E[Operaciones vectorizadas]
C --> E
D --> E
E --> F[Broadcasting]
F --> G[Resultado ndarray]
Pandas es una librería fundamental para la manipulación y análisis de datos en Python, construida sobre la base de datos de NumPy. Ofrece estructuras de datos y operaciones para manipular tablas numéricas y series temporales de manera eficiente y flexible. Dos de sus estructuras de datos más utilizadas son Series y DataFrame.
1.- Series: Una Series en Pandas es una estructura de datos unidimensional que se asemeja a un array de NumPy, pero con una característica adicional muy útil: un índice que etiqueta cada elemento de la serie. Este índice puede ser de cualquier tipo de datos, como enteros, cadenas, fechas, etc., lo que permite acceder a los datos de manera más intuitiva y flexible.
import pandas as pd
data = [1, 2, 3, 4, 5]
series = pd.Series(data)
print(series)
2.- DataFrame: Un DataFrame en Pandas es una estructura de datos bidimensional que se asemeja a una tabla en una base de datos relacional o a una hoja de cálculo de Excel. Es esencialmente una colección de Series alineadas por su índice. Cada columna de un DataFrame puede contener datos de diferentes tipos (números, cadenas, booleanos, etc.), lo que lo convierte en una herramienta extremadamente versátil para el análisis de datos.
import pandas as pd
data = {
'Nombre': ['Ana', 'Luis', 'Juan'],
'Edad': [23, 21, 25],
'Ciudad': ['Madrid', 'Barcelona', 'Valencia']
}
df = pd.DataFrame(data)
print(df)
Pandas combina las capacidades de alto rendimiento de los arrays de NumPy con la flexibilidad de las etiquetas de índice. Además, proporciona métodos y funciones robustas para la limpieza de datos, análisis, agregación y visualización. Es especialmente útil para trabajos en campos como la economía, estadísticas, analítica de datos, etc.
Algunas funcionalidades clave de Pandas incluyen:
- Manejo de datos faltantes: Pandas incluye métodos como
dropna()yfillna()para eliminar o reemplazar valores nulos.dropna()elimina cualquier fila (o columna) que contenga uno o más valores nulos. Esto es útil cuando la presencia de datos faltantes en una fila o columna invalida todo el registro o variable.fillna()reemplaza los valores nulos en el DataFrame con un valor específico (por ejemplo, 0, la media, mediana, o un valor constante). Este método es especialmente útil cuando deseas imputar valores en lugar de eliminar datos.
df.dropna() # Elimina cualquier fila con valores nulos
df.fillna(0) # Reemplaza cualquier valor nulo con 0
- Operaciones de grupo: Las operaciones de agrupamiento permiten dividir el DataFrame en subconjuntos basados en los valores de una o más columnas, y luego aplicar funciones de agregación, transformación o filtrado en esos subconjuntos.
groupby()agrupa el DataFrame según los valores únicos de la columna especificada. Luego, puedes aplicar funciones de agregación comomean(),sum(),count(), etc.
# Seleccionar solo las columnas numéricas para operaciones de agregación
grouped = df.groupby('Ciudad').mean(numeric_only=True)
print(grouped)
- Mezcla y combinación de datos: Pandas facilita la combinación de diferentes DataFrames mediante métodos como
merge()yconcat(). Estas operaciones son esenciales cuando se trabaja con múltiples fuentes de datos que necesitan ser unidas o apiladas juntas.
df1 = pd.DataFrame({'A': [1, 2], 'B': [3, 4]})
df2 = pd.DataFrame({'A': [5, 6], 'B': [7, 8]})
result = pd.concat([df1, df2])
print(result)
- Lectura/escritura de archivos: Pandas permite importar y exportar datos de y hacia múltiples formatos, lo que facilita el flujo de trabajo de análisis de datos. Los métodos de lectura y escritura son cruciales para la interoperabilidad con otros sistemas y herramientas de datos. Pandas aporta métodos para importar y exportar datos en distintos formatos como CSV, Excel, SQL, JSON, etc.
