
Runnable invoke
El método invoke es la forma más directa de ejecutar cualquier componente en LangChain. Representa la ejecución síncrona de un Runnable, donde proporcionas una entrada y recibes una salida de manera inmediata. Este método constituye la base sobre la cual se construyen todas las demás formas de ejecución.
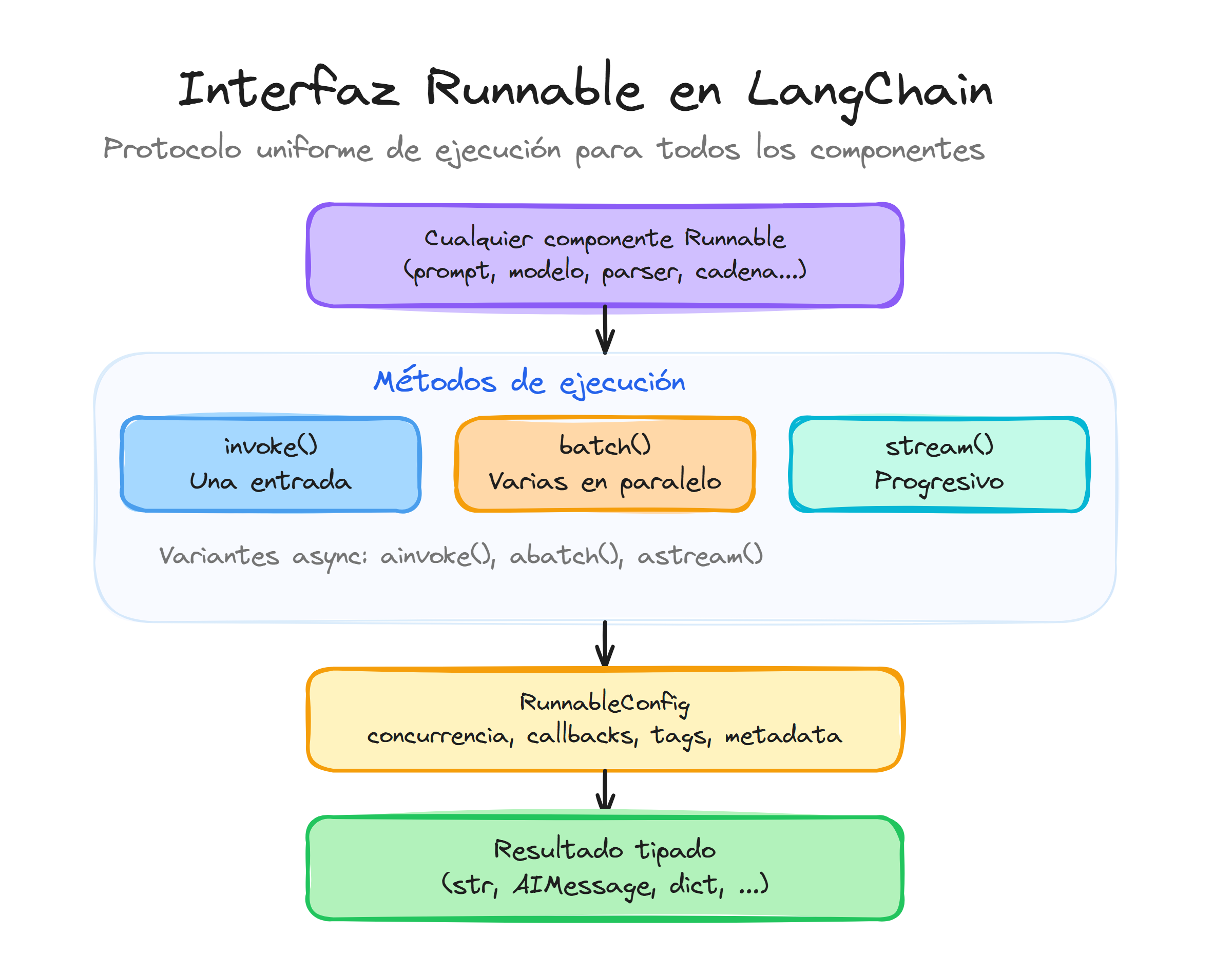
Cuando trabajas con LCEL (LangChain Expression Language), cada componente implementa automáticamente la interfaz Runnable, lo que significa que todos heredan el método invoke junto con sus capacidades de ejecución. Esta uniformidad permite que cualquier cadena, modelo o parser se comporte de manera consistente.
Ejecución básica con invoke
La sintaxis del método invoke es simple: pasas los datos de entrada como argumento y obtienes el resultado procesado:
from langchain.chat_models import init_chat_model
from langchain_core.prompts import ChatPromptTemplate
llm = init_chat_model("gpt-5.4")
# Ejecución directa del modelo
response = llm.invoke("¿Cuál es la capital de Francia?")
print(response.content) # París
El método invoke maneja automáticamente la conversión de tipos cuando es necesario. Si pasas una cadena de texto a un modelo de chat, LangChain la convierte internamente en el formato de mensaje apropiado.
Invoke en cadenas LCEL
Cuando construyes cadenas usando LCEL, el método invoke ejecuta toda la secuencia de componentes de manera secuencial, pasando la salida de cada paso como entrada del siguiente:
from langchain_core.output_parsers import StrOutputParser
prompt = ChatPromptTemplate.from_template(
"Explica el concepto de {tema} en {nivel} palabras máximo"
)
chain = prompt | llm | StrOutputParser()
result = chain.invoke({
"tema": "inteligencia artificial",
"nivel": "50"
})
print(result)
En este ejemplo, invoke ejecuta secuencialmente: el prompt formatea la entrada, el modelo genera la respuesta, y el parser extrae el contenido como string. Todo esto ocurre en una sola llamada al método invoke.
