Formatos de almacenamiento en NumPy
flowchart LR
A[ndarray] --> B[shape]
A --> C[dtype]
A --> D[strides]
B --> E[Operaciones vectorizadas]
C --> E
D --> E
E --> F[Broadcasting]
F --> G[Resultado ndarray]
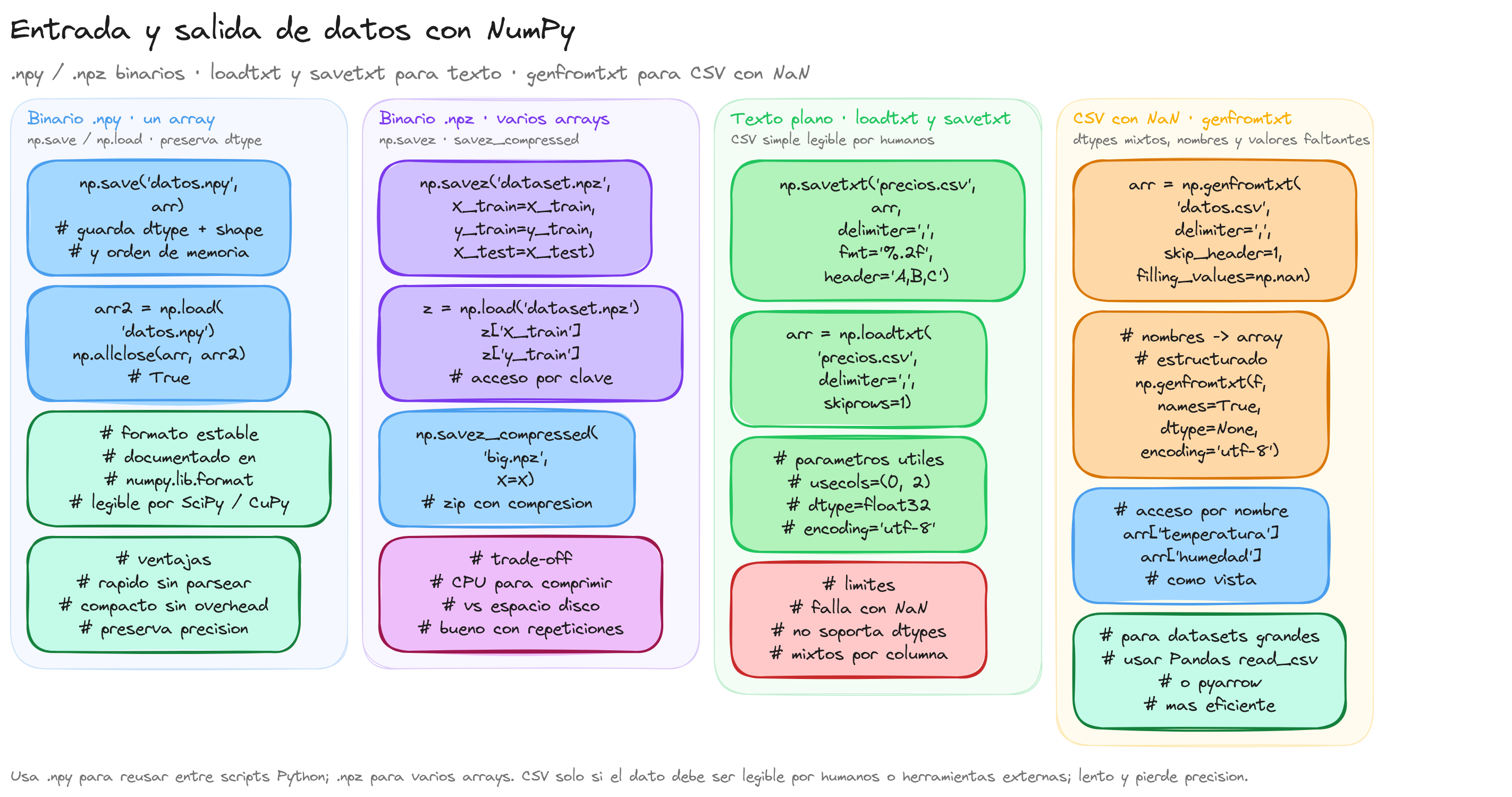
NumPy proporciona funciones de entrada y salida nativas para persistir arrays sin necesidad de convertirlos a listas de Python ni recurrir al módulo csv. Existen dos familias principales:
- Formato binario (
.npy,.npz): preserva eldtype, la forma y el orden de memoria exactos. Es el más rápido y compacto para reusar datos entre scripts Python. - Formato de texto (
.txt,.csv): legible por humanos y compatible con herramientas externas (Excel, R, Julia), pero más lento y pierde precisión en tipos de punto flotante si no se configura correctamente.
