
Qué es el streaming
El streaming es una técnica que permite recibir la respuesta de un modelo de lenguaje de forma progresiva, token a token, en lugar de esperar a que se genere la respuesta completa. Esta funcionalidad resulta especialmente útil para mejorar la experiencia de usuario en aplicaciones interactivas, ya que reduce la percepción de latencia al mostrar el contenido a medida que se genera.
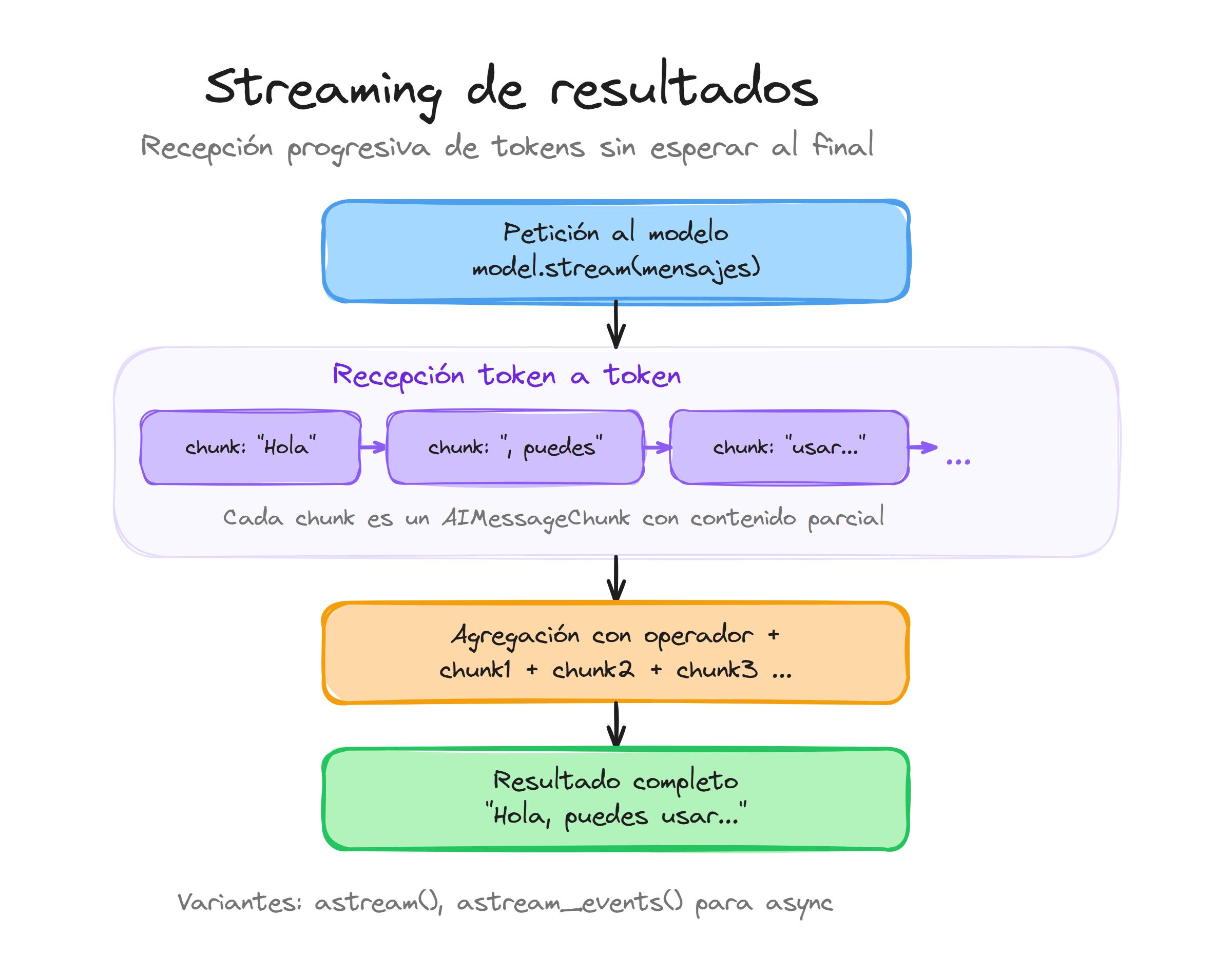
Cuando invocamos un modelo con el método invoke(), debemos esperar hasta que el modelo termine de generar toda la respuesta para poder mostrarla. En respuestas largas, esto puede significar varios segundos de espera sin ningún feedback visual. El streaming resuelve este problema permitiendo procesar cada fragmento de la respuesta en tiempo real.
