
Bases de datos vectoriales
Ahora que ya tienes claro qué son los embeddings, viene el siguiente paso: ¿dónde los guardas y cómo los organizas para poder buscar eficientemente? Aquí es donde entran las bases de datos vectoriales.
Una base de datos vectorial es como un almacén organizado donde cada embedding (que recordarás que es una lista de números) se guarda junto con el texto original del que procede. Pero no es un almacén cualquiera, está diseñado específicamente para encontrar vectores similares de forma rapidísima.
Imagínate que tienes miles de documentos. Cada uno se convierte en embeddings y se almacena en esta base de datos. Cuando llega tu pregunta, el sistema:
- Convierte tu pregunta en embeddings
- Busca en la base de datos vectorial qué embeddings son más parecidos
- Recupera los textos originales correspondientes a esos embeddings similares
El truco está en que estas bases de datos usan algoritmos especiales para comparar vectores. En lugar de mirar documento por documento (que sería lentísimo), crean una especie de "mapa" donde vectores similares están cerca unos de otros.
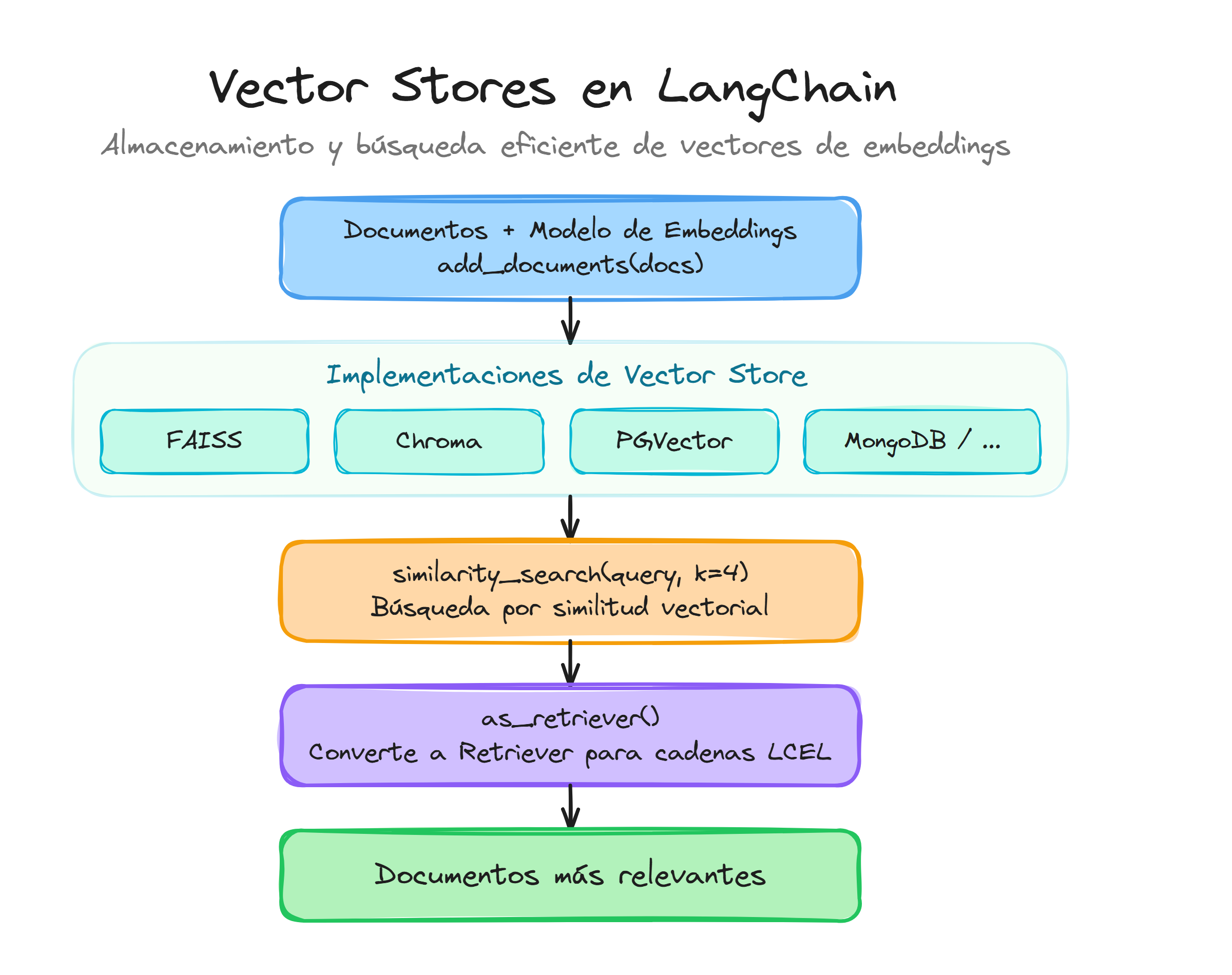
Las más conocidas son Pinecone, Weaviate, Chroma, FAISS o PGVector. Cada una tiene sus ventajas, pero todas hacen lo mismo: permiten hacer búsquedas por similitud semántica en milisegundos, aunque tengas millones de documentos.
FAISS para prototipado rápido
FAISS (Facebook AI Similarity Search) representa una excelente opción para comenzar a trabajar con vector stores en proyectos de RAG. Esta biblioteca, desarrollada por Meta, está optimizada para realizar búsquedas de similaridad de manera eficiente y no requiere configuración de servidores externos.
