
RecordManager y SQLRecordManager
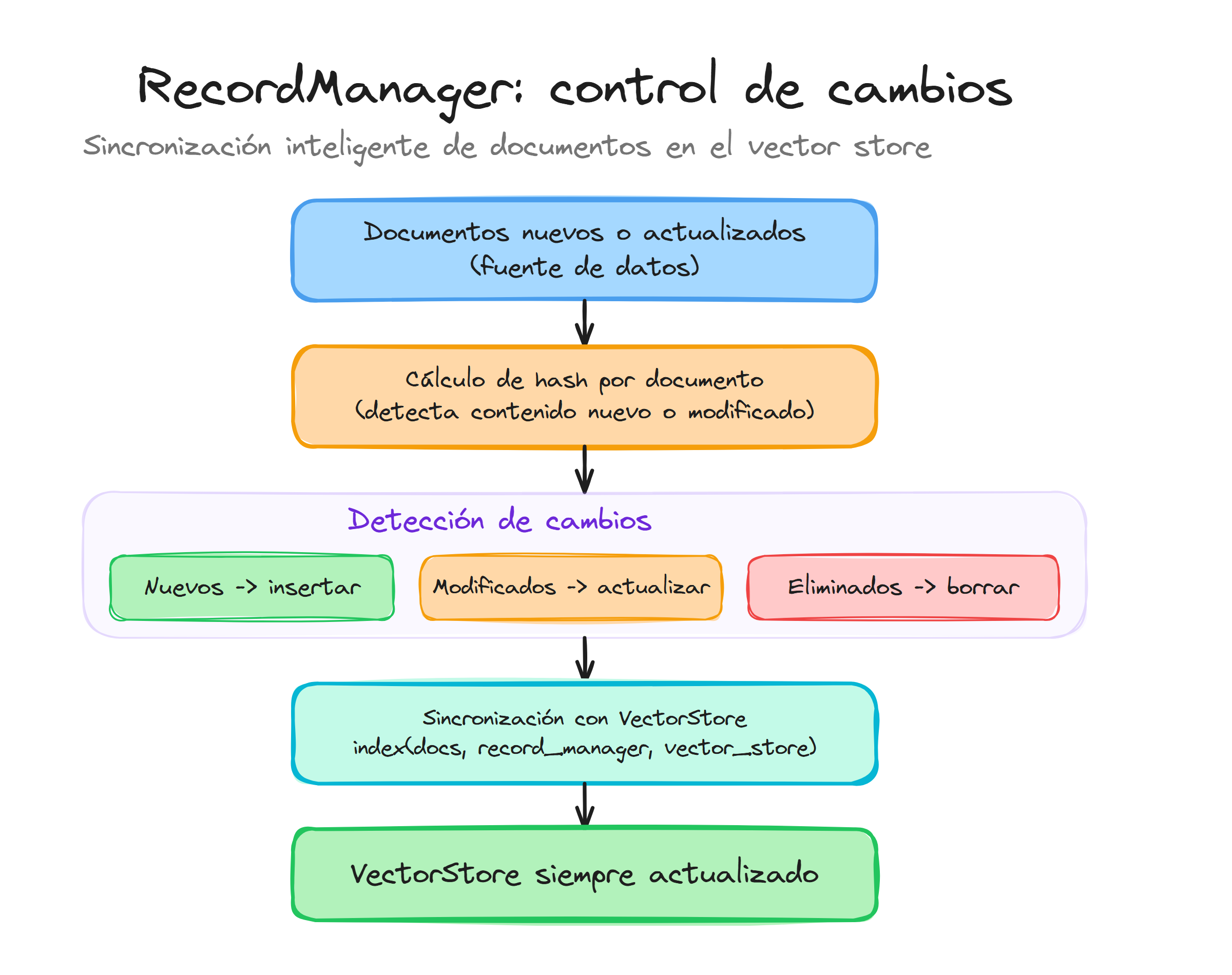
En sistemas RAG de producción, uno de los desafíos más críticos es gestionar eficientemente las actualizaciones del corpus de documentos sin necesidad de reindexar todo el contenido cada vez que hay cambios. LangChain proporciona el RecordManager como solución para este problema, permitiendo un tracking inteligente de documentos y sus modificaciones.