Método stream
El método stream() es la forma principal de implementar streaming en LangChain. Este método devuelve un iterador que produce objetos AIMessageChunk a medida que el modelo los genera:
from langchain.chat_models import init_chat_model
model = init_chat_model("gpt-5.4")
# Streaming básico: procesamos cada chunk en tiempo real
for chunk in model.stream("Explica brevemente qué es Python"):
print(chunk.text, end="", flush=True)
Cada iteración del bucle recibe un fragmento de texto que podemos mostrar inmediatamente. El parámetro end="" evita saltos de línea entre fragmentos, y flush=True fuerza la escritura inmediata en la salida.
Trabajar con AIMessageChunk
A diferencia de invoke(), que devuelve un único objeto AIMessage con la respuesta completa, stream() devuelve múltiples objetos AIMessageChunk. Cada chunk contiene una porción del texto generado junto con metadatos adicionales:
from langchain.chat_models import init_chat_model
model = init_chat_model("gpt-5.4")
chunks_recibidos = []
for chunk in model.stream("¿Cuáles son los planetas del sistema solar?"):
chunks_recibidos.append(chunk)
print(f"Chunk recibido: '{chunk.text}'")
print(f"\nTotal de chunks: {len(chunks_recibidos)}")
Agregación de chunks
Una característica importante de los AIMessageChunk es que pueden combinarse mediante suma para reconstruir el mensaje completo. Esto es útil cuando necesitamos tanto mostrar la respuesta progresivamente como conservar el mensaje final:
from langchain.chat_models import init_chat_model
model = init_chat_model("gpt-5.4")
mensaje_completo = None
for chunk in model.stream("Resume en dos líneas qué es la inteligencia artificial"):
# Mostramos cada chunk en tiempo real
print(chunk.text, end="", flush=True)
# Acumulamos los chunks para obtener el mensaje completo
if mensaje_completo is None:
mensaje_completo = chunk
else:
mensaje_completo = mensaje_completo + chunk
print("\n")
print(f"Texto completo: {mensaje_completo.text}")
El mensaje resultante de la agregación se comporta exactamente igual que un AIMessage obtenido con invoke(), por lo que puede usarse en un historial de conversación o procesarse posteriormente.
Streaming asíncrono
Para aplicaciones que requieren programación asíncrona, LangChain proporciona el método astream(). Este método es especialmente útil en frameworks web como FastAPI o en aplicaciones que manejan múltiples conexiones simultáneas:
import asyncio
from langchain.chat_models import init_chat_model
model = init_chat_model("gpt-5.4")
async def obtener_respuesta_streaming():
mensaje_final = None
async for chunk in model.astream("¿Qué ventajas tiene Python para ciencia de datos?"):
print(chunk.text, end="", flush=True)
mensaje_final = chunk if mensaje_final is None else mensaje_final + chunk
return mensaje_final
# Ejecutar la función asíncrona
resultado = asyncio.run(obtener_respuesta_streaming())
Streaming con historial de conversación
El streaming también funciona cuando pasamos un historial de mensajes al modelo. La estructura de la conversación se mantiene igual que con invoke():
from langchain.chat_models import init_chat_model
from langchain_core.messages import SystemMessage, HumanMessage, AIMessage
model = init_chat_model("gpt-5.4")
conversacion = [
SystemMessage(content="Eres un experto en programación Python. Responde de forma concisa."),
HumanMessage(content="¿Qué es una lista?"),
AIMessage(content="Una lista es una estructura de datos mutable que almacena elementos ordenados."),
HumanMessage(content="¿Cómo añado elementos a una lista?")
