
Métricas de evaluación: faithfulness, relevancy, recall
La evaluación de sistemas RAG requiere métricas específicas que capturen tanto la calidad del retrieval como la de la generación. A diferencia de las métricas tradicionales de NLP, las métricas RAG deben evaluar la coherencia entre documentos recuperados, preguntas originales y respuestas generadas.
Faithfulness (Fidelidad)
La métrica faithfulness mide si la respuesta generada está fundamentada en el contexto recuperado, evitando alucinaciones o información inventada. Esta métrica es crucial porque un sistema RAG debe basar sus respuestas exclusivamente en los documentos proporcionados.
from ragas.metrics import faithfulness
from datasets import Dataset
# Ejemplo de datos para evaluar faithfulness
test_data = Dataset.from_dict({
"question": ["¿Cuál es la capital de Francia?"],
"answer": ["La capital de Francia es París, una ciudad histórica."],
"contexts": [["Francia es un país europeo. París es la capital de Francia y su ciudad más poblada."]]
})
# La métrica evalúa si "París" y "ciudad histórica" están respaldados por el contexto
score = faithfulness.score(test_data)
print(f"Faithfulness score: {score}")
El algoritmo de faithfulness descompone la respuesta en afirmaciones individuales y verifica cada una contra el contexto proporcionado. Una puntuación alta indica que la respuesta no contiene información no respaldada por los documentos recuperados.
Answer Relevancy (Relevancia de la respuesta)
La métrica answer_relevancy evalúa qué tan bien la respuesta generada aborda la pregunta original. Una respuesta puede ser factualmente correcta pero irrelevante si no responde específicamente lo que se preguntó.
from ragas.metrics import answer_relevancy
# Datos de ejemplo para relevancia
test_data = Dataset.from_dict({
"question": ["¿Cuántos habitantes tiene París?"],
"answer": ["París es la capital de Francia y tiene aproximadamente 2.1 millones de habitantes en la ciudad."],
"contexts": [["París tiene una población de 2.1 millones en la ciudad y 12 millones en el área metropolitana."]]
})
# Evalúa si la respuesta aborda directamente la pregunta sobre población
relevancy_score = answer_relevancy.score(test_data)
print(f"Answer relevancy: {relevancy_score}")
Esta métrica utiliza técnicas de similaridad semántica para comparar la pregunta original con la respuesta generada, penalizando respuestas que divaguen o incluyan información no solicitada.
Context Recall (Recuperación del contexto)
El context recall mide qué proporción de la información necesaria para responder correctamente fue recuperada del corpus de documentos. Esta métrica requiere una ground truth o respuesta de referencia para comparar.
from ragas.metrics import context_recall
# Datos con ground truth para evaluar recall
test_data = Dataset.from_dict({
"question": ["¿Cuáles son los principales museos de París?"],
"contexts": [["El Louvre es el museo más visitado de París. También está el Museo de Orsay."]],
"ground_truth": ["Los principales museos de París incluyen el Louvre, Museo de Orsay, Centro Pompidou y Museo Rodin."]
})
# Evalúa si el contexto recuperado contiene suficiente información
recall_score = context_recall.score(test_data)
print(f"Context recall: {recall_score}")
Un recall bajo indica que el sistema de retrieval no está recuperando documentos suficientemente completos, lo que limitará la calidad de las respuestas independientemente de la capacidad del modelo generativo.
Context Precision (Precisión del contexto)
La métrica context_precision evalúa la relevancia de los documentos recuperados, midiendo qué proporción del contexto es realmente útil para responder la pregunta. Un contexto con alta precisión contiene principalmente información relevante.
from ragas.metrics import context_precision
# Ejemplo con contexto mixto (relevante e irrelevante)
test_data = Dataset.from_dict({
"question": ["¿Cuál es la moneda de Francia?"],
"contexts": [["Francia usa el euro como moneda. París tiene muchos restaurantes. El euro se adoptó en 2002."]],
"ground_truth": ["La moneda de Francia es el euro."]