df.to_csv('archivo.csv', index=False)
df = pd.read_csv('archivo.csv')
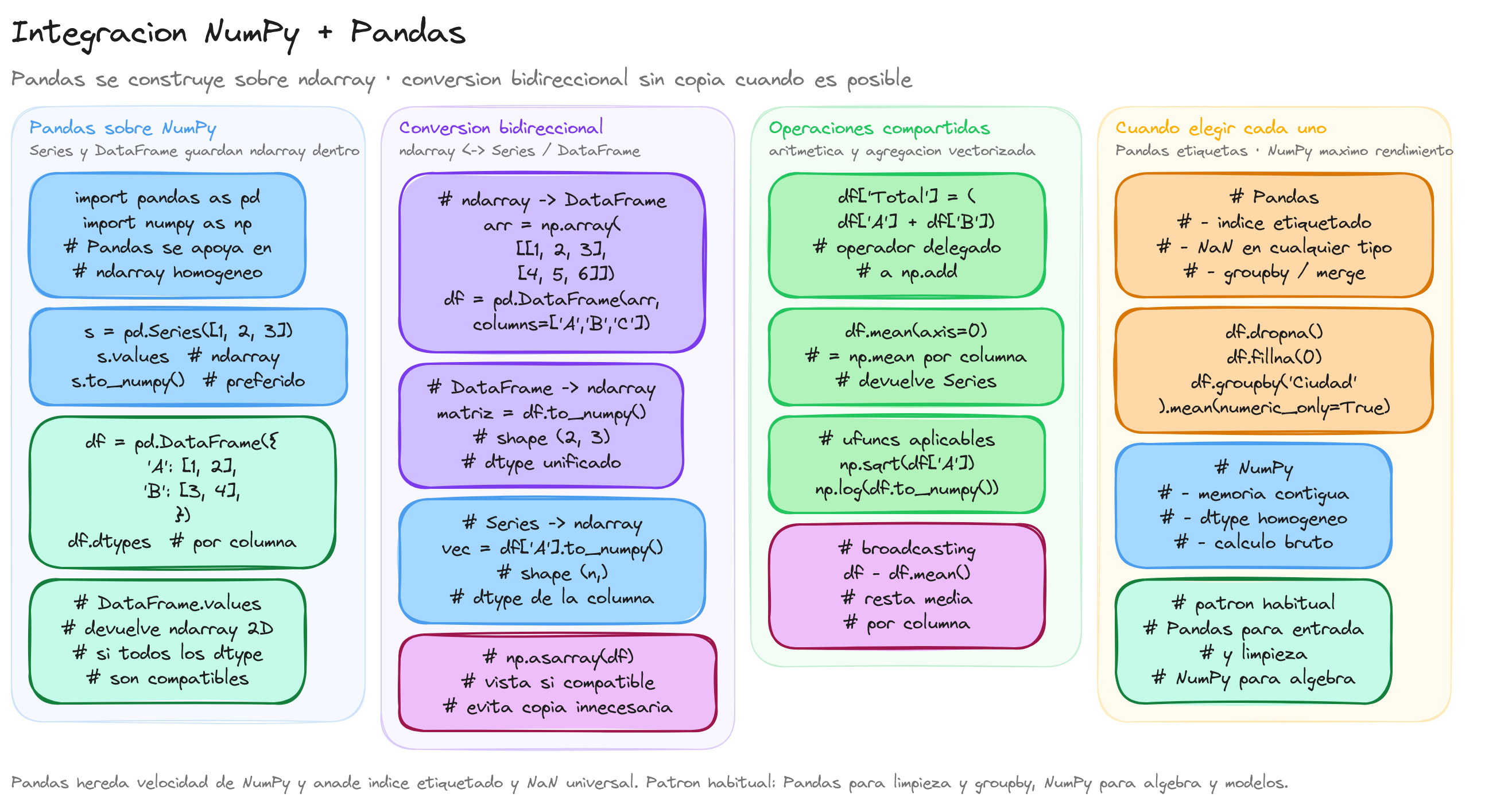
Pandas se integra perfectamente con NumPy, aprovechando las operaciones vectorizadas y la eficiencia computacional de NumPy, mientras proporciona una interfaz más amigable para el análisis de datos. La combinación de NumPy y Pandas permite realizar análisis y manipulaciones complejas de datos de manera más intuitiva y eficiente.