]
print("Respuesta: ", end="")
for chunk in model.stream(conversacion):
print(chunk.text, end="", flush=True)
Streaming de eventos semánticos
Para casos donde necesitamos un control más granular sobre el proceso de generación, LangChain ofrece el método astream_events(). Este método emite eventos semánticos que incluyen información sobre el inicio, progreso y finalización de la generación:
import asyncio
from langchain.chat_models import init_chat_model
model = init_chat_model("gpt-5.4")
async def streaming_con_eventos():
async for evento in model.astream_events("Describe la fotosíntesis"):
if evento["event"] == "on_chat_model_start":
print("Inicio de generación...")
elif evento["event"] == "on_chat_model_stream":
print(evento["data"]["chunk"].text, end="", flush=True)
elif evento["event"] == "on_chat_model_end":
print("\n\nGeneración completada")
print(f"Mensaje final: {evento['data']['output'].text[:50]}...")
asyncio.run(streaming_con_eventos())
Los eventos disponibles permiten detectar cuándo comienza la generación (on_chat_model_start), recibir cada token (on_chat_model_stream) y saber cuándo termina el proceso (on_chat_model_end). Esta información adicional facilita la implementación de indicadores de progreso y el manejo de errores en aplicaciones de producción.
Streaming en cadenas LCEL
Una de las ventajas más significativas del streaming en LangChain es su propagación automática a través de cadenas LCEL. Cuando conectamos un modelo con un prompt y un parser de salida, el streaming funciona de extremo a extremo sin configuración adicional:
from langchain.chat_models import init_chat_model
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
model = init_chat_model("gpt-5.4")
prompt = ChatPromptTemplate.from_template(
"Escribe un resumen de {tema} en 3 párrafos"
)
chain = prompt | model | StrOutputParser()
# El streaming funciona sobre la cadena completa
for chunk in chain.stream({"tema": "la inteligencia artificial generativa"}):
print(chunk, end="", flush=True)
El StrOutputParser extrae automáticamente el texto de cada AIMessageChunk, por lo que cada fragmento recibido es directamente una cadena de texto lista para mostrar al usuario.
Consideraciones de rendimiento
El streaming no solo mejora la percepción de velocidad, sino que también permite procesar respuestas parciales antes de que la generación termine. Esto resulta especialmente beneficioso en las siguientes situaciones:
- Interfaces de chat web: Mostrar texto progresivamente reduce la sensación de espera del usuario.
- Procesamiento por lotes: Iniciar el procesamiento del primer fragmento mientras se generan los siguientes.
- Aplicaciones con timeout: Detectar que el modelo está respondiendo aunque la generación completa tarde más de lo esperado.
import time
from langchain.chat_models import init_chat_model
model = init_chat_model("gpt-5.4")
inicio = time.time()
primer_token = None
for chunk in model.stream("Explica la teoría de la relatividad"):
if primer_token is None:
primer_token = time.time() - inicio
print(f"Primer token recibido en: {primer_token:.2f}s")
print(chunk.text, end="", flush=True)
print(f"\nTiempo total: {time.time() - inicio:.2f}s")
En la práctica, el primer token suele recibirse en menos de un segundo, mientras que la generación completa puede tardar varios segundos para respuestas largas. Esta diferencia justifica el uso de streaming en cualquier aplicación interactiva.
Fuentes y referencias
Documentación oficial y recursos externos para profundizar en LangChain
Documentación oficial de LangChain
Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, LangChain es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de LangChain
Explora más contenido relacionado con LangChain y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Usar stream() para recibir respuestas progresivas, trabajar con AIMessageChunk y agregar chunks, implementar streaming asíncrono con astream(), manejar streaming con historial de conversación, y usar astream_events() para control granular del proceso de generación.
Cursos que incluyen esta lección
Esta lección forma parte de los siguientes cursos estructurados con rutas de aprendizaje