})
# Evalúa qué porción del contexto es relevante para la pregunta
precision_score = context_precision.score(test_data)
print(f"Context precision: {precision_score}")
Interpretación de las métricas
Estas métricas proporcionan insights complementarios sobre diferentes aspectos del sistema RAG:
- Faithfulness alta + Answer relevancy baja: El sistema genera respuestas basadas en hechos pero no aborda la pregunta específica
- Context recall bajo + Context precision alta: El retrieval es selectivo pero incompleto
- Context precision baja + Faithfulness alta: Se recupera información irrelevante pero el modelo la filtra correctamente
# Evaluación completa con múltiples métricas
from ragas.metrics import faithfulness, answer_relevancy, context_recall, context_precision
metrics = [faithfulness, answer_relevancy, context_recall, context_precision]
# Dataset completo para evaluación integral
evaluation_data = Dataset.from_dict({
"question": ["¿Qué tecnologías usa LangChain para RAG?"],
"answer": ["LangChain utiliza embeddings vectoriales y bases de datos como Chroma para implementar RAG."],
"contexts": [["LangChain soporta múltiples proveedores de embeddings. Chroma es una base de datos vectorial popular."]],
"ground_truth": ["LangChain implementa RAG usando embeddings, bases de datos vectoriales como Chroma, Pinecone y FAISS."]
})
# Análisis multidimensional del rendimiento
results = {}
for metric in metrics:
results[metric.__name__] = metric.score(evaluation_data)
print("Resultados de evaluación:")
for metric_name, score in results.items():
print(f"{metric_name}: {score:.3f}")
La combinación de estas métricas permite identificar puntos débiles específicos en el pipeline RAG y guiar optimizaciones targeted, desde ajustar parámetros de retrieval hasta modificar prompts de generación.
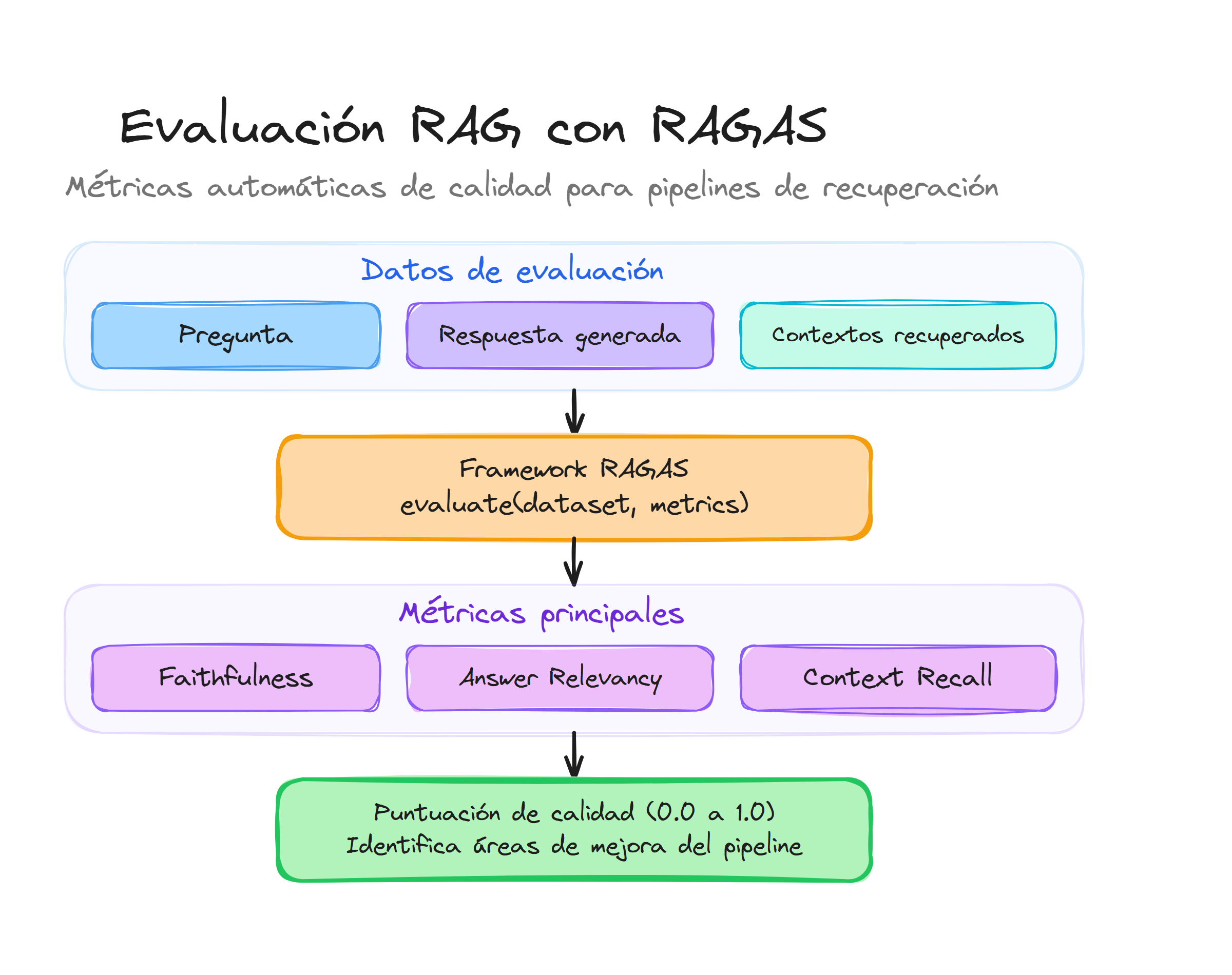
RAGAS framework para assessment automático
El framework RAGAS (Retrieval Augmented Generation Assessment) automatiza la evaluación de sistemas RAG mediante métricas basadas en modelos de lenguaje, eliminando la necesidad de evaluación manual costosa y subjetiva. Este framework se integra directamente con LangChain para proporcionar assessment continuo durante el desarrollo y producción.
