
Clustering recursivo de documentos
El clustering recursivo constituye el núcleo fundamental de RAPTOR, permitiendo organizar documentos en estructuras jerárquicas que capturan tanto información específica como patrones temáticos generales. Este proceso transforma una colección plana de documentos en un árbol de abstracciones mediante agrupaciones sucesivas basadas en similaridad semántica.
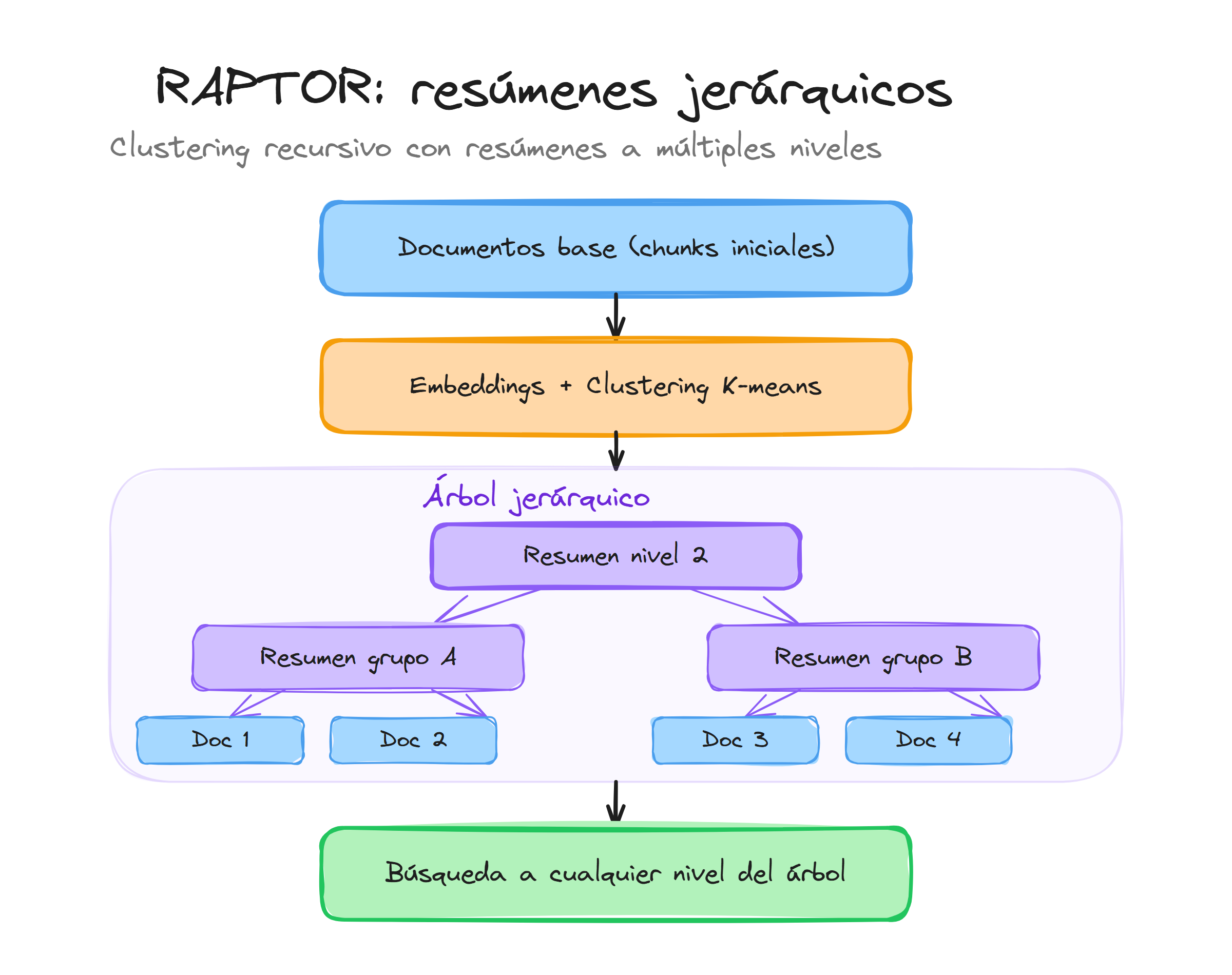
Fundamentos del clustering en RAPTOR
El algoritmo comienza embebiendo todos los documentos de entrada utilizando un modelo de embeddings. Estos vectores de alta dimensionalidad capturan el significado semántico de cada documento, permitiendo medir la similaridad entre contenidos aparentemente diferentes pero conceptualmente relacionados.