El RecordManager funciona como un sistema de control de versiones para documentos, almacenando metadatos cruciales como hashes de contenido, timestamps de indexación y información de origen. Esta funcionalidad permite detectar automáticamente qué documentos han cambiado, cuáles son nuevos y cuáles han sido eliminados, optimizando significativamente el proceso de actualización del vectorstore.
Configuración básica del SQLRecordManager
La implementación más común utiliza SQLRecordManager, que persiste la información de tracking en una base de datos SQL. Esta aproximación garantiza durabilidad y permite consultas eficientes sobre el historial de documentos:
from langchain.indexes import SQLRecordManager
from langchain_openai import ChatOpenAI
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
# Configuración del RecordManager con SQLite
record_manager = SQLRecordManager(
namespace="documentacion_empresa",
db_url="sqlite:///document_tracking.db"
)
# Inicialización del esquema de base de datos
record_manager.create_schema()
El parámetro namespace es fundamental ya que permite separar diferentes proyectos o colecciones de documentos dentro de la misma base de datos. Esto resulta especialmente útil en entornos empresariales donde múltiples sistemas RAG pueden coexistir.
Estructura interna del tracking
El SQLRecordManager mantiene internamente una tabla que registra información esencial para cada documento procesado. Los campos principales incluyen el identificador único del documento, el hash del contenido para detectar modificaciones, el timestamp de última actualización y metadatos adicionales sobre el origen del documento.
# Ejemplo de configuración para diferentes entornos
import os
# Configuración para desarrollo
dev_record_manager = SQLRecordManager(
namespace="dev_knowledge_base",
db_url="sqlite:///dev_records.db"
)
# Configuración para producción con PostgreSQL
prod_record_manager = SQLRecordManager(
namespace="prod_knowledge_base",
db_url=os.getenv("DATABASE_URL", "postgresql://user:pass@localhost/records")
)
# Inicialización del esquema
dev_record_manager.create_schema()
Integración con vectorstores
El RecordManager se integra seamlessly con cualquier vectorstore compatible, manteniendo sincronización entre los metadatos de tracking y el contenido indexado. Esta integración permite operaciones atómicas que garantizan consistencia entre ambos sistemas:
from langchain_community.document_loaders import DirectoryLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
# Configuración del vectorstore
embeddings = OpenAIEmbeddings()
vectorstore = Chroma(
collection_name="empresa_docs",
embedding_function=embeddings,
persist_directory="./chroma_db"
)
# Preparación de documentos
loader = DirectoryLoader("./documentos", glob="**/*.md")
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200
)
splits = text_splitter.split_documents(documents)
# El RecordManager trackea automáticamente cada chunk
print(f"Preparados {len(splits)} chunks para indexación con tracking")
Gestión de identificadores únicos
Un aspecto crucial del RecordManager es la generación y gestión de identificadores únicos para cada documento. Estos identificadores deben ser determinísticos y estables a lo largo del tiempo, permitiendo reconocer el mismo documento en diferentes ejecuciones:
from langchain_core.documents import Document
# Ejemplo de documentos con IDs estables
documents_with_ids = []
for i, doc in enumerate(splits):
# Generar ID basado en fuente y posición
doc_id = f"{doc.metadata.get('source', 'unknown')}_{i}"
# Crear documento con ID explícito
doc_with_id = Document(
page_content=doc.page_content,
metadata={
**doc.metadata,
"doc_id": doc_id
}
)
documents_with_ids.append(doc_with_id)
Verificación del estado del RecordManager
Antes de realizar operaciones de indexación, es recomendable verificar el estado del RecordManager para entender qué documentos están actualmente trackeados:
# Verificar documentos existentes en el RecordManager
existing_keys = record_manager.list_keys()
print(f"Documentos actualmente trackeados: {len(existing_keys)}")
# Verificar si un documento específico existe
doc_exists = record_manager.exists(["documento_especifico_id"])
print(f"Documento específico existe: {doc_exists}")
# Obtener información detallada de un documento
if existing_keys:
doc_info = record_manager.get_time(existing_keys[0])
print(f"Última actualización: {doc_info}")
Esta funcionalidad de verificación resulta especialmente valiosa en pipelines de actualización automatizados, donde es necesario tomar decisiones basadas en el estado actual del sistema antes de proceder con nuevas indexaciones.