Guardar y cargar un único array: np.save y np.load
np.save serializa un único ndarray en un archivo .npy. El formato binario incluye una cabecera con dtype, shape y orden de memoria (C o Fortran).
import numpy as np
# Crear un array de ejemplo: matriz de 100 filas y 5 columnas
rng = np.random.default_rng(42)
datos = rng.standard_normal((100, 5))
# Guardar en disco
np.save("datos_experimento.npy", datos)
# Cargar de vuelta
datos_cargados = np.load("datos_experimento.npy")
print(datos_cargados.shape) # (100, 5)
print(datos_cargados.dtype) # float64
print(np.allclose(datos, datos_cargados)) # True
El archivo
.npyes un formato estable documentado en la especificación oficial de NumPy. Puede ser leído por otras implementaciones (SciPy, CuPy) que respeten el estándar.
Guardar múltiples arrays: np.savez y np.savez_compressed
Cuando se trabaja con varios arrays relacionados (por ejemplo, datos de entrenamiento y etiquetas), np.savez los empaqueta en un único archivo .npz, que es un archivo ZIP sin compresión. Cada array se identifica por una clave.
import numpy as np
rng = np.random.default_rng(0)
X_train = rng.random((80, 4))
y_train = rng.integers(0, 3, size=80)
X_test = rng.random((20, 4))
y_test = rng.integers(0, 3, size=20)
# Guardar todos juntos
np.savez("dataset_iris_sim.npz",
X_train=X_train, y_train=y_train,
X_test=X_test, y_test=y_test)
# Cargar
archivo = np.load("dataset_iris_sim.npz")
print(list(archivo.keys())) # ['X_train', 'y_train', 'X_test', 'y_test']
print(archivo["X_train"].shape) # (80, 4)
print(archivo["y_train"][:5]) # primeras 5 etiquetas
Para datasets grandes conviene usar np.savez_compressed, que aplica compresión ZIP. El tiempo de escritura y lectura aumenta ligeramente, pero el tamaño en disco puede reducirse de forma notable en arrays con muchos valores similares.
# Versión comprimida
np.savez_compressed("dataset_comprimido.npz",
X_train=X_train, y_train=y_train)
# La carga es idéntica
archivo_c = np.load("dataset_comprimido.npz")
print(archivo_c["X_train"].shape) # (80, 4)
Comparación de tamaños
import os
np.save("a.npy", X_train)
np.savez("a.npz", X=X_train)
np.savez_compressed("a_c.npz", X=X_train)
for f in ["a.npy", "a.npz", "a_c.npz"]:
print(f"{f}: {os.path.getsize(f)} bytes")
# a.npy: 2624 bytes (más pequeño porque no hay overhead ZIP)
# a.npz: 2750 bytes
# a_c.npz: 2630 bytes (compresión apenas ayuda con datos aleatorios)
Texto plano: np.savetxt y np.loadtxt
np.savetxt escribe un array 2D en un archivo de texto con el delimitador y formato especificados. Es útil para intercambiar datos con herramientas que no leen .npy.
import numpy as np
precios = np.array([[10.5, 20.0, 30.75],
[15.2, 25.8, 35.0 ],
[12.0, 22.3, 32.1 ]])
# Guardar como CSV con 2 decimales y cabecera
np.savetxt("precios.csv",
precios,
delimiter=",",
fmt="%.2f",
header="producto_A,producto_B,producto_C",
comments="") # sin el '#' por defecto en la cabecera
# Cargar de vuelta
precios_cargados = np.loadtxt("precios.csv",
delimiter=",",
skiprows=1) # saltar la cabecera
print(precios_cargados)
# [[10.5 20. 30.75]
# [15.2 25.8 35. ]
# [12. 22.3 32.1 ]]
Parámetros importantes de np.loadtxt
| Parámetro | Descripción |
|-----------|-------------|
| delimiter | Separador de columnas (,, \t, ...) |
| skiprows | Número de filas iniciales a ignorar |
| usecols | Índices o nombres de columnas a cargar |
| dtype | Tipo de dato de salida (por defecto float64) |
| encoding | Codificación del archivo (por defecto bytes en modo legacy) |
# Cargar solo las dos primeras columnas
dos_cols = np.loadtxt("precios.csv", delimiter=",",
skiprows=1, usecols=(0, 1))
print(dos_cols.shape) # (3, 2)
CSV con valores faltantes: np.genfromtxt
np.loadtxt lanza un error si encuentra valores faltantes o columnas con tipos mixtos. Para esos casos se usa np.genfromtxt, que permite especificar el valor de relleno para celdas vacías y el tipo de cada columna.