from langchain_openai import OpenAIEmbeddings
from langchain_core.documents import Document
from sklearn.cluster import KMeans
import numpy as np
# Configuración del modelo de embeddings
embeddings_model = OpenAIEmbeddings(
model="text-embedding-3-large"
)
# Documentos de ejemplo
documents = [
Document(page_content="Python es un lenguaje de programación interpretado"),
Document(page_content="JavaScript permite crear aplicaciones web interactivas"),
Document(page_content="Los algoritmos de machine learning requieren datos de entrenamiento"),
Document(page_content="Las redes neuronales son fundamentales en deep learning"),
Document(page_content="React es una biblioteca para construir interfaces de usuario"),
Document(page_content="Vue.js facilita el desarrollo de aplicaciones frontend")
]
# Generar embeddings para todos los documentos
doc_embeddings = embeddings_model.embed_documents([doc.page_content for doc in documents])
Algoritmos de clustering aplicados
RAPTOR utiliza principalmente K-means y Gaussian Mixture Models (GMM) para el agrupamiento. K-means ofrece simplicidad y eficiencia computacional, mientras que GMM proporciona mayor flexibilidad al permitir clusters con formas no esféricas y asignaciones probabilísticas.
from sklearn.mixture import GaussianMixture
from sklearn.metrics import silhouette_score
def optimal_clustering(embeddings, max_clusters=10):
"""
Determina el número óptimo de clusters usando silhouette score
"""
best_score = -1
best_n_clusters = 2
for n_clusters in range(2, min(max_clusters + 1, len(embeddings))):
# Probar K-means
kmeans = KMeans(n_clusters=n_clusters, random_state=42)
cluster_labels = kmeans.fit_predict(embeddings)
# Calcular silhouette score
score = silhouette_score(embeddings, cluster_labels)
if score > best_score:
best_score = score
best_n_clusters = n_clusters
return best_n_clusters, best_score
# Encontrar número óptimo de clusters
optimal_k, score = optimal_clustering(doc_embeddings)
print(f"Número óptimo de clusters: {optimal_k} (score: {score:.3f})")
Implementación del clustering recursivo
El proceso recursivo se ejecuta nivel por nivel, donde cada iteración toma los documentos o resúmenes del nivel anterior, los agrupa, y genera nuevos resúmenes que alimentan el siguiente nivel. Este enfoque crea una jerarquía natural donde los niveles superiores contienen abstracciones más generales.
class RAPTORClusterer:
def __init__(self, embeddings_model, min_cluster_size=2, max_levels=3):
self.embeddings_model = embeddings_model
self.min_cluster_size = min_cluster_size
self.max_levels = max_levels
self.hierarchy = {}
def cluster_documents(self, documents, level=0):
"""
Realiza clustering recursivo de documentos
"""
if level >= self.max_levels or len(documents) < self.min_cluster_size:
return documents
# Generar embeddings para el nivel actual
embeddings = self.embeddings_model.embed_documents(
[doc.page_content for doc in documents]
)
# Determinar número óptimo de clusters
n_clusters = min(len(documents) // 2, 5) # Heurística simple
if n_clusters < 2:
return documents
# Aplicar clustering
clusterer = KMeans(n_clusters=n_clusters, random_state=42)
cluster_labels = clusterer.fit_predict(embeddings)
# Organizar documentos por cluster
clusters = {}
for i, label in enumerate(cluster_labels):
if label not in clusters:
clusters[label] = []
clusters[label].append(documents[i])
# Almacenar información del nivel
self.hierarchy[level] = {
'clusters': clusters,
'centroids': clusterer.cluster_centers_,
'documents': documents
}
return clusters
def get_cluster_statistics(self, level):
"""
Obtiene estadísticas del clustering en un nivel específico
"""
if level not in self.hierarchy:
return None
clusters = self.hierarchy[level]['clusters']
stats = {
'num_clusters': len(clusters),
'cluster_sizes': [len(docs) for docs in clusters.values()],
'total_documents': sum(len(docs) for docs in clusters.values())
}
return stats
Métricas de calidad del clustering
La evaluación del clustering es crucial para garantizar agrupaciones semánticamente coherentes. RAPTOR utiliza métricas como el coeficiente de silueta, inercia intra-cluster y coherencia temática para optimizar los parámetros de agrupamiento.
