
Qué es RAG y casos de uso
Retrieval-Augmented Generation (RAG) es una técnica que combina la capacidad generativa de los modelos de lenguaje con sistemas de recuperación de información para crear respuestas más precisas y actualizadas. En lugar de depender únicamente del conocimiento preentrenado del modelo, RAG permite acceder a información externa específica durante el proceso de generación.
Esta técnica representa el siguiente paso de mejora de contexto para modelos LLM tras haber aplicado técnicas de prompt engineering.
Limitaciones de los LLMs tradicionales
Los modelos de lenguaje por sí solos presentan varias limitaciones importantes que RAG ayuda a resolver:
- Conocimiento desactualizado: Los modelos se entrenan con datos hasta una fecha específica, por lo que no pueden acceder a información posterior a su entrenamiento.
- Alucinaciones: Los LLMs pueden generar información que parece correcta pero es completamente falsa, especialmente cuando se les pregunta sobre temas específicos o técnicos.
- Falta de transparencia: Es difícil verificar de dónde proviene la información generada por el modelo.
- Limitaciones de contexto: Aunque los modelos modernos tienen ventanas de contexto grandes, no pueden procesar documentos extensos o bases de conocimiento completas de una sola vez.
Cómo funciona RAG conceptualmente
RAG aborda estas limitaciones mediante un proceso de dos etapas. Primero, cuando se recibe una consulta, el sistema busca información relevante en una base de conocimiento externa. Luego, esta información recuperada se proporciona como contexto al modelo de lenguaje para generar una respuesta fundamentada en datos específicos.
Esta aproximación permite que el modelo genere respuestas basadas en información verificable y actualizada, reduciendo significativamente las alucinaciones y mejorando la precisión de las respuestas.
Ventajas de RAG frente al fine-tuning
Aunque el fine-tuning es otra técnica para especializar modelos, RAG ofrece ventajas distintivas:
- Actualización dinámica: La información puede actualizarse sin necesidad de reentrenar el modelo, simplemente modificando la base de conocimiento.
- Menor costo computacional: No requiere el proceso costoso de reentrenamiento que implica el fine-tuning.
- Transparencia: Es posible rastrear exactamente qué información se utilizó para generar cada respuesta.
- Flexibilidad: El mismo modelo puede trabajar con diferentes bases de conocimiento según el contexto o dominio específico.
Casos de uso principales
RAG resulta especialmente valioso en escenarios específicos donde la precisión y actualización de la información son críticas:
- Sistemas de documentación empresarial: Las organizaciones pueden crear asistentes que respondan preguntas sobre políticas internas, procedimientos o documentación técnica.
- Soporte técnico automatizado: Los equipos de soporte pueden implementar sistemas que consulten bases de conocimiento de productos, manuales técnicos y casos resueltos anteriormente.
- Análisis de investigación: Los investigadores pueden crear sistemas que consulten literatura científica actualizada, papers recientes y bases de datos especializadas.
- Asistentes legales: Los profesionales del derecho pueden utilizar RAG para consultar jurisprudencia, normativas actualizadas y documentos legales específicos.
Pipeline básico de RAG
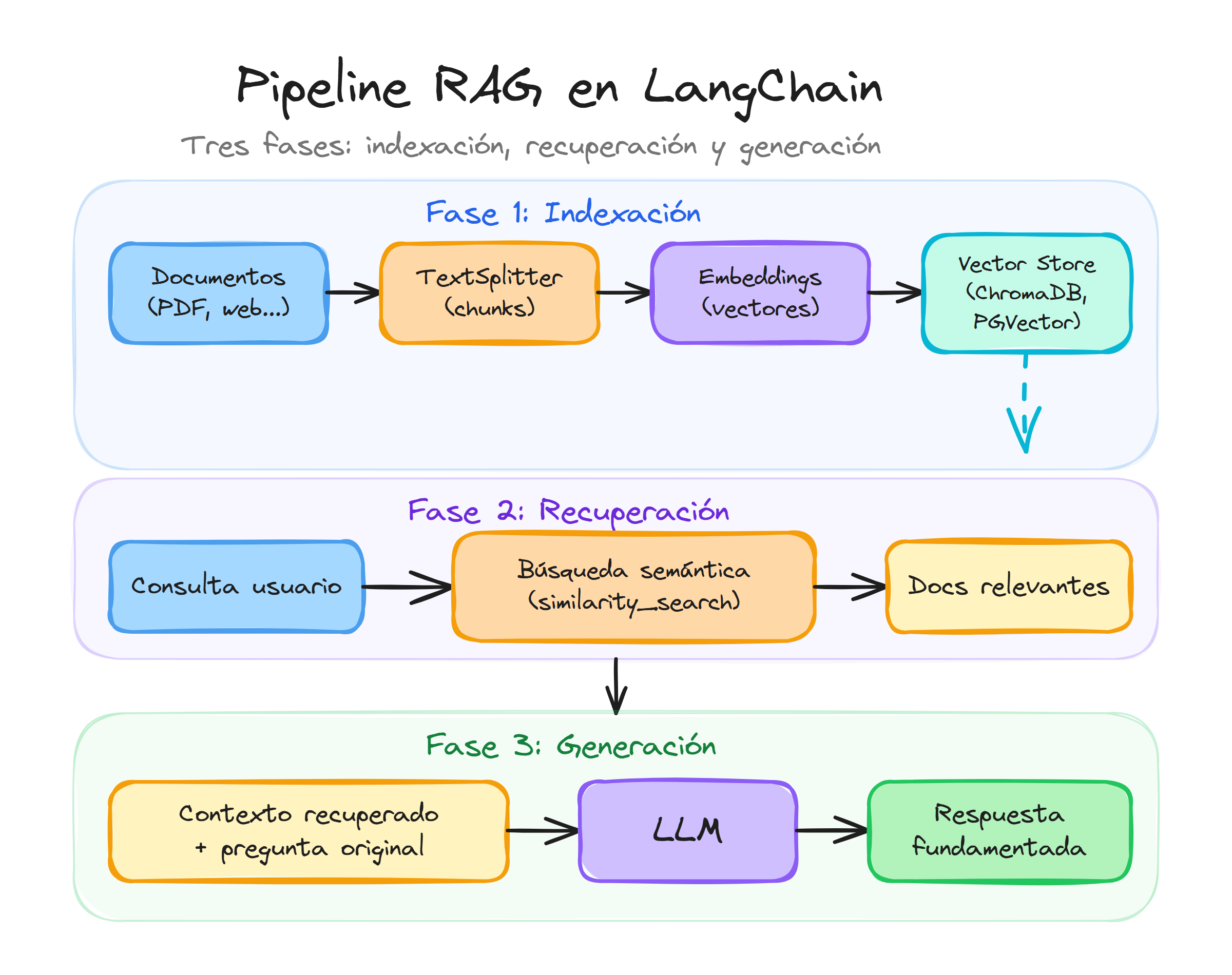
El pipeline de RAG se estructura en tres fases fundamentales que trabajan de forma secuencial para transformar documentos en bruto en respuestas contextualizadas.
Fase 1: Indexación de documentos
