
RecursiveCharacterTextSplitter
El RecursiveCharacterTextSplitter es la herramienta principal de LangChain para dividir documentos largos en fragmentos más pequeños y manejables. A diferencia de otros métodos de división más básicos, este splitter utiliza una estrategia jerárquica que respeta la estructura natural del texto, intentando mantener párrafos, oraciones y palabras completas siempre que sea posible.
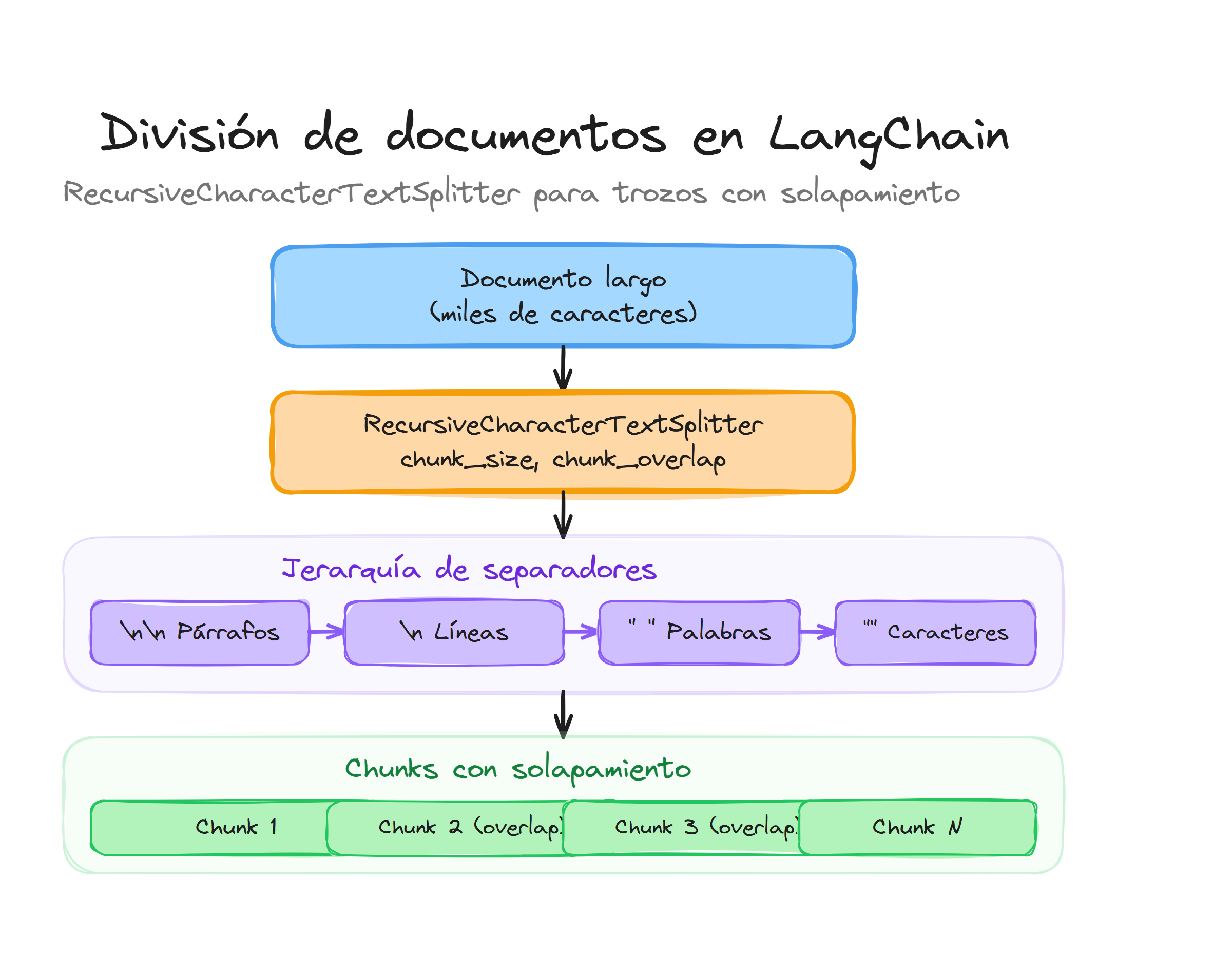
Funcionamiento interno del splitter
El RecursiveCharacterTextSplitter funciona mediante un algoritmo recursivo que intenta dividir el texto utilizando una lista ordenada de separadores. Primero intenta dividir por párrafos (dobles saltos de línea), luego por oraciones (puntos seguidos de espacio), después por palabras (espacios) y finalmente por caracteres individuales si es necesario.