¿Qué relación existe entre NumPy y Pandas?
NumPy y Pandas están estrechamente relacionados, ya que Pandas se construyó sobre la base de NumPy para aprovechar sus capacidades de manejo y procesamiento de arrays.
NumPy proporciona la estructura de datos subyacente y la eficiencia computacional, mientras que Pandas ofrece una interfaz más accesible y funcionalidades adicionales específicas para el análisis de datos.
Los objetos principales de Pandas, Series y DataFrame, están construidos utilizando arrays de NumPy internamente. Esto significa que muchas de las operaciones que se pueden realizar en NumPy también se pueden realizar en Pandas.
Por ejemplo, operaciones aritméticas, estadísticas y de álgebra lineal que se ejecutan en arrays de NumPy pueden ser aplicadas a los Series y DataFrame de Pandas de manera similar.
import numpy as np
import pandas as pd
# Creando un DataFrame de Pandas a partir de arrays de NumPy
data = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
df = pd.DataFrame(data, columns=['A', 'B', 'C'])
# Realizando operaciones aritméticas usando Pandas que son compatibles con NumPy
df['D'] = df['A'] + df['B']
print(df)
Otra relación fundamental es la capacidad de conversión entre estructuras de datos de NumPy y Pandas. Un DataFrame de Pandas se puede convertir fácilmente a un array de NumPy utilizando el método .values o .to_numpy(), y viceversa.
# Convertir un DataFrame de Pandas a un array de NumPy
array_from_df = df.to_numpy()
print(array_from_df)
# Convertir un array de NumPy a un DataFrame de Pandas
array = np.array([[10, 20, 30], [40, 50, 60]])
df_from_array = pd.DataFrame(array, columns=['X', 'Y', 'Z'])
print(df_from_array)
La interoperabilidad entre NumPy y Pandas facilita el flujo de análisis de datos, permitiendo realizar operaciones complejas de manera eficiente. Por ejemplo, se pueden utilizar las funciones avanzadas de NumPy para realizar cálculos matemáticos intensivos sobre un DataFrame.
Además de compartir muchas funciones y operaciones, Pandas también se beneficia de NumPy para mejorar el rendimiento. Muchas operaciones en Pandas son internamente operadas a través de métodos vectorizados de NumPy, lo que las hace extremadamente rápidas y eficientes, especialmente cuando se manejan grandes conjuntos de datos.
Por último, es importante destacar que algunos de los métodos y atributos en Pandas están diseñados para ser compatibles con NumPy. Esto permite a los desarrolladores que ya están familiarizados con NumPy, transitar sin problema alguno y aprovechar las capacidades adicionales de Pandas.
# Utilizando atributos de NumPy directamente en un DataFrame de Pandas
df_mean = df.mean(axis=0) # Calcula la media de cada columna
print(df_mean)
¿Por qué es recomendable saber NumPy antes de aprender Pandas?
Conocer NumPy antes de aprender Pandas proporciona una base sólida que facilita la comprensión y la utilización eficiente de Pandas. NumPy ofrece conceptos y estructuras de datos fundamentales que Pandas amplía y complementa para análisis de datos más complejos. Entender NumPy puede dar varias ventajas significativas al trabajar con Pandas:
Eficiencia computacional: NumPy está diseñado para operaciones eficientes sobre grandes conjuntos de datos numéricos mediante el uso de arrays multidimensionales y operaciones vectorizadas, lo que minimiza el tiempo de ejecución y maximiza la eficiencia. Pandas, aunque más rico en funcionalidad, hereda esta eficiencia de NumPy.