Manejo de configuración en invoke
El método invoke acepta un segundo parámetro opcional llamado config que permite personalizar el comportamiento de la ejecución:
from langchain_core.runnables import RunnableConfig
config = RunnableConfig(
tags=["produccion", "usuario-premium"],
metadata={"session_id": "abc123", "user_id": "user456"}
)
result = chain.invoke(
{"tema": "machine learning", "nivel": "100"},
config=config
)
Esta configuración es útil para trazabilidad y debugging, ya que permite etiquetar y rastrear ejecuciones específicas sin alterar la lógica de la cadena.
Runnable batch
El método batch permite ejecutar múltiples entradas de manera simultánea, optimizando significativamente el rendimiento cuando necesitas procesar varios elementos a la vez. A diferencia de invoke que maneja una sola entrada, batch está diseñado para procesamiento en lotes, aprovechando el paralelismo para reducir el tiempo total de ejecución.
Sintaxis básica de batch
El método batch acepta una lista de entradas y devuelve una lista de resultados en el mismo orden:
from langchain.chat_models import init_chat_model
llm = init_chat_model("gpt-5.4")
preguntas = [
"¿Cuál es la capital de España?",
"¿Cuál es la capital de Italia?",
"¿Cuál es la capital de Alemania?"
]
respuestas = llm.batch(preguntas)
for i, respuesta in enumerate(respuestas):
print(f"Pregunta {i+1}: {respuesta.content}")
El método batch mantiene el orden de las entradas, garantizando que la respuesta en la posición i corresponde exactamente a la entrada en la misma posición.
Batch con cadenas LCEL
Cuando aplicas batch a cadenas construidas con LCEL, cada entrada se procesa a través de toda la cadena de manera independiente, pero de forma paralela:
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_template(
"Resume en {palabras} palabras el tema: {tema}"
)
chain = prompt | llm | StrOutputParser()
entradas = [
{"tema": "inteligencia artificial", "palabras": "30"},
{"tema": "blockchain", "palabras": "25"},
{"tema": "computación cuántica", "palabras": "35"}
]
resultados = chain.batch(entradas)
for resultado in resultados:
print(f"Resumen: {resultado}\n")
Configuración de concurrencia
El método batch permite controlar el nivel de paralelismo mediante el parámetro config:
from langchain_core.runnables import RunnableConfig
config = RunnableConfig(
max_concurrency=3 # Máximo 3 operaciones simultáneas
)
resultados = chain.batch(entradas, config=config)
Esta configuración es crucial cuando trabajas con APIs externas que tienen límites de velocidad o cuando quieres controlar el uso de recursos del sistema.
Runnable stream
El método stream permite procesar respuestas de manera incremental, recibiendo fragmentos de datos a medida que se generan en lugar de esperar a que se complete toda la operación. Esta funcionalidad es especialmente valiosa para aplicaciones interactivas donde quieres mostrar resultados progresivamente.
Funcionamiento básico del streaming
El método stream devuelve un generador que produce fragmentos de la respuesta conforme se van generando:
from langchain.chat_models import init_chat_model
llm = init_chat_model("gpt-5.4")
for chunk in llm.stream("Explica qué es la programación funcional"):
print(chunk.content, end="", flush=True)
Cada chunk contiene una porción de la respuesta completa, permitiendo que tu aplicación muestre el texto conforme se genera, similar a como funciona ChatGPT en su interfaz web.
Stream con cadenas LCEL
Cuando aplicas streaming a cadenas construidas con LCEL, el comportamiento se adapta inteligentemente a cada componente:
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_template(
"Escribe un artículo de {palabras} palabras sobre {tema}"
)
chain = prompt | llm | StrOutputParser()
for chunk in chain.stream({
"tema": "inteligencia artificial",
"palabras": "200"
}):
print(chunk, end="", flush=True)
Streaming asíncrono
Para aplicaciones web donde necesitas respuestas en tiempo real, puedes usar el método astream para streaming asíncrono:
async def stream_response(query: str):
"""Generador asíncrono para streaming de respuestas"""
chain = prompt | llm | StrOutputParser()
async for chunk in chain.astream({"tema": query, "palabras": "100"}):
yield chunk
# Uso en una aplicación web (FastAPI, etc.)
async def handle_user_query(user_input: str):
response_buffer = ""
async for chunk in stream_response(user_input):
response_buffer += chunk
# Aquí enviarías el chunk al frontend
return response_buffer
Stream con manejo de errores
El streaming requiere un manejo de errores más sofisticado, ya que los errores pueden ocurrir en cualquier momento durante la generación:
def safe_stream(query: str):
"""Streaming con manejo robusto de errores"""
try:
for chunk in chain.stream({"tema": query, "palabras": "100"}):
yield chunk
except Exception as e:
yield f"\n[Error durante la generación: {e}]"
return
for chunk in safe_stream("inteligencia artificial"):
print(chunk, end="", flush=True)
El método stream representa la forma más natural de interactuar con modelos de lenguaje en aplicaciones de chat, proporcionando una experiencia de usuario fluida y responsiva.
Fuentes y referencias
Documentación oficial y recursos externos para profundizar en LangChain
Documentación oficial de LangChain
Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, LangChain es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de LangChain
Explora más contenido relacionado con LangChain y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Usar invoke para ejecución síncrona, batch para procesar múltiples entradas, stream para streaming síncrono, ainvoke y abatch para ejecución asíncrona, astream para streaming asíncrono, y entender cómo Runnable proporciona una API uniforme para todos los componentes.
Cursos que incluyen esta lección
Esta lección forma parte de los siguientes cursos estructurados con rutas de aprendizaje