Qué son los arrays estructurados
flowchart LR
A[ndarray] --> B[shape]
A --> C[dtype]
A --> D[strides]
B --> E[Operaciones vectorizadas]
C --> E
D --> E
E --> F[Broadcasting]
F --> G[Resultado ndarray]
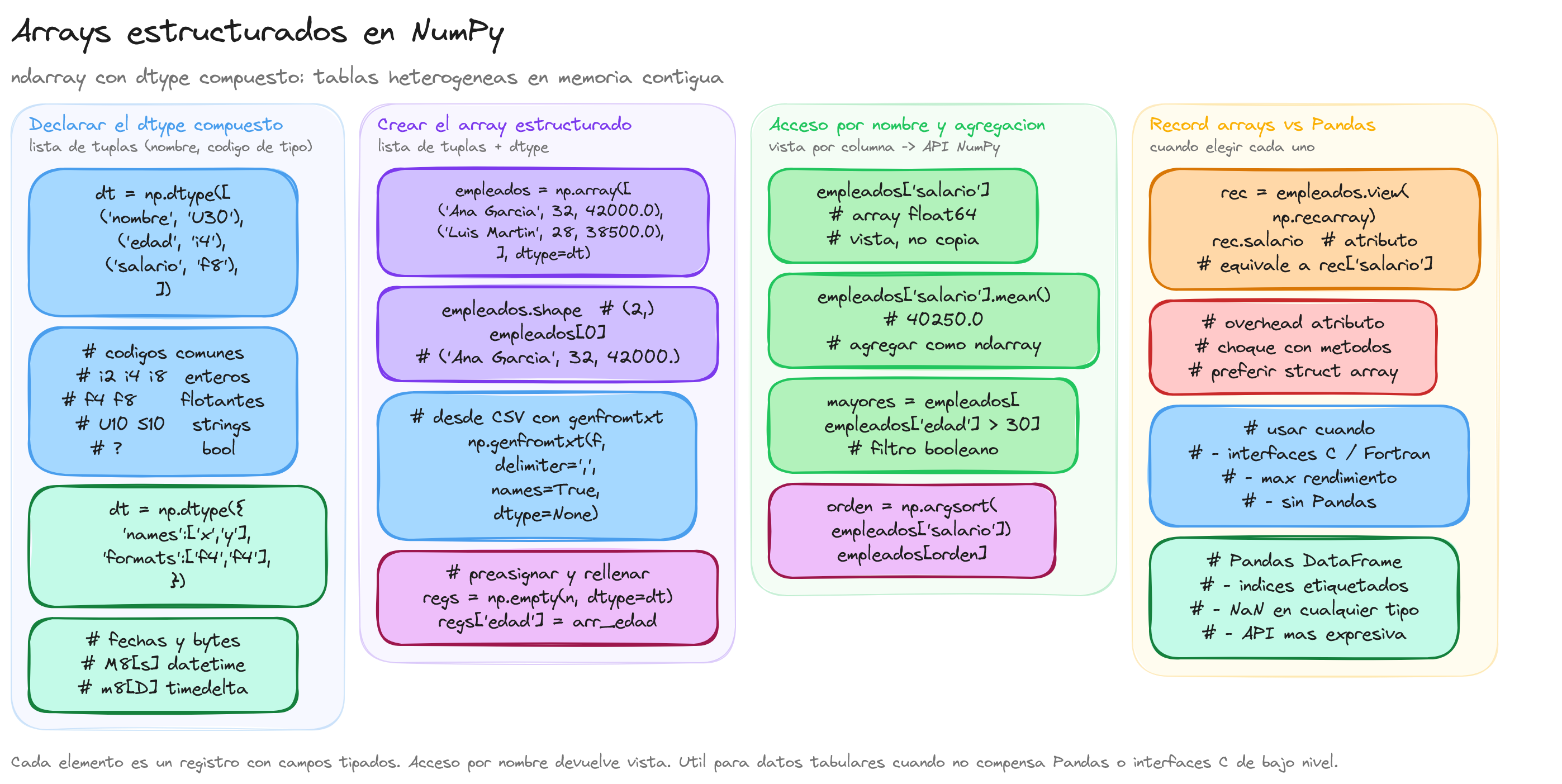
Un array estructurado es un ndarray cuyo dtype es un tipo compuesto: cada elemento del array es un registro con varios campos, y cada campo puede tener su propio tipo de datos (int32, float64, U20...). Es el equivalente NumPy a una tabla de base de datos o a un struct de C.
