
PostgreSQL con extensión pgvector
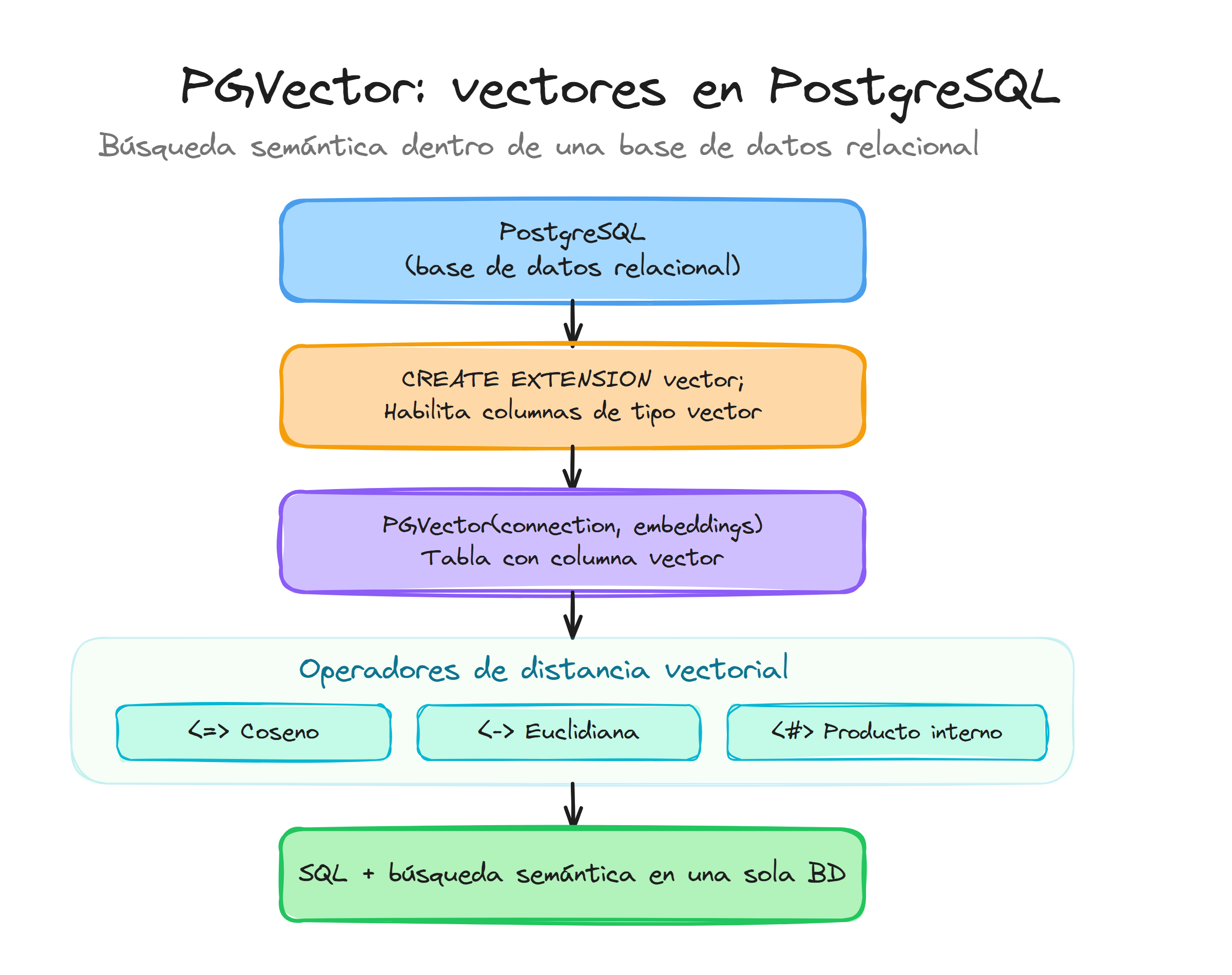
PostgreSQL es una de las bases de datos relacionales más utilizadas en entornos empresariales, y con la extensión pgvector se convierte en una solución híbrida que combina las capacidades tradicionales de SQL con el almacenamiento y búsqueda de vectores.
La extensión pgvector añade un tipo de dato específico para vectores y operadores optimizados para realizar búsquedas de similitud. A diferencia de las soluciones especializadas como ChromaDB, pgvector mantiene todas las garantías ACID de PostgreSQL.
Configuración del entorno con Docker
Para comenzar a trabajar con pgvector, la forma más sencilla es utilizar Docker Compose:
version: '3.8'
services:
postgres:
container_name: pgvector
image: pgvector/pgvector:pg17
ports:
- "5434:5432"
environment:
POSTGRES_USER: postgres
POSTGRES_PASSWORD: postgres
POSTGRES_DB: postgres
volumes:
- postgres_data:/var/lib/postgresql/data
volumes:
postgres_data:
Esta configuración utiliza el puerto 5434 para evitar conflictos con instalaciones locales de PostgreSQL.