Fundamentos de manejo de datos: Las estructuras de datos básicas de NumPy, como arrays y matrices, son cruciales para entender cómo trabaja Pandas internamente. Las operaciones comunes en NumPy, como la indexación, la manipulación de datos y las operaciones aritméticas, tienen sus equivalentes en Pandas. Esto permite que los usuarios apliquen sus conocimientos de NumPy directamente a los Series y DataFrame de Pandas.
import numpy as np
import pandas as pd
# Operaciones de NumPy
array = np.array([1, 2, 3, 4])
print(array * 2) # Vectorización en NumPy
# Operaciones similares en Pandas
series = pd.Series([1, 2, 3, 4])
print(series * 2) # Vectorización en Pandas
Interoperabilidad: Como Pandas se construye sobre NumPy, es común que los conjuntos de datos en Pandas se conviertan a arrays de NumPy para procesamientos específicos y viceversa. Conocer NumPy permite que estas conversiones y manipulaciones sean más intuitivas y eficientes.
# Convertir un DataFrame de Pandas a un array de NumPy
df = pd.DataFrame({'A': [1, 2, 3, 4]})
np_array = df.to_numpy()
print(np_array)
# Convertir un array de NumPy a un DataFrame de Pandas
reverse_df = pd.DataFrame(np_array, columns=['A'])
print(reverse_df)
Operaciones matemáticas y estadísticas avanzadas: NumPy proporciona una amplia gama de funciones matemáticas y estadísticas que se pueden aplicar directamente o en combinación con Pandas para análisis de datos complejos. Conocer estas funciones de antemano hace que su uso en Pandas sea más accesible y potente.
# Algunas operaciones estadísticas en NumPy
data = np.array([1, 2, 3, 4, 5])
print(np.mean(data)) # Media
print(np.std(data)) # Desviación estándar
# Operaciones similares en Pandas
series = pd.Series([1, 2, 3, 4, 5])
print(series.mean()) # Media
print(series.std()) # Desviación estándar
Manipulación y limpieza de datos: Los conocimientos adquiridos en NumPy sobre manipulación y limpieza de datos también se aplican a Pandas. Pandas amplía estas capacidades con funciones adicionales y una sintaxis más intuitiva para operaciones complejas. Sin embargo, las habilidades básicas de manejo de datos en NumPy son transferibles y beneficiosas.
Compatibilidad con otras librerías de ciencia de datos: NumPy es una base nuclear sobre la cual se construyen muchas librerías de ciencia de datos como SciPy, Matplotlib y Scikit-learn. Conocer NumPy permite una integración más fluida con estas herramientas y una transición más suave entre diferentes librerías, consolidando así un flujo de trabajo más eficiente.
En resumen, dominar NumPy proporciona una comprensión profunda de la estructura y eficiencia sobre las cuales se construye Pandas, permitiendo un uso más efectivo y avanzado de las capacidades de Pandas en análisis de datos.
¿Qué sintaxis de operaciones y funciones de NumPy son compartidas en Pandas?
Pandas utiliza la infraestructura de NumPy, permitiendo que muchas de las operaciones y funciones de NumPy sean aplicables directamente a los objetos Series y DataFrame. A continuación, se detallan algunas de las sintaxis, operaciones y funciones clave que ambos comparten:
Operaciones aritméticas
Las operaciones aritméticas básicas como suma, resta, multiplicación y división son soportadas tanto en NumPy como en Pandas. Estas operaciones se aplican de forma element-wise, es decir, elemento por elemento.
import numpy as np
import pandas as pd
# Arrays de NumPy
arr1 = np.array([1, 2, 3])
arr2 = np.array([4, 5, 6])
print(arr1 + arr2) # Resultado: [5 7 9]
# Series de Pandas
s1 = pd.Series([1, 2, 3])
s2 = pd.Series([4, 5, 6])
print(s1 + s2) # Resultado: 0 5 1 7 2 9 dtype: int64
Operaciones de agregación
Las funciones de agregación en NumPy como sum(), mean(), y std() están disponibles en Pandas para Series y DataFrame.