from langchain_text_splitters import RecursiveCharacterTextSplitter
# Configuración básica del splitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
length_function=len,
is_separator_regex=False,
)
Esta jerarquía de separadores garantiza que el texto se divida de la manera más natural posible. Si un párrafo completo cabe dentro del tamaño de chunk especificado, se mantendrá intacto.
Separadores por defecto
El splitter utiliza una lista predefinida de separadores optimizada para texto general:
# Los separadores por defecto (en orden de prioridad)
default_separators = [
"\n\n", # Párrafos
"\n", # Líneas
" ", # Palabras
"", # Caracteres individuales
]
Ejemplo práctico con texto real
Veamos cómo funciona el splitter con un documento de ejemplo:
from langchain_text_splitters import RecursiveCharacterTextSplitter
documento = """
La inteligencia artificial ha revolucionado múltiples sectores en las últimas décadas.
Sus aplicaciones van desde el reconocimiento de voz hasta la conducción autónoma.
En el ámbito del procesamiento de lenguaje natural, los modelos de transformers han
marcado un antes y un después. Estos modelos utilizan mecanismos de atención que
permiten procesar secuencias de texto de manera más eficiente.
Los sistemas RAG (Retrieval-Augmented Generation) combinan la recuperación de
información con la generación de texto. Esta aproximación permite a los modelos
acceder a conocimiento actualizado sin necesidad de reentrenamiento.
"""
splitter = RecursiveCharacterTextSplitter(
chunk_size=300,
chunk_overlap=50
)
chunks = splitter.split_text(documento)
for i, chunk in enumerate(chunks):
print(f"Chunk {i + 1}:")
print(chunk)
print(f"Longitud: {len(chunk)} caracteres")
print("-" * 50)
Trabajando con objetos Document
En aplicaciones RAG reales, normalmente trabajarás con objetos Document que incluyen metadatos además del contenido textual:
from langchain_core.documents import Document
# Crear documentos con metadatos
documentos = [
Document(
page_content="Contenido del primer documento sobre IA...",
metadata={"fuente": "articulo_ia.pdf", "pagina": 1}
),
Document(
page_content="Contenido del segundo documento sobre ML...",
metadata={"fuente": "libro_ml.pdf", "pagina": 15}
)
]
# El splitter preserva los metadatos en cada chunk
chunks_con_metadatos = splitter.split_documents(documentos)
for chunk in chunks_con_metadatos:
print(f"Contenido: {chunk.page_content[:100]}...")
print(f"Metadatos: {chunk.metadata}")
chunk_size y chunk_overlap
Los parámetros chunk_size y chunk_overlap son fundamentales para controlar cómo se divide el texto y determinar la calidad del retrieval en sistemas RAG.
Entendiendo chunk_size
El chunk_size define el tamaño máximo en caracteres que puede tener cada fragmento de texto. Este parámetro actúa como un límite superior:
from langchain_text_splitters import RecursiveCharacterTextSplitter
texto_ejemplo = """
Los sistemas de recomendación utilizan algoritmos de machine learning para predecir
las preferencias de los usuarios. Estos sistemas analizan patrones de comportamiento
histórico para sugerir productos, contenido o servicios relevantes.
Existen principalmente tres tipos de sistemas de recomendación: colaborativos,
basados en contenido e híbridos. Los sistemas colaborativos se basan en las
similitudes entre usuarios.