Ventajas de FAISS para desarrollo inicial
FAISS destaca por su simplicidad de implementación y su capacidad para manejar grandes volúmenes de vectores sin necesidad de infraestructura compleja. A diferencia de soluciones que requieren bases de datos dedicadas, FAISS funciona completamente en memoria o puede persistir en archivos locales.
Configuración básica con LangChain
Para comenzar a utilizar FAISS en LangChain:
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
documentos = [
"Python es un lenguaje de programación versátil y fácil de aprender.",
"LangChain facilita la construcción de aplicaciones con modelos de lenguaje.",
"Los vector stores permiten búsquedas semánticas eficientes.",
"FAISS es una biblioteca optimizada para búsquedas de similaridad."
]
Creación del vector store desde documentos
El método más directo para crear un vector store FAISS es utilizando from_texts():
vector_store = FAISS.from_texts(
texts=documentos,
embedding=embeddings
)
print(f"Vector store creado con {vector_store.index.ntotal} documentos")
Para casos más complejos donde trabajamos con objetos Document:
from langchain_core.documents import Document
docs = [
Document(
page_content="Python es un lenguaje de programación versátil.",
metadata={"categoria": "programacion", "nivel": "basico"}
),
Document(
page_content="LangChain facilita el desarrollo con LLMs.",
metadata={"categoria": "ia", "nivel": "intermedio"}
)
]
vector_store = FAISS.from_documents(
documents=docs,
embedding=embeddings
)
Persistencia y carga del índice
Una característica fundamental de FAISS es su capacidad para persistir el índice en disco:
# Guardar el vector store en disco
vector_store.save_local("mi_indice_faiss")
# Cargar vector store existente
vector_store_cargado = FAISS.load_local(
"mi_indice_faiss",
embeddings,
allow_dangerous_deserialization=True
)
Operaciones básicas: indexar y buscar
Una vez configurado nuestro vector store FAISS, las operaciones fundamentales que realizaremos son indexar nuevos documentos y ejecutar búsquedas por similaridad.
Indexación de documentos individuales
La indexación dinámica permite agregar nuevos documentos al vector store:
# Agregar un nuevo documento
nuevo_texto = "FastAPI es un framework web moderno para Python"
vector_store.add_texts([nuevo_texto])
print(f"Total de documentos: {vector_store.index.ntotal}")
Para documentos con metadatos específicos:
nuevos_textos = [
"Django es un framework web completo para Python",
"Flask es un microframework minimalista para web"
]
metadatos = [
{"framework": "django", "tipo": "completo"},
{"framework": "flask", "tipo": "micro"}
]
vector_store.add_texts(
texts=nuevos_textos,
metadatas=metadatos
)
Búsquedas por similaridad básicas
El método similarity_search() constituye la operación de búsqueda principal:
query = "¿Qué frameworks web existen para Python?"
resultados = vector_store.similarity_search(
query=query,
k=3
)
for i, doc in enumerate(resultados):
print(f"Resultado {i+1}: {doc.page_content}")
if doc.metadata:
print(f"Metadatos: {doc.metadata}")
Búsquedas con puntuaciones de similaridad
Para obtener información más detallada sobre la relevancia de los resultados:
resultados_con_score = vector_store.similarity_search_with_score(
query="frameworks web Python",
k=3
)
for doc, score in resultados_con_score:
print(f"Puntuación: {score:.4f}")
print(f"Contenido: {doc.page_content}")
Las puntuaciones más bajas indican mayor similaridad, ya que FAISS utiliza distancia euclidiana por defecto.
Integración con retriever
Para facilitar la integración con cadenas LCEL, podemos convertir nuestro vector store en un retriever:
retriever = vector_store.as_retriever(
search_type="similarity",
search_kwargs={"k": 3}
)
documentos_recuperados = retriever.invoke("frameworks Python web")
for doc in documentos_recuperados:
print(f"Recuperado: {doc.page_content[:100]}...")
Alternativa más directa
Una posibilidad es usar InMemoryVectorStore del propio LangChain Core:
from langchain_core.vectorstores import InMemoryVectorStore
vector_store = InMemoryVectorStore(embeddings)
vector_store.add_documents(docs)
resultados = vector_store.similarity_search("consulta de ejemplo", k=3)
Esto permite realizar pruebas rápidas. No obstante, para entornos de producción reales es recomendable utilizar una base de datos vectorial como ChromaDB o PGVector.
Criterios de selección de vector store
La elección del vector store adecuado depende de varios factores del proyecto:
- FAISS / InMemoryVectorStore: Ideales para prototipado rápido y pruebas. Sin persistencia automática (FAISS puede persistir en fichero). No requieren infraestructura externa.
- ChromaDB: Buena opción para proyectos de tamaño medio que necesitan persistencia y arquitectura cliente-servidor sin complejidad empresarial.
- PGVector: Recomendable para entornos empresariales que ya utilizan PostgreSQL, ya que combina búsqueda vectorial con consultas SQL y garantías ACID.
En las próximas lecciones veremos ChromaDB y PGVector como opciones de producción.
Fuentes y referencias
Documentación oficial y recursos externos para profundizar en LangChain
Documentación oficial de LangChain
Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, LangChain es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de LangChain
Explora más contenido relacionado con LangChain y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Comprender qué son las bases de datos vectoriales y su propósito en RAG, usar FAISS para almacenamiento en memoria, trabajar con ChromaDB y PGVector para producción, realizar búsquedas por similitud, y entender métricas de distancia y configuración de retrievers.
Cursos que incluyen esta lección
Esta lección forma parte de los siguientes cursos estructurados con rutas de aprendizaje