
Crear un sistema RAG completo con LCEL
La construcción de un sistema RAG (Retrieval-Augmented Generation) representa la culminación de todos los conceptos que hemos explorado hasta ahora en este módulo. Un sistema RAG combina la capacidad de recuperar información relevante de una base de conocimientos con la generación de respuestas contextualizadas mediante un modelo de lenguaje.
LCEL (LangChain Expression Language) nos permite crear este pipeline de forma elegante y eficiente, conectando cada componente del sistema mediante el operador |.
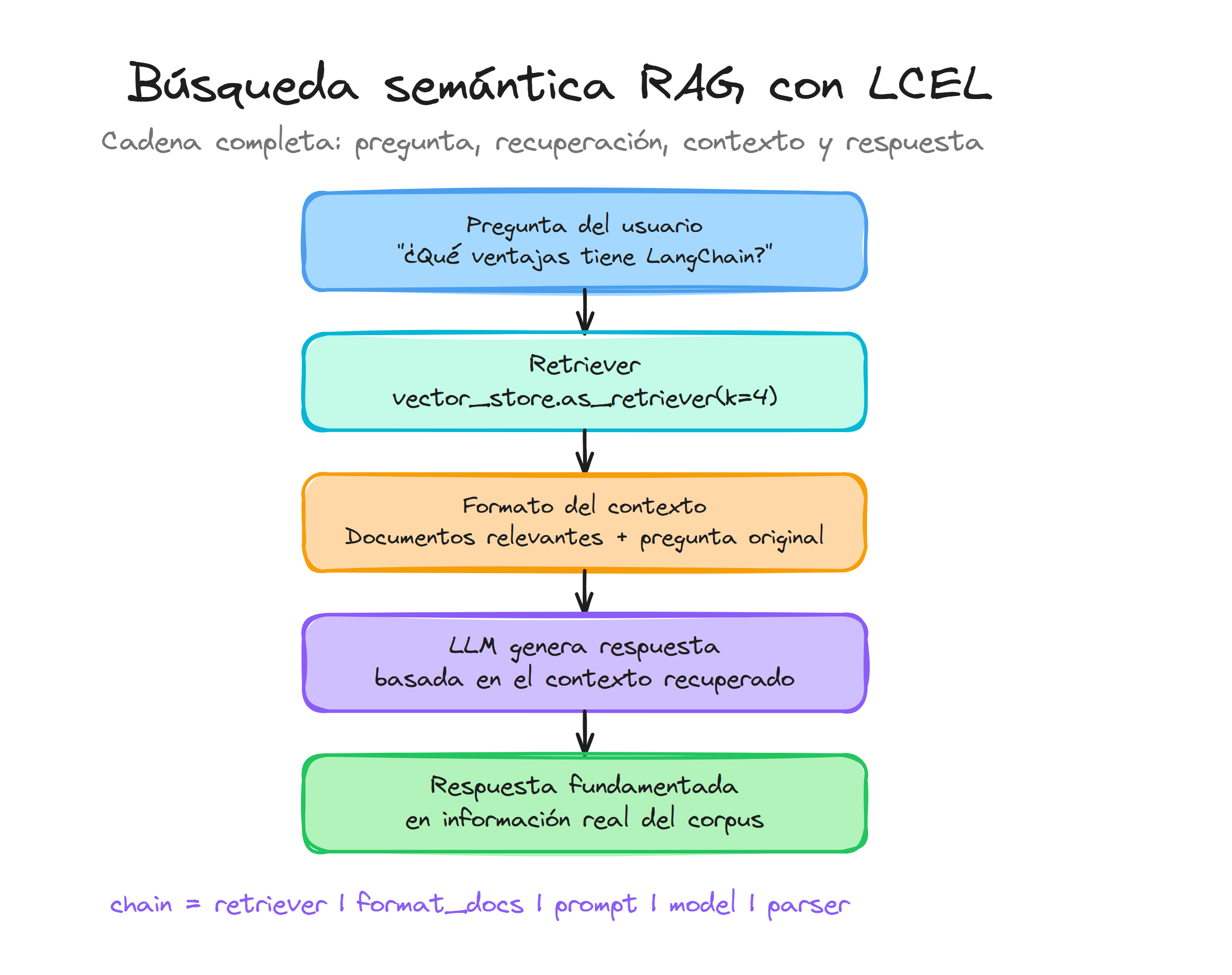
Arquitectura del sistema RAG
Un sistema RAG completo sigue un flujo de datos específico que transforma una pregunta del usuario en una respuesta fundamentada:
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
model = ChatOpenAI(model="gpt-5.4", temperature=0)
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
El pipeline RAG procesa la información siguiendo estos pasos: recibe una consulta del usuario, recupera documentos relevantes del vector store, combina la consulta con el contexto recuperado en un prompt, genera una respuesta usando el modelo de lenguaje y devuelve la respuesta final.