El RecordManager establece así las bases para un sistema de gestión documental robusto y eficiente, preparando el terreno para las operaciones de indexación inteligente que exploraremos en la siguiente sección.
API de indexing con modos full/incremental
La API de indexing de LangChain proporciona un mecanismo sofisticado para gestionar actualizaciones de documentos mediante diferentes estrategias de limpieza. Esta funcionalidad permite optimizar el rendimiento y mantener la coherencia del vectorstore según las necesidades específicas de cada caso de uso.
La función principal index() acepta documentos, un RecordManager configurado, el vectorstore de destino y crucialmente, el parámetro cleanup que determina cómo se gestionan los documentos existentes durante la actualización.
Modo cleanup="none": Sin limpieza automática
El modo "none" representa la estrategia más conservadora, donde únicamente se añaden documentos nuevos sin eliminar contenido existente. Esta aproximación resulta ideal para casos donde se requiere preservar todo el historial o cuando la eliminación de documentos debe gestionarse manualmente:
from langchain.indexes import index
# Indexación sin limpieza automática
result = index(
docs=documents_with_ids,
record_manager=record_manager,
vector_store=vectorstore,
cleanup="none"
)
print(f"Documentos añadidos: {result['num_added']}")
print(f"Documentos actualizados: {result['num_updated']}")
print(f"Documentos eliminados: {result['num_deleted']}") # Siempre será 0
Este modo es particularmente útil en sistemas de auditoría donde cada versión de documento debe mantenerse accesible, o en entornos donde múltiples procesos pueden estar actualizando el mismo vectorstore de forma concurrente.
Modo cleanup="incremental": Limpieza selectiva
La estrategia "incremental" implementa una limpieza inteligente que elimina únicamente documentos obsoletos de las fuentes que están siendo procesadas en el batch actual. Esta funcionalidad permite actualizaciones eficientes manteniendo la integridad de documentos de otras fuentes:
# Simulación de actualización de documentación específica
from langchain_community.document_loaders import TextLoader
# Cargar documentos actualizados de una fuente específica
updated_loader = TextLoader("./docs/manual_usuario_v2.md")
updated_docs = updated_loader.load()
# Procesar con text splitter
updated_splits = text_splitter.split_documents(updated_docs)
# Indexación incremental - solo limpia documentos de esta fuente
result = index(
docs=updated_splits,
record_manager=record_manager,
vector_store=vectorstore,
cleanup="incremental"
)
print(f"Actualización incremental completada:")
print(f"- Nuevos documentos: {result['num_added']}")
print(f"- Documentos modificados: {result['num_updated']}")
print(f"- Documentos obsoletos eliminados: {result['num_deleted']}")
El modo incremental es especialmente valioso en sistemas de documentación empresarial donde diferentes departamentos actualizan sus secciones independientemente, o en casos donde se procesan feeds de noticias que requieren eliminar artículos antiguos sin afectar otras categorías.