"""
# Chunk pequeño (200 caracteres)
splitter_pequeño = RecursiveCharacterTextSplitter(
chunk_size=200,
chunk_overlap=0
)
chunks_pequeños = splitter_pequeño.split_text(texto_ejemplo)
print(f"Chunks pequeños generados: {len(chunks_pequeños)}")
Comprendiendo chunk_overlap
El chunk_overlap especifica cuántos caracteres se solapan entre chunks consecutivos. Este solapamiento es crucial para mantener la continuidad del contexto:
# Ejemplo sin solapamiento
sin_overlap = RecursiveCharacterTextSplitter(
chunk_size=400,
chunk_overlap=0
)
# Ejemplo con solapamiento
con_overlap = RecursiveCharacterTextSplitter(
chunk_size=400,
chunk_overlap=100
)
chunks_sin = sin_overlap.split_text(texto_ejemplo)
chunks_con = con_overlap.split_text(texto_ejemplo)
print(f"Sin overlap: {len(chunks_sin)} chunks")
print(f"Con overlap: {len(chunks_con)} chunks")
Calculando el overlap óptimo
Una regla práctica es establecer el overlap entre el 10% y 20% del chunk_size:
def calcular_overlap_recomendado(chunk_size):
"""Calcula el overlap recomendado basado en el tamaño del chunk"""
return int(chunk_size * 0.15) # 15% del tamaño del chunk
# Ejemplos de configuraciones balanceadas
configuraciones = [
{"chunk_size": 500, "chunk_overlap": calcular_overlap_recomendado(500)},
{"chunk_size": 1000, "chunk_overlap": calcular_overlap_recomendado(1000)},
{"chunk_size": 1500, "chunk_overlap": calcular_overlap_recomendado(1500)}
]
for config in configuraciones:
print(f"Chunk size: {config['chunk_size']}, Overlap: {config['chunk_overlap']}")
Configuraciones según el caso de uso
La elección de parámetros debe adaptarse al tipo de aplicación RAG:
Para chatbots de atención al cliente:
customer_service_splitter = RecursiveCharacterTextSplitter(
chunk_size=600,
chunk_overlap=120
)
Para análisis de documentos legales:
legal_splitter = RecursiveCharacterTextSplitter(
chunk_size=1500,
chunk_overlap=300
)
Para búsqueda en bases de conocimiento técnico:
technical_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=150
)
El RecursiveCharacterTextSplitter es especialmente eficaz para mantener la coherencia semántica del texto, ya que su enfoque jerárquico evita cortes abruptos en medio de ideas importantes.
Verificación de la calidad del splitting
Antes de indexar los chunks en un vector store, es recomendable verificar que los fragmentos generados cumplen con las expectativas de tamaño y coherencia:
from langchain_text_splitters import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(chunk_size=800, chunk_overlap=100)
chunks = splitter.split_documents(documentos)
longitudes = [len(chunk.page_content) for chunk in chunks]
print(f"Chunks generados: {len(chunks)}")
print(f"Tamaño medio: {sum(longitudes) / len(longitudes):.0f} caracteres")
print(f"Rango: {min(longitudes)}-{max(longitudes)} caracteres")
Una buena configuración produce chunks cuyo tamaño medio se aproxima al chunk_size configurado, con una variación moderada que refleja los puntos de división naturales del texto.
En la siguiente lección exploraremos técnicas de chunking avanzado para documentos con estructura jerárquica como HTML y Markdown.
Fuentes y referencias
Documentación oficial y recursos externos para profundizar en LangChain
Documentación oficial de LangChain
Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, LangChain es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de LangChain
Explora más contenido relacionado con LangChain y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Usar RecursiveCharacterTextSplitter para dividir documentos, configurar chunk_size y chunk_overlap, entender la estrategia jerárquica de separadores, aplicar splitting a listas de documentos, y optimizar parámetros según el tipo de contenido.
Cursos que incluyen esta lección
Esta lección forma parte de los siguientes cursos estructurados con rutas de aprendizaje