La diferencia fundamental con un array homogéneo estándar es que el dtype ya no es un tipo único sino una lista de pares (nombre, tipo).
import numpy as np
# Array homogéneo: todos los elementos del mismo tipo
a = np.array([1.0, 2.5, 3.7])
print(a.dtype) # float64
# Array estructurado: cada elemento tiene campos nombre, edad y salario
dtype_empleado = np.dtype([
("nombre", "U30"), # cadena Unicode de hasta 30 caracteres
("edad", "i4"), # entero de 32 bits
("salario", "f8"), # float de 64 bits
])
empleados = np.array([
("Ana García", 32, 42000.0),
("Luis Martín", 28, 38500.0),
("María López", 41, 55000.0),
], dtype=dtype_empleado)
print(empleados.dtype)
# [('nombre', '<U30'), ('edad', '<i4'), ('salario', '<f8')]
Acceso a campos por nombre
La característica clave de los arrays estructurados es el acceso por nombre de campo, que devuelve una vista (no una copia) del array original:
# Columna de nombres: devuelve un array 1D de strings
print(empleados["nombre"])
# ['Ana García' 'Luis Martín' 'María López']
# Columna de salarios
print(empleados["salario"])
# [42000. 38500. 55000.]
# Acceder a un registro individual (fila)
print(empleados[0])
# ('Ana García', 32, 42000.)
# Campo de un registro individual
print(empleados[0]["nombre"])
# 'Ana García'
La vista por campo permite aplicar operaciones de NumPy directamente sobre una columna:
# Salario medio
print(empleados["salario"].mean()) # 45166.67
# Filtrar por edad
mayores_de_30 = empleados[empleados["edad"] > 30]
print(mayores_de_30["nombre"])
# ['Ana García' 'María López']
# Incremento de salario del 10% a los mayores de 30
empleados["salario"][empleados["edad"] > 30] *= 1.10
print(empleados["salario"])
# [46200. 38500. 60500.]
Definir dtypes con múltiples notaciones
NumPy acepta varias formas de especificar un dtype compuesto:
import numpy as np
# Forma 1: lista de tuplas (nombre, tipo)
dt1 = np.dtype([("x", "f4"), ("y", "f4"), ("etiqueta", "U10")])
# Forma 2: diccionario con 'names' y 'formats'
dt2 = np.dtype({
"names": ["x", "y", "etiqueta"],
"formats": ["f4", "f4", "U10"]
})
# Forma 3: string de tipo C-style (menos legible, sin nombres)
dt3 = np.dtype("f4, f4, U10") # sin nombres de campo
print(dt1 == dt2) # True
Tipos habituales en arrays estructurados
| Código | Tipo Python/NumPy | Descripción |
|--------|-------------------|-------------|
| i2, i4, i8 | int16, int32, int64 | Enteros con signo |
| u2, u4, u8 | uint16, uint32, uint64 | Enteros sin signo |
| f4, f8 | float32, float64 | Flotantes |
| U{n} | str | Unicode de hasta n caracteres |
| S{n} | bytes | Bytes ASCII de hasta n caracteres |
| ? | bool | Booleano |
| M8[D] | datetime64[D] | Fecha con precisión de día |
Arrays estructurados y CSV
np.genfromtxt puede crear directamente un array estructurado desde un CSV usando dtype=None (inferencia de tipos) o especificando el dtype explícitamente:
import numpy as np
import io
csv = """nombre,temp_max,temp_min,lluvia
Madrid,35.2,22.1,0.0
Barcelona,30.5,20.8,2.3
Valencia,33.1,24.5,0.0
Bilbao,25.0,16.2,12.5
"""
# Inferencia automática de tipos
datos = np.genfromtxt(
io.StringIO(csv),
delimiter=",",
names=True,
dtype=None,
encoding="utf-8"
)
print(datos.dtype)
# [('nombre', '<U9'), ('temp_max', '<f8'), ('temp_min', '<f8'), ('lluvia', '<f8')]
# Ordenar por temperatura máxima
orden = np.argsort(datos["temp_max"])[::-1]
print(datos["nombre"][orden])
# ['Madrid' 'Valencia' 'Barcelona' 'Bilbao']
Record arrays: acceso como atributos
np.recarray es una subclase de np.ndarray que permite acceder a los campos como atributos en lugar de como claves de diccionario. Se obtiene llamando a .view(np.recarray) sobre un array estructurado:
import numpy as np
dtype_punto = np.dtype([("x", "f8"), ("y", "f8"), ("z", "f8")])
puntos = np.array([(1.0, 2.0, 3.0),
(4.0, 5.0, 6.0),
(7.0, 8.0, 9.0)], dtype=dtype_punto)
# Convertir a recarray
rec = puntos.view(np.recarray)
# Acceso como atributo (equivalente a rec["x"])
print(rec.x) # [1. 4. 7.]