Instalación y configuración inicial
RAGAS requiere una instalación específica y configuración de modelos evaluadores que actuarán como jueces automáticos de la calidad del sistema RAG.
# Instalación del framework
# pip install ragas langchain-openai
from ragas import evaluate
from ragas.metrics import faithfulness, answer_relevancy, context_recall, context_precision
from datasets import Dataset
from langchain_openai import ChatOpenAI
import os
# Configuración del modelo evaluador
os.environ["OPENAI_API_KEY"] = "tu-api-key"
# RAGAS utiliza internamente modelos LLM para evaluar
evaluator_llm = ChatOpenAI(model="gpt-5.4", temperature=0)
Estructura de datos para evaluación
RAGAS requiere un formato específico de dataset que contenga todos los componentes necesarios para la evaluación automática. La estructura debe incluir preguntas, respuestas, contextos recuperados y ground truth cuando esté disponible.
# Estructura de datos requerida por RAGAS
evaluation_dataset = Dataset.from_dict({
"question": [
"¿Cómo implementar retrieval semántico en LangChain?",
"¿Qué ventajas tiene usar LCEL sobre chains legacy?",
"¿Cuáles son las mejores prácticas para chunking de documentos?"
],
"answer": [
"Para implementar retrieval semántico en LangChain, se utilizan embeddings vectoriales con bases de datos como Chroma o FAISS.",
"LCEL ofrece mejor composabilidad, streaming nativo y debugging más sencillo comparado con chains legacy.",
"El chunking efectivo requiere considerar el tamaño del chunk, overlap entre chunks y preservar contexto semántico."
],
"contexts": [
["LangChain soporta múltiples proveedores de embeddings. Las bases de datos vectoriales permiten búsqueda semántica eficiente."],
["LCEL es la nueva sintaxis de LangChain que reemplaza chains legacy. Ofrece mejor rendimiento y mantenibilidad."],
["El chunking de documentos afecta directamente la calidad del retrieval. Chunks muy pequeños pierden contexto."]
