
Reranking
El reranking es como tener un segundo filtro más fino después de la búsqueda inicial con embeddings.
Cuando buscas con embeddings en tu base de datos vectorial, obtienes los documentos más parecidos a tu pregunta. Pero aquí viene el problema: la búsqueda por embeddings es bastante buena para encontrar contenido relacionado, pero no siempre es perfecta para ordenar los resultados por relevancia real.
Es como si fueras a una librería y preguntaras por libros sobre cocina italiana. El dependiente te trae 20 libros relacionados con cocina italiana, pero los ha ordenado un poco al azar. El libro más específico sobre pasta podría estar en la posición 15, mientras que uno general sobre cocina mediterránea está el primero.
El reranking entra aquí como un segundo "experto" que examina esos resultados y los reordena de forma más inteligente. Utiliza modelos más sofisticados que analizan:
- La relevancia específica de cada fragmento con respecto a tu pregunta exacta
- La calidad del contenido
- La coherencia contextual
Hay varios tipos de reranking. Los más comunes usan modelos como los de Cohere, que están entrenados específicamente para esta tarea. También puedes usar modelos cross-encoder, que son muy buenos evaluando la relevancia entre pares de textos.
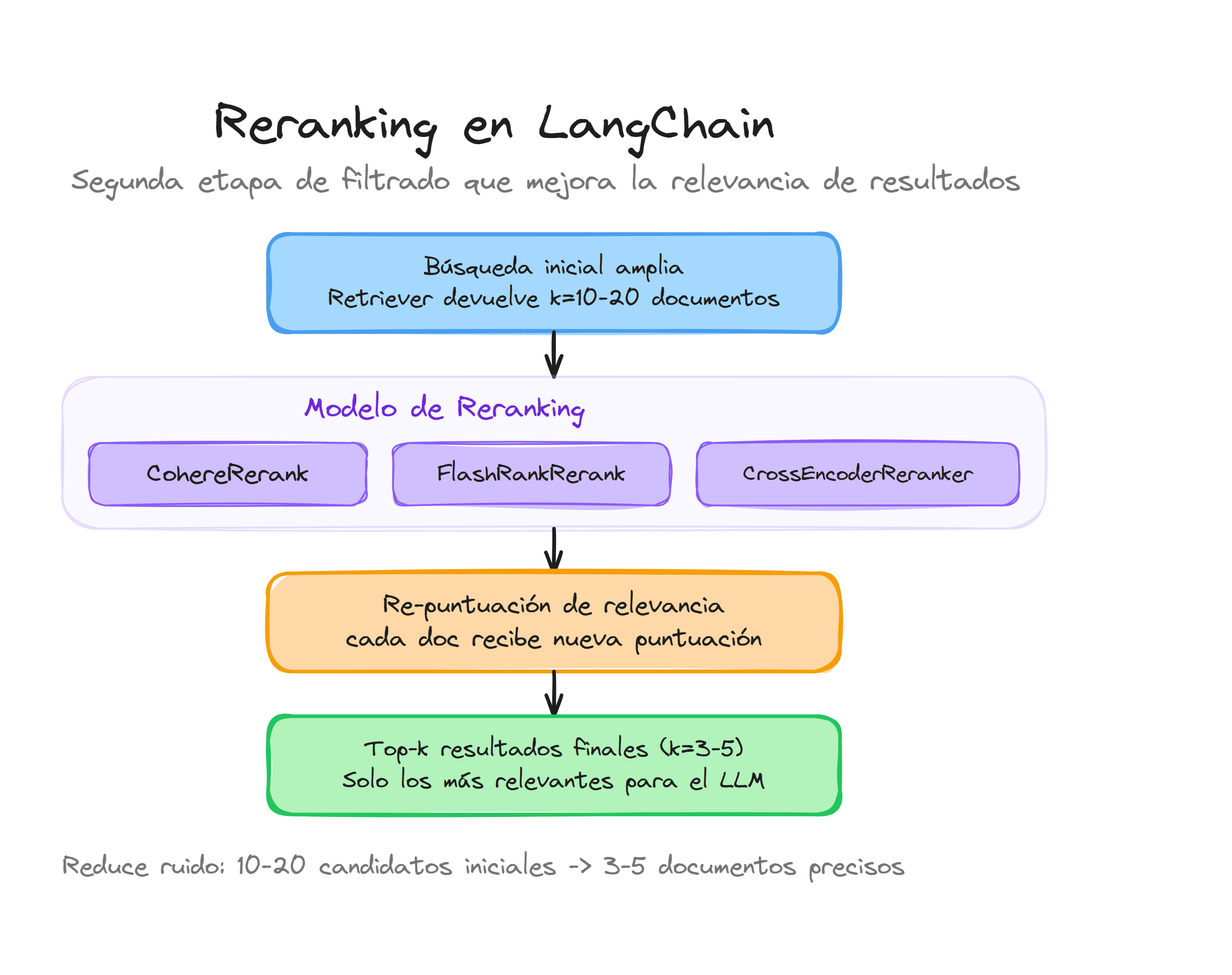
El resultado final es que, de esos 20 documentos que encontraste inicialmente, ahora tienes los 5 o 10 más relevantes perfectamente ordenados. Esto mejora muchísimo la calidad de la respuesta final que genera tu sistema RAG.
ContextualCompressionRetriever para reranking
El ContextualCompressionRetriever en LangChain es un wrapper especializado que permite aplicar técnicas de reranking sobre cualquier retriever base existente.
La arquitectura funciona en dos etapas. Primero, el retriever base ejecuta una búsqueda rápida para obtener un conjunto amplio de documentos candidatos. Posteriormente, el componente de compresión aplica algoritmos de reranking más sofisticados sobre este subconjunto.