Preparación de la base de conocimientos
Antes de construir la cadena RAG, necesitamos preparar nuestra base de conocimientos con documentos procesados:
loader = TextLoader("documentos/conocimiento_base.txt")
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200
)
chunks = text_splitter.split_documents(documents)
vectorstore = FAISS.from_documents(chunks, embeddings)
Esta preparación establece la fuente de conocimiento que nuestro sistema RAG consultará para responder preguntas.
Construcción del prompt template
El prompt template es crucial para el funcionamiento del sistema RAG:
rag_prompt = ChatPromptTemplate.from_template("""
Eres un asistente útil que responde preguntas basándose únicamente en el contexto proporcionado.
Contexto:
{context}
Pregunta: {question}
Instrucciones:
- Responde únicamente basándote en la información del contexto
- Si la información no está en el contexto, indica que no tienes suficiente información
- Sé preciso y conciso en tu respuesta
Respuesta:
""")
Implementación de la cadena RAG con LCEL
La cadena RAG completa se construye conectando el retriever, el prompt, el modelo y el parser de salida:
retriever = vectorstore.as_retriever(search_kwargs={"k": 3})
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
rag_chain = (
{
"context": retriever | format_docs,
"question": RunnablePassthrough()
}
| rag_prompt
| model
| StrOutputParser()
)
Esta implementación demuestra la elegancia de LCEL para crear pipelines complejos. El diccionario inicial define cómo se procesan los inputs: context se obtiene pasando la pregunta al retriever y formateando los documentos, mientras que question se pasa directamente usando RunnablePassthrough().
Ejecución y uso del sistema
Una vez construida la cadena, el uso del sistema RAG es directo:
pregunta = "¿Cuáles son los beneficios principales del aprendizaje automático?"
respuesta = rag_chain.invoke(pregunta)
print(respuesta)
Sistema RAG con manejo de contexto avanzado
Para casos más complejos, podemos implementar un sistema RAG mejorado que incluye validación:
from langchain_core.runnables import RunnableLambda
def validate_and_format_context(docs):
"""Valida y formatea el contexto recuperado"""
if not docs:
return "No se encontró información relevante en la base de conocimientos."
formatted_context = []
for doc in docs:
if len(doc.page_content.strip()) > 50:
formatted_context.append(doc.page_content)
return "\n\n".join(formatted_context) if formatted_context else "Contexto insuficiente."
enhanced_rag_chain = (
{
"context": retriever | RunnableLambda(validate_and_format_context),
"question": RunnablePassthrough()
}
| rag_prompt
| model
| StrOutputParser()
)
Integración con streaming
LCEL permite implementar respuestas en streaming para mejorar la experiencia del usuario:
for chunk in rag_chain.stream("¿Qué es la inteligencia artificial?"):
print(chunk, end="", flush=True)
El streaming es especialmente útil en aplicaciones web o chatbots donde queremos mostrar la respuesta mientras se genera.
Retrievers: as_retriever() y configuración
Los retrievers actúan como la interfaz estandarizada entre los vector stores y el resto del sistema RAG. El método as_retriever() transforma cualquier vector store en un componente compatible con LCEL.