],
"ground_truth": [
"El retrieval semántico en LangChain se implementa usando embeddings y bases de datos vectoriales como Chroma, FAISS o Pinecone.",
"LCEL proporciona mejor composabilidad, streaming automático, debugging mejorado y sintaxis más limpia que chains legacy.",
"Las mejores prácticas incluyen chunks de 200-500 tokens, overlap del 10-20% y preservar estructura semántica del documento."
]
})
Evaluación automática con múltiples métricas
El proceso de evaluación ejecuta todas las métricas seleccionadas de forma paralela, utilizando modelos LLM como evaluadores automáticos para cada dimensión de calidad.
# Configuración de métricas para evaluación completa
selected_metrics = [
faithfulness, # Fidelidad al contexto
answer_relevancy, # Relevancia de la respuesta
context_recall, # Completitud del retrieval
context_precision # Precisión del contexto
]
# Ejecución de la evaluación automática
evaluation_results = evaluate(
dataset=evaluation_dataset,
metrics=selected_metrics,
llm=evaluator_llm,
embeddings=None # Usa embeddings por defecto
)
# Análisis de resultados
print("Resultados de evaluación RAGAS:")
print(f"Faithfulness: {evaluation_results['faithfulness']:.3f}")
print(f"Answer Relevancy: {evaluation_results['answer_relevancy']:.3f}")
print(f"Context Recall: {evaluation_results['context_recall']:.3f}")
print(f"Context Precision: {evaluation_results['context_precision']:.3f}")
Integración con sistemas RAG de LangChain
RAGAS se integra directamente con pipelines RAG construidos con LCEL, permitiendo evaluación automática de sistemas en producción mediante la captura de datos de inferencia.
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
# Sistema RAG con LCEL para evaluación
embeddings = OpenAIEmbeddings()
vectorstore = Chroma(embedding_function=embeddings)
# Template para generación
rag_prompt = ChatPromptTemplate.from_template("""
Responde la pregunta basándote únicamente en el contexto proporcionado:
Contexto: {context}
Pregunta: {question}
Respuesta:
""")
# Pipeline RAG evaluable
rag_chain = (
{"context": vectorstore.as_retriever(), "question": lambda x: x}
| rag_prompt
| ChatOpenAI(model="gpt-5.4")
| StrOutputParser()
)
# Función para capturar datos de evaluación
def capture_rag_data(questions, rag_system, vectorstore):
"""Captura datos del sistema RAG para evaluación con RAGAS"""
evaluation_data = {
"question": [],
"answer": [],
"contexts": []
}
for question in questions:
# Generar respuesta
answer = rag_system.invoke(question)
# Recuperar contextos utilizados
retrieved_docs = vectorstore.as_retriever().get_relevant_documents(question)
contexts = [doc.page_content for doc in retrieved_docs]
evaluation_data["question"].append(question)
evaluation_data["answer"].append(answer)
evaluation_data["contexts"].append(contexts)
return Dataset.from_dict(evaluation_data)
# Captura automática de datos para evaluación
test_questions = [
"¿Cómo funciona el retrieval en RAG?",
"¿Qué es LCEL en LangChain?"
]
captured_data = capture_rag_data(test_questions, rag_chain, vectorstore)
Evaluación continua y monitoreo
RAGAS permite implementar evaluación continua en sistemas de producción, monitoreando la calidad del RAG a lo largo del tiempo y detectando degradación automáticamente.