La indexación constituye la fase preparatoria donde se procesan y almacenan los documentos que servirán como base de conocimiento. Este proceso comienza con la ingesta de documentos en diversos formatos (PDF, texto plano, HTML, bases de datos) que deben transformarse en un formato uniforme.
Durante esta fase, los documentos se dividen en fragmentos más pequeños llamados chunks. Esta segmentación es crucial porque los modelos de lenguaje tienen limitaciones en la cantidad de texto que pueden procesar simultáneamente. Los chunks deben mantener coherencia semántica, evitando cortar información relacionada de manera abrupta.
Cada fragmento se convierte posteriormente en una representación vectorial mediante modelos de embedding. Estos vectores capturan el significado semántico del texto de forma numérica, permitiendo realizar búsquedas por similitud semántica en lugar de coincidencias exactas de palabras clave.
Los vectores resultantes se almacenan en una base de datos vectorial especializada que permite realizar búsquedas eficientes por similitud.
Fase 2: Recuperación de información relevante
Cuando un usuario realiza una consulta, comienza la fase de recuperación. La pregunta del usuario se convierte primero en un vector utilizando el mismo modelo de embedding empleado durante la indexación.
El sistema realiza una búsqueda por similitud en la base de datos vectorial para identificar los chunks más relevantes para la consulta. Esta búsqueda no se basa en coincidencias exactas de palabras, sino en la proximidad semántica entre la consulta y los fragmentos almacenados.
Los resultados se clasifican por relevancia utilizando métricas de similitud como la distancia coseno. El sistema selecciona los fragmentos con mayor puntuación de similitud, típicamente entre 3 y 10 chunks.
Fase 3: Generación aumentada
La fase de generación combina la consulta original del usuario con la información recuperada para producir una respuesta fundamentada. Los chunks seleccionados se incorporan al prompt del modelo de lenguaje como contexto adicional.
El prompt estructurado típicamente incluye instrucciones claras sobre cómo utilizar la información proporcionada, la consulta original del usuario y los fragmentos recuperados. Esta estructura guía al modelo para generar respuestas que se basen explícitamente en la información proporcionada.
Flujo completo del pipeline
El flujo completo conecta estas tres fases de manera fluida. Los documentos se procesan una vez durante la indexación, creando una base de conocimiento persistente. Para cada consulta, el sistema ejecuta las fases de recuperación y generación en tiempo real.
Este diseño modular permite optimizar cada fase independientemente. La indexación puede mejorarse utilizando diferentes estrategias de chunking o modelos de embedding más avanzados. La recuperación puede refinarse ajustando algoritmos de búsqueda o implementando técnicas de reranking. La generación puede optimizarse mediante ingeniería de prompts o selección de modelos más apropiados.
A lo largo de las siguientes lecciones de este módulo exploraremos cada una de estas fases en detalle.
Fuentes y referencias
Documentación oficial y recursos externos para profundizar en LangChain
Documentación oficial de LangChain
Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, LangChain es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de LangChain
Explora más contenido relacionado con LangChain y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Comprender qué es RAG y sus ventajas frente a modelos tradicionales, entender el pipeline básico de RAG (indexación, recuperación, generación), identificar casos de uso apropiados, y reconocer las limitaciones que RAG resuelve en LLMs.
Cursos que incluyen esta lección
Esta lección forma parte de los siguientes cursos estructurados con rutas de aprendizaje