def evaluate_clustering_quality(embeddings, cluster_labels, documents):
"""
Evalúa la calidad del clustering usando múltiples métricas
"""
# Silhouette score
silhouette_avg = silhouette_score(embeddings, cluster_labels)
# Inercia intra-cluster
kmeans = KMeans(n_clusters=len(set(cluster_labels)), random_state=42)
kmeans.fit(embeddings)
inertia = kmeans.inertia_
# Coherencia semántica por cluster
cluster_coherence = {}
unique_labels = set(cluster_labels)
for label in unique_labels:
cluster_docs = [documents[i] for i, l in enumerate(cluster_labels) if l == label]
cluster_embeddings = [embeddings[i] for i, l in enumerate(cluster_labels) if l == label]
# Calcular similaridad promedio intra-cluster
if len(cluster_embeddings) > 1:
similarities = []
for i in range(len(cluster_embeddings)):
for j in range(i + 1, len(cluster_embeddings)):
sim = np.dot(cluster_embeddings[i], cluster_embeddings[j])
similarities.append(sim)
cluster_coherence[label] = np.mean(similarities) if similarities else 0
else:
cluster_coherence[label] = 1.0
return {
'silhouette_score': silhouette_avg,
'inertia': inertia,
'cluster_coherence': cluster_coherence,
'avg_coherence': np.mean(list(cluster_coherence.values()))
}
# Ejemplo de uso
clusterer = RAPTORClusterer(embeddings_model)
clusters = clusterer.cluster_documents(documents)
# Evaluar calidad
cluster_labels = []
for label, docs in clusters.items():
cluster_labels.extend([label] * len(docs))
quality_metrics = evaluate_clustering_quality(doc_embeddings, cluster_labels, documents)
print(f"Calidad del clustering: {quality_metrics}")
Optimización adaptativa del clustering
El clustering recursivo en RAPTOR se adapta dinámicamente al contenido, ajustando el número de clusters y la profundidad de la jerarquía según la diversidad temática de los documentos. Esta adaptabilidad es esencial para manejar corpus heterogéneos donde algunos temas requieren mayor granularidad que otros.
def adaptive_clustering(documents, embeddings_model, diversity_threshold=0.7):
"""
Implementa clustering adaptativo basado en diversidad temática
"""
embeddings = embeddings_model.embed_documents([doc.page_content for doc in documents])
# Calcular diversidad temática
pairwise_similarities = []
for i in range(len(embeddings)):
for j in range(i + 1, len(embeddings)):
sim = np.dot(embeddings[i], embeddings[j])
pairwise_similarities.append(sim)
avg_similarity = np.mean(pairwise_similarities)
diversity_score = 1 - avg_similarity
# Ajustar parámetros según diversidad
if diversity_score > diversity_threshold:
# Alta diversidad: más clusters, menos niveles
n_clusters = min(len(documents) // 2, 8)
max_levels = 2
else:
# Baja diversidad: menos clusters, más niveles
n_clusters = min(len(documents) // 3, 4)
max_levels = 4
return n_clusters, max_levels, diversity_score
El clustering recursivo establece las bases para la construcción de la jerarquía RAPTOR, donde cada nivel de agrupamiento captura diferentes granularidades de información. Esta estructura permite que el sistema responda eficientemente tanto a consultas específicas que requieren detalles precisos como a preguntas generales que necesitan una visión panorámica del corpus.
Summarización jerárquica con LLMs
La summarización jerárquica representa el segundo componente fundamental de RAPTOR, transformando los clusters de documentos en resúmenes coherentes que preservan la información esencial mientras reducen la dimensionalidad del contenido. Este proceso utiliza modelos de lenguaje para generar abstracciones que mantienen la coherencia semántica a través de múltiples niveles de la jerarquía.
Estrategias de summarización por niveles
El enfoque jerárquico requiere estrategias diferenciadas según el nivel de abstracción. Los resúmenes de primer nivel se centran en consolidar información específica de documentos relacionados, mientras que los niveles superiores deben capturar patrones temáticos más amplios y conexiones conceptuales entre diferentes áreas del conocimiento.