print(rec.y) # [2. 5. 8.]
# Calcular la norma euclidiana de cada punto
normas = np.sqrt(rec.x**2 + rec.y**2 + rec.z**2)
print(normas.round(2)) # [ 3.74 8.77 13.93]
Aunque los
recarrayson convenientes para código interactivo, en producción se prefieren los arrays estructurados estándar porquerecarraytiene un ligero overhead de acceso por atributo y puede generar confusión cuando un campo tiene el mismo nombre que un método de NumPy.
Arrays estructurados vs Pandas DataFrame
| Aspecto | Array estructurado | Pandas DataFrame | |---------|-------------------|------------------| | Tipos por columna | Sí | Sí | | Valores faltantes (NaN) | Limitado (solo en float) | Total (pd.NA, NaN, NaT) | | Operaciones de datos | API NumPy | API Pandas más expresiva | | Memoria | Contigua, muy eficiente | Mayor overhead | | Indexación de filas | Solo enteros | Índice etiquetado | | Rendimiento en cálculo | Excelente | Bueno (usa NumPy internamente) | | Facilidad de uso | Media | Alta |
Los arrays estructurados resultan especialmente útiles cuando:
- Se trabaja con interfaces de bajo nivel (C, Fortran, archivos binarios) que definen structs.
- Se necesita máximo rendimiento en memoria contigua con tipos heterogéneos.
- Se usa
np.genfromtxtcondtype=Nonepara cargar datos tabulares sin Pandas.
Ejemplo práctico: análisis de registros de sensores
import numpy as np
# Simular registros de sensores IoT
rng = np.random.default_rng(2024)
n = 1000
dtype_sensor = np.dtype([
("timestamp", "M8[s]"), # datetime64 con precisión de segundos
("sensor_id", "u2"), # entero sin signo de 16 bits (id 0-65535)
("temperatura", "f4"), # float32
("humedad", "f4"),
("activo", "?"), # booleano
])
# Generar datos sintéticos
segundos_base = np.datetime64("2026-01-01T00:00:00", "s")
registros = np.empty(n, dtype=dtype_sensor)
registros["timestamp"] = segundos_base + np.arange(n).astype("timedelta64[s]")
registros["sensor_id"] = rng.integers(0, 10, n).astype("u2")
registros["temperatura"] = rng.uniform(15.0, 35.0, n).astype("f4")
registros["humedad"] = rng.uniform(40.0, 90.0, n).astype("f4")
registros["activo"] = rng.integers(0, 2, n, dtype=bool)
# Análisis: temperatura media por sensor para sensores activos
activos = registros[registros["activo"]]
for sid in range(10):
mask = activos["sensor_id"] == sid
if mask.any():
temp_media = activos["temperatura"][mask].mean()
print(f"Sensor {sid}: {temp_media:.2f} °C ({mask.sum()} lecturas)")
Los arrays estructurados permiten representar estos registros en un único bloque de memoria contigua, lo que facilita operaciones de filtrado y agregación con el API familiar de NumPy.

Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, NumPy es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de NumPy
Explora más contenido relacionado con NumPy y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Definir tipos de datos compuestos con np.dtype para crear arrays estructurados. Acceder a campos por nombre en un array estructurado. Convertir listas de diccionarios o tablas CSV a arrays estructurados. Usar np.recarray para acceder a campos como atributos. Conocer las limitaciones de los arrays estructurados frente a Pandas.
Cursos que incluyen esta lección
Esta lección forma parte de los siguientes cursos estructurados con rutas de aprendizaje