Configuración básica del retriever
El método as_retriever() acepta varios parámetros de configuración:
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
vectorstore = FAISS.from_documents(chunks, embeddings)
retriever = vectorstore.as_retriever(
search_type="similarity",
search_kwargs={"k": 5}
)
El parámetro k controla la cantidad de documentos que el retriever devuelve para cada consulta.
Tipos de búsqueda disponibles
Los retrievers soportan diferentes estrategias de búsqueda:
Búsqueda por similitud estándar:
similarity_retriever = vectorstore.as_retriever(
search_type="similarity",
search_kwargs={"k": 3}
)
Búsqueda con umbral de similitud:
threshold_retriever = vectorstore.as_retriever(
search_type="similarity_score_threshold",
search_kwargs={
"score_threshold": 0.7,
"k": 10
}
)
Búsqueda MMR (Maximum Marginal Relevance):
mmr_retriever = vectorstore.as_retriever(
search_type="mmr",
search_kwargs={
"k": 5,
"fetch_k": 20,
"lambda_mult": 0.7
}
)
La búsqueda MMR es especialmente útil cuando queremos evitar documentos muy similares entre sí, promoviendo la diversidad en el contexto recuperado.
Configuración avanzada de parámetros
Los retrievers permiten configuraciones específicas según las necesidades del sistema:
production_retriever = vectorstore.as_retriever(
search_type="similarity",
search_kwargs={
"k": 4,
"filter": {"source": "docs"}
}
)
Los filtros de metadatos son especialmente valiosos en sistemas con múltiples fuentes de información.
Integración con diferentes vector stores
Los retrievers mantienen compatibilidad entre diferentes tecnologías de almacenamiento vectorial:
from langchain_chroma import Chroma
chroma_store = Chroma.from_documents(chunks, embeddings)
chroma_retriever = chroma_store.as_retriever(
search_kwargs={"k": 4}
)
rag_chain_chroma = (
{"context": chroma_retriever | format_docs, "question": RunnablePassthrough()}
| rag_prompt
| model
| StrOutputParser()
)
Esta flexibilidad permite cambiar la tecnología de almacenamiento subyacente sin modificar el resto del sistema RAG.
Ejemplo completo de RAG
Veamos un ejemplo completo que integra todos los conceptos del módulo:
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_community.document_loaders import PyPDFLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
# 1. Cargar documentos
loader = PyPDFLoader("manual_producto.pdf")
documents = loader.load()
# 2. Dividir en chunks
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200
)
chunks = text_splitter.split_documents(documents)
# 3. Crear embeddings y vector store
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
vectorstore = FAISS.from_documents(chunks, embeddings)
# 4. Crear retriever
retriever = vectorstore.as_retriever(
search_type="mmr",
search_kwargs={"k": 4, "fetch_k": 10}
)
# 5. Definir prompt
prompt = ChatPromptTemplate.from_template("""
Contexto: {context}
Pregunta: {question}
Responde basándote únicamente en el contexto proporcionado.
""")
# 6. Crear modelo
model = ChatOpenAI(model="gpt-5.4", temperature=0)
# 7. Construir cadena RAG
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| model
| StrOutputParser()
)
# 8. Usar el sistema
respuesta = rag_chain.invoke("¿Cómo configuro el producto?")
print(respuesta)
Este ejemplo demuestra cómo todos los componentes que hemos aprendido en este módulo se combinan para crear un sistema RAG funcional: carga de documentos, chunking, embeddings, vector stores, retrievers y generación con LCEL.
Con esto concluye el módulo de RAG en LangChain. Has aprendido todo el pipeline desde la carga de documentos hasta la generación de respuestas contextualizadas.
Fuentes y referencias
Documentación oficial y recursos externos para profundizar en LangChain
Documentación oficial de LangChain
Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, LangChain es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de LangChain
Explora más contenido relacionado con LangChain y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Construir un pipeline RAG completo con LCEL, conectar retriever, prompt y modelo usando el operador |, crear funciones format_docs para formatear contexto, implementar cadenas RAG con RunnablePassthrough, y entender el flujo completo de indexación, recuperación y generación.
Cursos que incluyen esta lección
Esta lección forma parte de los siguientes cursos estructurados con rutas de aprendizaje