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
class HierarchicalSummarizer:
def __init__(self, model_name="gpt-5.4"):
self.llm = ChatOpenAI(model=model_name, temperature=0.1)
self.output_parser = StrOutputParser()
def create_level_specific_prompt(self, level, cluster_size):
"""
Genera prompts específicos según el nivel jerárquico
"""
if level == 0:
# Primer nivel: consolidación detallada
system_message = """Eres un experto en síntesis de información. Tu tarea es crear un resumen
comprehensivo que consolide la información de múltiples documentos relacionados, preservando
detalles importantes y conexiones conceptuales."""
user_template = """Analiza los siguientes {cluster_size} documentos relacionados y crea un resumen
que capture:
1. Los conceptos principales y su interrelación
2. Detalles técnicos relevantes
3. Ejemplos o casos específicos mencionados
Documentos:
{documents}
Resumen consolidado:"""
elif level == 1:
# Segundo nivel: abstracción temática
system_message = """Eres un analista de contenido especializado en identificar patrones
temáticos. Crea resúmenes que capturen las tendencias y temas generales a partir de
resúmenes más específicos."""
user_template = """A partir de los siguientes {cluster_size} resúmenes temáticos, genera una
síntesis que identifique:
1. Patrones y tendencias comunes
2. Áreas de conocimiento interconectadas
3. Conceptos unificadores
Resúmenes de entrada:
{documents}
Síntesis temática:"""
else:
# Niveles superiores: visión panorámica
system_message = """Eres un estratega de conocimiento que crea visiones panorámicas.
Tu objetivo es sintetizar información de alto nivel que proporcione una comprensión
global del dominio."""
user_template = """Basándote en las siguientes {cluster_size} síntesis de alto nivel,
crea una visión panorámica que incluya:
1. Arquitectura conceptual del dominio
2. Relaciones macro entre áreas de conocimiento
3. Insights estratégicos y direcciones futuras
Síntesis de entrada:
{documents}
Visión panorámica:"""
return ChatPromptTemplate.from_messages([
("system", system_message),
("user", user_template)
])
Implementación de la cadena de summarización
La cadena de summarización utiliza LCEL para crear un pipeline eficiente que procesa clusters de documentos y genera resúmenes contextualizados. Esta implementación maneja automáticamente la adaptación del prompt según el nivel jerárquico y el tamaño del cluster.
def create_summarization_chain(self, level, cluster_size):
"""
Crea una cadena LCEL para summarización jerárquica
"""
prompt = self.create_level_specific_prompt(level, cluster_size)
chain = (
prompt
| self.llm
| self.output_parser
)
return chain
def summarize_cluster(self, documents, level=0):
"""
Genera resumen para un cluster específico
"""
# Preparar contenido de documentos
doc_contents = []
for i, doc in enumerate(documents, 1):
content = f"Documento {i}:\n{doc.page_content}\n"
doc_contents.append(content)
combined_content = "\n".join(doc_contents)
# Crear y ejecutar cadena de summarización
chain = self.create_summarization_chain(level, len(documents))
summary = chain.invoke({
"documents": combined_content,
"cluster_size": len(documents)
})
return summary
Procesamiento recursivo de resúmenes
El procesamiento recursivo transforma progresivamente la información desde documentos específicos hasta abstracciones de alto nivel. Cada iteración toma los resúmenes del nivel anterior como entrada, aplicando técnicas de summarización adaptadas al grado de abstracción requerido.
def process_hierarchical_summarization(self, clustered_hierarchy):
"""
Procesa toda la jerarquía de clusters generando resúmenes por nivel
"""
summarized_hierarchy = {}
for level, clusters in clustered_hierarchy.items():
print(f"Procesando nivel {level} con {len(clusters)} clusters")
level_summaries = {}
for cluster_id, documents in clusters.items():
# Generar resumen para el cluster
summary_text = self.summarize_cluster(documents, level)
# Crear documento de resumen
summary_doc = Document(
page_content=summary_text,
metadata={
'level': level,
'cluster_id': cluster_id,
'source_docs': len(documents),
'summary_type': self._get_summary_type(level)
}
)
level_summaries[cluster_id] = summary_doc
summarized_hierarchy[level] = level_summaries
return summarized_hierarchy
def _get_summary_type(self, level):
"""
Determina el tipo de resumen según el nivel
"""
types = {
0: "consolidation",
1: "thematic_synthesis",
2: "panoramic_overview",
3: "strategic_insight"
}
return types.get(level, "high_level_abstraction")
Control de calidad en resúmenes
La validación de calidad asegura que los resúmenes mantengan coherencia semántica y preserven información crítica. Este proceso incluye verificación de completitud, coherencia interna y alineación con el contenido original.