import numpy as np
import io
# Simular un CSV con un valor faltante
csv_datos = """temperatura,humedad,presion
22.1,65,1013.2
24.5,,1010.8
19.8,70,1015.0
,72,1012.5
"""
arr = np.genfromtxt(io.StringIO(csv_datos),
delimiter=",",
skip_header=1,
filling_values=np.nan)
print(arr)
# [[22.1 65. 1013.2]
# [24.5 nan 1010.8]
# [19.8 70. 1015. ]
# [ nan 72. 1012.5]]
print(np.isnan(arr).sum()) # 2 valores faltantes
Leer columnas con nombres
Activando names=True, genfromtxt lee la primera fila como nombres de campo y devuelve un array estructurado:
arr_nombrado = np.genfromtxt(io.StringIO(csv_datos),
delimiter=",",
names=True,
dtype=None,
encoding="utf-8",
filling_values=np.nan)
print(arr_nombrado.dtype.names) # ('temperatura', 'humedad', 'presion')
print(arr_nombrado["temperatura"]) # [22.1 24.5 19.8 nan]
Cuándo elegir cada formato
| Caso de uso | Formato recomendado |
|-------------|---------------------|
| Intercambio entre scripts Python | .npy (un array) o .npz (varios) |
| Checkpoint de entrenamiento ML | .npz o .npz_compressed |
| Datasets grandes con compresión | .npz_compressed |
| Compartir con Excel, R o Julia | .csv via np.savetxt |
| CSV con valores faltantes | np.genfromtxt |
| Datos con tipos mixtos por columna | np.genfromtxt con dtype=None |
Para datasets muy grandes (>100 MB) se recomienda considerar formatos como HDF5 (via
h5py) o Parquet (via PyArrow / Pandas), que ofrecen acceso aleatorio y compresión más eficiente que.npz.
Ejemplo completo: pipeline de datos con persistencia
import numpy as np
rng = np.random.default_rng(2024)
# 1. Generar dataset simulado
n_muestras = 500
X = rng.standard_normal((n_muestras, 10))
y = (X[:, 0] + 0.5 * X[:, 1] + rng.standard_normal(n_muestras) > 0).astype(int)
# 2. Dividir en train/test
corte = int(0.8 * n_muestras)
X_train, X_test = X[:corte], X[corte:]
y_train, y_test = y[:corte], y[corte:]
# 3. Normalizar (z-score sobre train, aplicar los mismos parámetros a test)
media = X_train.mean(axis=0)
std = X_train.std(axis=0)
X_train_norm = (X_train - media) / std
X_test_norm = (X_test - media) / std
# 4. Guardar todo en un solo archivo
np.savez_compressed("dataset_procesado.npz",
X_train=X_train_norm,
y_train=y_train,
X_test=X_test_norm,
y_test=y_test,
media=media,
std=std)
# 5. Cargar en otra sesión
datos = np.load("dataset_procesado.npz")
print(datos["X_train"].shape) # (400, 10)
print(datos["y_test"].sum()) # número de positivos en test
Este patrón evita recalcular el preprocesamiento en cada ejecución y garantiza que los parámetros de normalización (media y std) se almacenen junto a los datos normalizados.

Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, NumPy es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de NumPy
Explora más contenido relacionado con NumPy y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Guardar y cargar arrays binarios con np.save, np.load y np.savez. Leer y escribir datos numéricos en texto plano con np.savetxt y np.loadtxt. Manejar archivos CSV con columnas heterogéneas usando np.genfromtxt. Entender las diferencias de rendimiento entre formatos .npy, .npz y texto.
Cursos que incluyen esta lección
Esta lección forma parte de los siguientes cursos estructurados con rutas de aprendizaje