Modo cleanup="full": Limpieza completa
La estrategia "full" implementa una sincronización completa donde el vectorstore refleja exactamente el contenido del batch actual. Cualquier documento no presente en el batch será eliminado automáticamente del vectorstore:
# Reconstrucción completa del índice
all_current_docs = []
# Cargar toda la documentación actual
for doc_path in ["./docs/api/", "./docs/guides/", "./docs/tutorials/"]:
loader = DirectoryLoader(doc_path, glob="**/*.md")
docs = loader.load()
all_current_docs.extend(docs)
# Procesar todos los documentos
all_splits = text_splitter.split_documents(all_current_docs)
# Indexación con limpieza completa
result = index(
docs=all_splits,
record_manager=record_manager,
vector_store=vectorstore,
cleanup="full"
)
print(f"Reconstrucción completa:")
print(f"- Estado final: {result['num_added']} documentos activos")
print(f"- Documentos obsoletos eliminados: {result['num_deleted']}")
Casos de uso prácticos por modo
Documentación empresarial dinámica representa un escenario ideal para el modo incremental. Cuando diferentes equipos actualizan sus manuales, cada actualización puede procesarse independientemente:
def actualizar_documentacion_departamento(departamento, archivos_nuevos):
"""Actualiza documentación de un departamento específico"""
# Cargar documentos del departamento
docs_departamento = []
for archivo in archivos_nuevos:
loader = TextLoader(f"./docs/{departamento}/{archivo}")
docs_departamento.extend(loader.load())
# Añadir metadatos de departamento
for doc in docs_departamento:
doc.metadata["departamento"] = departamento
doc.metadata["fuente"] = f"{departamento}_{doc.metadata.get('source', '')}"
splits = text_splitter.split_documents(docs_departamento)
# Actualización incremental por departamento
result = index(
docs=splits,
record_manager=record_manager,
vector_store=vectorstore,
cleanup="incremental"
)
return result
# Actualizar solo documentación de RRHH
resultado_rrhh = actualizar_documentacion_departamento(
"rrhh",
["politicas_2024.md", "procedimientos_nuevos.md"]
)
Corpus de noticias con rotación frecuente se beneficia del modo full para mantener únicamente contenido relevante:
def actualizar_noticias_diarias():
"""Mantiene solo noticias de los últimos 7 días"""
from datetime import datetime, timedelta
fecha_limite = datetime.now() - timedelta(days=7)
# Cargar solo noticias recientes
noticias_recientes = []
loader = DirectoryLoader("./noticias", glob="**/*.json")
for doc in loader.load():
fecha_doc = datetime.fromisoformat(doc.metadata.get("fecha"))
if fecha_doc >= fecha_limite:
noticias_recientes.append(doc)
splits = text_splitter.split_documents(noticias_recientes)
# Limpieza completa - solo noticias recientes permanecen
return index(
docs=splits,
record_manager=record_manager,
vector_store=vectorstore,
cleanup="full"
)
Monitorización y logging de operaciones
Para sistemas en producción, es crucial implementar logging detallado de las operaciones de indexación para facilitar debugging y monitorización:
import logging
from datetime import datetime
# Configurar logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
def indexar_con_logging(docs, cleanup_mode, descripcion=""):
"""Wrapper para indexación con logging detallado"""
inicio = datetime.now()
logger.info(f"Iniciando indexación {descripcion} - Modo: {cleanup_mode}")
logger.info(f"Documentos a procesar: {len(docs)}")
try:
result = index(
docs=docs,
record_manager=record_manager,
vector_store=vectorstore,
cleanup=cleanup_mode
)
duracion = datetime.now() - inicio
logger.info(f"Indexación completada en {duracion.total_seconds():.2f}s")
logger.info(f"Resultados: +{result['num_added']} ~{result['num_updated']} -{result['num_deleted']}")
return result
except Exception as e:
logger.error(f"Error durante indexación: {str(e)}")
raise
# Uso con logging
resultado = indexar_con_logging(
docs=updated_splits,
cleanup_mode="incremental",
descripcion="actualización manual usuario"
)
La selección del modo de cleanup apropiado depende fundamentalmente de los patrones de actualización de datos y los requisitos de consistencia del sistema. El modo incremental ofrece el mejor balance entre eficiencia y flexibilidad para la mayoría de casos de uso empresariales, mientras que el modo full garantiza consistencia absoluta a costa de mayor procesamiento.
Fuentes y referencias
Documentación oficial y recursos externos para profundizar en LangChain
Documentación oficial de LangChain
Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, LangChain es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de LangChain
Explora más contenido relacionado con LangChain y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Usar SQLRecordManager para tracking de documentos, detectar documentos nuevos, modificados y eliminados automáticamente, optimizar procesos de actualización del vectorstore, trabajar con hashes y timestamps, y entender cómo RecordManager actúa como sistema de control de versiones para documentos.