import pandas as pd
from datetime import datetime
class RAGEvaluationMonitor:
def __init__(self, metrics, llm, threshold_scores=None):
self.metrics = metrics
self.llm = llm
self.threshold_scores = threshold_scores or {
'faithfulness': 0.8,
'answer_relevancy': 0.7,
'context_recall': 0.6,
'context_precision': 0.7
}
self.evaluation_history = []
def evaluate_batch(self, dataset, batch_id=None):
"""Evalúa un batch de datos y almacena resultados"""
results = evaluate(
dataset=dataset,
metrics=self.metrics,
llm=self.llm
)
# Agregar metadata temporal
evaluation_record = {
'timestamp': datetime.now(),
'batch_id': batch_id,
**results
}
self.evaluation_history.append(evaluation_record)
# Verificar thresholds
alerts = self._check_thresholds(results)
if alerts:
print(f"⚠️ Alertas de calidad detectadas: {alerts}")
return results
def _check_thresholds(self, results):
"""Verifica si las métricas están por debajo de thresholds"""
alerts = []
for metric, threshold in self.threshold_scores.items():
if results.get(metric, 0) < threshold:
alerts.append(f"{metric}: {results[metric]:.3f} < {threshold}")
return alerts
def get_performance_trends(self):
"""Analiza tendencias de rendimiento a lo largo del tiempo"""
if not self.evaluation_history:
return "No hay datos de evaluación disponibles"
df = pd.DataFrame(self.evaluation_history)
# Calcular tendencias
trends = {}
for metric in ['faithfulness', 'answer_relevancy', 'context_recall', 'context_precision']:
if metric in df.columns:
recent_avg = df[metric].tail(5).mean()
overall_avg = df[metric].mean()
trends[metric] = {
'recent_average': recent_avg,
'overall_average': overall_avg,
'trend': 'improving' if recent_avg > overall_avg else 'declining'
}
return trends
# Uso del monitor de evaluación
monitor = RAGEvaluationMonitor(
metrics=[faithfulness, answer_relevancy, context_recall, context_precision],
llm=evaluator_llm
)
# Evaluación de batch actual
current_results = monitor.evaluate_batch(evaluation_dataset, batch_id="batch_001")
# Análisis de tendencias
trends = monitor.get_performance_trends()
print("Tendencias de rendimiento:", trends)
Optimización basada en resultados RAGAS
Los resultados de RAGAS proporcionan insights accionables para optimizar diferentes componentes del sistema RAG de forma iterativa y basada en datos.
def optimize_rag_based_on_ragas(evaluation_results, rag_system):
"""Sugiere optimizaciones basadas en resultados RAGAS"""
optimizations = []
# Análisis de faithfulness
if evaluation_results['faithfulness'] < 0.8:
optimizations.append({
'component': 'generation',
'issue': 'Baja fidelidad al contexto',
'suggestion': 'Ajustar prompt para enfatizar uso exclusivo del contexto',
'priority': 'high'
})
# Análisis de context recall
if evaluation_results['context_recall'] < 0.6:
optimizations.append({
'component': 'retrieval',
'issue': 'Recuperación incompleta',
'suggestion': 'Aumentar número de documentos recuperados o mejorar chunking',
'priority': 'high'
})
# Análisis de context precision
if evaluation_results['context_precision'] < 0.7:
optimizations.append({
'component': 'retrieval',
'issue': 'Contexto irrelevante',
'suggestion': 'Refinar algoritmo de ranking o ajustar embeddings',
'priority': 'medium'
})
# Análisis de answer relevancy
if evaluation_results['answer_relevancy'] < 0.7:
optimizations.append({
'component': 'generation',
'issue': 'Respuestas poco relevantes',
'suggestion': 'Mejorar prompt template o ajustar parámetros del modelo',
'priority': 'medium'
})
return optimizations
# Aplicar análisis de optimización
optimization_suggestions = optimize_rag_based_on_ragas(current_results, rag_chain)
print("Sugerencias de optimización:")
for suggestion in optimization_suggestions:
print(f"• {suggestion['component']}: {suggestion['suggestion']} (Prioridad: {suggestion['priority']})")
El framework RAGAS transforma la evaluación de sistemas RAG de un proceso manual y subjetivo a uno automatizado y reproducible, proporcionando métricas cuantitativas que guían la optimización iterativa y el monitoreo continuo de la calidad en producción.
Fuentes y referencias
Documentación oficial y recursos externos para profundizar en LangChain
Documentación oficial de LangChain
Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, LangChain es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de LangChain
Explora más contenido relacionado con LangChain y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Evaluar sistemas RAG con métricas específicas, medir faithfulness para detectar alucinaciones, calcular relevancy de documentos recuperados, medir recall para cobertura de información, usar RAGAS para evaluación automatizada, y entender cómo las métricas RAG difieren de métricas tradicionales de NLP.