# NumPy
arr = np.array([1, 2, 3, 4])
print(np.sum(arr)) # Resultado: 10
print(np.mean(arr)) # Resultado: 2.5
# Pandas
df = pd.DataFrame({'col1': [1, 2, 3, 4], 'col2': [5, 6, 7, 8]})
print(df.sum()) # Resultado: col1 10 col2 26 dtype: int64
print(df.mean()) # Resultado: col1 2.5 col2 6.5 dtype: float64
Indexación y segmentación (Slicing)
La indexación y el slicing en Pandas utilizan una sintaxis similar a NumPy, lo que facilita la selección de subconjuntos de datos.
# Arrays de NumPy
arr = np.array([10, 20, 30, 40, 50])
print(arr[1:4]) # Resultado: [20 30 40]
# DataFrame de Pandas
df = pd.DataFrame({'A': [10, 20, 30, 40, 50], 'B': [15, 25, 35, 45, 55]})
print(df.iloc[1:4]) # Selecciona filas de la 1 a la 3
Funciones universales (ufuncs)
Las ufuncs de NumPy, como np.exp(), np.sin(), y np.log(), también se aplican directamente a objetos Pandas.
# NumPy
arr = np.array([1, 2, 3])
print(np.exp(arr)) # Resultado: [ 2.71828183 7.3890561 20.08553692]
# Pandas
s = pd.Series([1, 2, 3])
print(np.exp(s)) # Resultado: 0 2.718282 1 7.389056 2 20.085537 dtype: float64
Transposición
Al igual que en NumPy, los DataFrames de Pandas puede ser transpuestos para cambiar filas por columnas y viceversa.
# NumPy
arr = np.array([[1, 2, 3], [4, 5, 6]])
print(arr.T) # Resultado: [[1 4] [2 5] [3 6]]
# Pandas
df = pd.DataFrame({'A': [1, 2], 'B': [3, 4]})
print(df.T) # Resultado: 0 1 A 1 2 B 3 4
Operaciones de lógica y comparación
Las operaciones de comparación y funciones lógicas (>, <, ==, np.logical_and(), etc.) también son compartidas entre NumPy y Pandas.
# NumPy
arr = np.array([1, 2, 3])
print(arr > 1) # Resultado: [False True True]
# Pandas
s = pd.Series([1, 2, 3])
print(s > 1) # Resultado: 0 False 1 True 2 True dtype: bool
Aplicación de funciones (apply, map)
La capacidad de aplicar funciones en los elementos es una característica compartida entre NumPy y Pandas.
# NumPy
arr = np.array([1, 2, 3])
print(np.vectorize(lambda x: x * 2)(arr)) # Resultado: [2 4 6]
# Pandas
df = pd.DataFrame({'A': [1, 2, 3]})
print(df['A'].apply(lambda x: x * 2)) # Resultado: 0 2 1 4 2 6 Name: A dtype: int64
El dominio de estas operaciones y funciones compartidas permite a los ingenieros de software moverse sin problemas entre NumPy y Pandas, aprovechando la eficiencia de NumPy y la flexibilidad y funcionalidad adicional que ofrece Pandas para el análisis de datos.

Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, NumPy es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de NumPy
Explora más contenido relacionado con NumPy y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
\\- Comprender las estructuras de datos Series y DataFrame en Pandas. \\- Aplicar operaciones aritméticas, de agregación y lógicas en Pandas. \\- Convertir entre estructuras de datos de Numpy y Pandas. \\- Manipular y limpiar datos usando métodos de Pandas. \\- Realizar operaciones avanzadas de análisis de datos combinando Numpy y Pandas.
Cursos que incluyen esta lección
Esta lección forma parte de los siguientes cursos estructurados con rutas de aprendizaje