def validate_summary_quality(self, original_docs, summary, level):
"""
Valida la calidad del resumen generado
"""
validation_prompt = ChatPromptTemplate.from_messages([
("system", """Eres un evaluador de calidad de resúmenes. Analiza si el resumen
cumple con los criterios de calidad para su nivel jerárquico."""),
("user", """Evalúa el siguiente resumen considerando:
1. Completitud: ¿Captura los conceptos principales?
2. Coherencia: ¿Es internamente consistente?
3. Precisión: ¿Refleja fielmente el contenido original?
4. Nivel apropiado: ¿Es adecuado para el nivel {level}?
Documentos originales:
{original_content}
Resumen a evaluar:
{summary}
Proporciona una puntuación del 1-10 y justificación breve:""")
])
validation_chain = validation_prompt | self.llm | self.output_parser
original_content = "\n".join([doc.page_content for doc in original_docs])
evaluation = validation_chain.invoke({
"original_content": original_content,
"summary": summary,
"level": level
})
return evaluation
Optimización de longitud y densidad
La gestión de longitud adapta la extensión de los resúmenes según el nivel jerárquico y la complejidad del contenido. Los niveles inferiores mantienen mayor detalle, mientras que los superiores priorizan la concisión y la visión estratégica.
def adaptive_summary_length(self, documents, level, target_compression=0.3):
"""
Calcula longitud objetivo del resumen según el nivel y contenido
"""
total_chars = sum(len(doc.page_content) for doc in documents)
# Factores de compresión por nivel
compression_factors = {
0: 0.4, # Primer nivel: menos compresión
1: 0.25, # Segundo nivel: compresión moderada
2: 0.15, # Tercer nivel: alta compresión
3: 0.1 # Niveles superiores: máxima compresión
}
compression_factor = compression_factors.get(level, 0.1)
target_length = int(total_chars * compression_factor)
# Ajustar según complejidad del contenido
complexity_bonus = min(len(documents) * 50, 200)
final_target = target_length + complexity_bonus
return final_target
def create_length_controlled_prompt(self, level, cluster_size, target_length):
"""
Crea prompt con control específico de longitud
"""
length_instruction = f"Genera un resumen de aproximadamente {target_length} caracteres"
base_prompt = self.create_level_specific_prompt(level, cluster_size)
# Modificar el template para incluir control de longitud
messages = base_prompt.messages
user_message = messages[1].prompt.template
controlled_template = user_message + f"\n\nIMPORTANTE: {length_instruction}"
return ChatPromptTemplate.from_messages([
messages[0],
("user", controlled_template)
])
Integración con el índice jerárquico
Los resúmenes generados se integran automáticamente en el índice RAPTOR, creando nodos internos que conectan diferentes niveles de abstracción. Esta integración permite consultas eficientes que pueden acceder tanto a información específica como a contexto general.
def build_hierarchical_index(self, summarized_hierarchy, embeddings_model):
"""
Construye índice jerárquico integrando resúmenes y documentos originales
"""
hierarchical_index = {}
for level, summaries in summarized_hierarchy.items():
level_nodes = {}
for cluster_id, summary_doc in summaries.items():
# Generar embedding para el resumen
summary_embedding = embeddings_model.embed_query(summary_doc.page_content)
# Crear nodo del índice
node = {
'document': summary_doc,
'embedding': summary_embedding,
'level': level,
'cluster_id': cluster_id,
'node_type': 'summary',
'children': [],
'parent': None
}
level_nodes[cluster_id] = node
hierarchical_index[level] = level_nodes
# Establecer relaciones padre-hijo
self._establish_hierarchical_relationships(hierarchical_index)
return hierarchical_index
def _establish_hierarchical_relationships(self, index):
"""
Establece relaciones jerárquicas entre nodos
"""
levels = sorted(index.keys())
for i in range(len(levels) - 1):
current_level = levels[i]
next_level = levels[i + 1]
# Conectar nodos de niveles adyacentes
for cluster_id, node in index[current_level].items():
# Encontrar nodo padre en el siguiente nivel
parent_cluster = cluster_id // 2 # Heurística simple
if parent_cluster in index[next_level]:
parent_node = index[next_level][parent_cluster]
node['parent'] = parent_node
parent_node['children'].append(node)
La summarización jerárquica transforma la estructura de clusters en un árbol de conocimiento navegable, donde cada nivel proporciona una perspectiva diferente del mismo corpus. Esta organización permite que RAPTOR responda eficientemente a consultas de diferentes granularidades, desde preguntas específicas que requieren detalles precisos hasta consultas estratégicas que necesitan una comprensión panorámica del dominio.
Fuentes y referencias
Documentación oficial y recursos externos para profundizar en LangChain
Documentación oficial de LangChain
Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, LangChain es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de LangChain
Explora más contenido relacionado con LangChain y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Implementar clustering recursivo con RAPTOR, construir estructuras jerárquicas de documentos, trabajar con árboles de abstracciones, entender cómo captura información específica y patrones generales, y aplicar técnicas avanzadas de organización de documentos.