Configuración básica del ContextualCompressionRetriever
from langchain.retrievers import ContextualCompressionRetriever
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
from langchain_cohere import CohereRerank
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_texts(
["Documento 1 sobre IA", "Documento 2 sobre ML", "Documento 3 sobre NLP"],
embeddings
)
base_retriever = vectorstore.as_retriever(search_kwargs={"k": 10})
reranker = CohereRerank(
cohere_api_key="tu_api_key",
top_n=3
)
compression_retriever = ContextualCompressionRetriever(
base_compressor=reranker,
base_retriever=base_retriever
)
El parámetro top_n en el reranker determina cuántos documentos finales se devuelven después del proceso de reordenamiento.
Integración con cadenas LCEL
El ContextualCompressionRetriever se integra perfectamente con las cadenas LCEL:
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
llm = ChatOpenAI(model="gpt-5.4")
prompt = ChatPromptTemplate.from_template(
"Basándote en el siguiente contexto, responde la pregunta:\n\n"
"Contexto: {context}\n\n"
"Pregunta: {question}\n\n"
"Respuesta:"
)
rag_chain = (
{
"context": compression_retriever | (lambda docs: "\n\n".join([doc.page_content for doc in docs])),
"question": lambda x: x["question"]
}
| prompt
| llm
| StrOutputParser()
)
result = rag_chain.invoke({"question": "¿Qué es el machine learning?"})
Cohere Rerank vs FlashRank vs CrossEncoder
La elección del algoritmo de reranking determina tanto la calidad de los resultados como el rendimiento del sistema RAG.
Cohere Rerank: Precisión mediante API externa
Cohere Rerank utiliza modelos especializados entrenados específicamente para tareas de reordenamiento semántico:
from langchain_cohere import CohereRerank
from langchain.retrievers import ContextualCompressionRetriever
cohere_reranker = CohereRerank(
cohere_api_key="tu_cohere_api_key",
top_n=5,
model="rerank-v3.5"
)
cohere_retriever = ContextualCompressionRetriever(
base_compressor=cohere_reranker,
base_retriever=base_retriever
)
query = "¿Cuáles son las ventajas del aprendizaje profundo?"
cohere_results = cohere_retriever.invoke(query)
for i, doc in enumerate(cohere_results):
print(f"Documento {i+1}: {doc.page_content[:100]}...")
Las ventajas de Cohere Rerank incluyen su alta precisión y la ausencia de requisitos de infraestructura local.
FlashRank: Velocidad y eficiencia local
FlashRank representa una alternativa ligera y rápida que ejecuta completamente en local:
from langchain_community.document_compressors import FlashrankRerank
flashrank_reranker = FlashrankRerank(
top_n=5,
model="ms-marco-MiniLM-L-12-v2"
)
flashrank_retriever = ContextualCompressionRetriever(
base_compressor=flashrank_reranker,
base_retriever=base_retriever
)
FlashRank destaca por su velocidad de procesamiento y funcionamiento completamente offline.
CrossEncoder: Flexibilidad con modelos Hugging Face
CrossEncoderReranker proporciona acceso a una amplia variedad de modelos de reranking disponibles en Hugging Face:
from langchain_community.document_compressors import CrossEncoderReranker
bge_reranker = CrossEncoderReranker(
model_name="BAAI/bge-reranker-base",
top_n=5
)
cross_encoder_retriever = ContextualCompressionRetriever(
base_compressor=bge_reranker,
base_retriever=base_retriever
)
Criterios de selección según el caso de uso
La elección del reranker debe basarse en los requisitos específicos del proyecto:
- Para máxima precisión y presupuesto para APIs externas: Cohere Rerank
- Para latencia crítica y evitar dependencias externas: FlashRank
- Para personalización en dominios específicos: CrossEncoderReranker
def select_reranker(use_case: str, latency_priority: bool = False):
"""Selecciona el reranker más adecuado según el caso de uso"""
if latency_priority:
return FlashrankRerank(top_n=5)
elif use_case == "high_precision":
return CohereRerank(
cohere_api_key="tu_api_key",
top_n=5,
model="rerank-v3.5"
)
else:
return CrossEncoderReranker(
model_name="BAAI/bge-reranker-base",
top_n=5
)
selected_reranker = select_reranker("high_precision", latency_priority=False)
Impacto del reranking en la calidad del RAG
El reranking mejora significativamente la calidad de las respuestas generadas por un sistema RAG. Sin reranking, el modelo recibe documentos ordenados por similitud vectorial, que puede no reflejar la relevancia real respecto a la pregunta. Con reranking, los documentos más pertinentes ocupan las primeras posiciones, lo que permite al modelo generar respuestas más precisas y fundamentadas.
Un patrón habitual en producción consiste en recuperar un conjunto amplio de candidatos (por ejemplo, k=20) con el retriever base y reducirlo a un subconjunto más pequeño (por ejemplo, top_n=5) con el reranker. Esta estrategia maximiza el recall en la primera fase y la precisión en la segunda.
Con esto concluye el módulo de RAG. Has aprendido todo el pipeline desde la carga de documentos, pasando por el chunking, embeddings, almacenamiento en bases de datos vectoriales, hasta técnicas avanzadas de reranking para mejorar la relevancia de los resultados.
Fuentes y referencias
Documentación oficial y recursos externos para profundizar en LangChain
Documentación oficial de LangChain
Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, LangChain es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de LangChain
Explora más contenido relacionado con LangChain y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Implementar reranking después de búsqueda vectorial, usar modelos de reranking especializados, entender cómo mejora la precisión sobre embeddings, trabajar con ContextualCompressionRetriever, y optimizar el equilibrio entre recall y precisión.
Cursos que incluyen esta lección
Esta lección forma parte de los siguientes cursos estructurados con rutas de aprendizaje