Para iniciar el servicio:
docker-compose up -d
Instalación de dependencias Python
Una vez que el contenedor está ejecutándose, instala las dependencias de Python:
pip install langchain-postgres psycopg[binary]
Verificación de la conexión
Antes de trabajar con vectores, verifica que la conexión funciona correctamente:
import psycopg
connection_string = "postgresql://postgres:postgres@localhost:5434/postgres"
with psycopg.connect(connection_string) as conn:
with conn.cursor() as cur:
cur.execute("CREATE EXTENSION IF NOT EXISTS vector;")
cur.execute("SELECT * FROM pg_extension WHERE extname = 'vector';")
result = cur.fetchone()
if result:
print("Extensión pgvector instalada correctamente")
Características empresariales de pgvector
La principal ventaja de pgvector en entornos empresariales radica en su integración nativa con PostgreSQL. Esto significa que puedes combinar búsquedas vectoriales con consultas SQL tradicionales:
# Ejemplo conceptual de consulta híbrida
query = """
SELECT
documento.titulo,
documento.fecha_creacion,
embedding <-> %s as distancia
FROM documentos documento
WHERE documento.categoria = 'tecnico'
AND documento.fecha_creacion > '2025-01-01'
ORDER BY embedding <-> %s
LIMIT 5;
"""
PGVector en LangChain
La integración de PGVector con LangChain se realiza a través del paquete langchain-postgres.
Configuración básica del vectorstore
from langchain_postgres import PGVector
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
vector_store = PGVector(
embeddings=embeddings,
collection_name="documentos_empresa",
connection="postgresql+psycopg://postgres:postgres@localhost:5434/postgres",
)
Operaciones básicas con documentos
Una vez configurado el vectorstore, puedes realizar las operaciones estándar:
from langchain_core.documents import Document
documentos = [
Document(
page_content="PostgreSQL es una base de datos relacional robusta",
metadata={"categoria": "base_datos", "autor": "equipo_dev"}
),
Document(
page_content="LangChain facilita el desarrollo de aplicaciones con LLM",
metadata={"categoria": "framework", "autor": "equipo_ia"}
),
Document(
page_content="Los vectores permiten búsquedas semánticas avanzadas",
metadata={"categoria": "ia", "autor": "equipo_ia"}
)
]
ids = vector_store.add_documents(documentos)
print(f"Documentos añadidos con IDs: {ids}")
Búsquedas por similitud
PGVector en LangChain soporta diferentes métodos de búsqueda:
query = "¿Qué es una base de datos?"
resultados = vector_store.similarity_search(query, k=2)
for doc in resultados:
print(f"Contenido: {doc.page_content}")
print(f"Metadata: {doc.metadata}")
Para obtener también las puntuaciones de similitud:
resultados_con_score = vector_store.similarity_search_with_score(query, k=2)
for doc, score in resultados_con_score:
print(f"Puntuación: {score:.4f}")
print(f"Contenido: {doc.page_content}")
Filtrado por metadatos
Una de las ventajas de PGVector es su capacidad para combinar búsquedas vectoriales con filtros tradicionales:
filtro = {"categoria": "ia"}
resultados_filtrados = vector_store.similarity_search(
query="búsquedas semánticas",
k=3,
filter=filtro
)
print(f"Encontrados {len(resultados_filtrados)} documentos en categoría 'ia'")
Gestión de colecciones
PGVector permite trabajar con múltiples colecciones dentro de la misma base de datos:
vector_store_manuales = PGVector(
embeddings=embeddings,
collection_name="manuales_tecnicos",
connection="postgresql+psycopg://postgres:postgres@localhost:5434/postgres"
)
vector_store_faqs = PGVector(
embeddings=embeddings,
collection_name="preguntas_frecuentes",
connection="postgresql+psycopg://postgres:postgres@localhost:5434/postgres"
)
Integración con LCEL
PGVector se integra perfectamente con LangChain Expression Language (LCEL):
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
chat_model = ChatOpenAI(model="gpt-5.4")
prompt = ChatPromptTemplate.from_template(
"Basándote en el siguiente contexto: {context}\n\nResponde a: {question}"
)
retriever = vector_store.as_retriever(search_kwargs={"k": 3})
chain = (
{"context": retriever, "question": lambda x: x["question"]}
| prompt
| chat_model
| StrOutputParser()
)
respuesta = chain.invoke({"question": "¿Qué ventajas tiene PostgreSQL?"})
print(respuesta)
Esta integración con LangChain permite que PGVector funcione como un componente estándar en aplicaciones RAG, manteniendo la familiaridad de la API mientras se beneficia de las garantías empresariales de PostgreSQL.
Optimización y buenas prácticas
Índices vectoriales para rendimiento
PGVector soporta diferentes tipos de índices que mejoran significativamente el rendimiento de las búsquedas en colecciones grandes:
-- Índice IVFFlat: bueno para colecciones medianas
CREATE INDEX ON langchain_pg_embedding
USING ivfflat (embedding vector_cosine_ops)
WITH (lists = 100);
-- Índice HNSW: mejor rendimiento para colecciones grandes
CREATE INDEX ON langchain_pg_embedding
USING hnsw (embedding vector_cosine_ops)
WITH (m = 16, ef_construction = 64);
El índice HNSW (Hierarchical Navigable Small World) ofrece un rendimiento superior en la mayoría de escenarios, con tiempos de consulta prácticamente constantes independientemente del tamaño de la colección.
Migración de datos y backup
Una de las ventajas más relevantes de PGVector en entornos empresariales es la posibilidad de utilizar las herramientas estándar de PostgreSQL para gestión de datos:
# Backup de la base de datos con vectores
pg_dump -h localhost -p 5434 -U postgres postgres > backup_vectores.sql
# Restaurar desde backup
psql -h localhost -p 5434 -U postgres postgres < backup_vectores.sql
Ventajas frente a soluciones especializadas
PGVector destaca frente a bases de datos vectoriales dedicadas cuando la aplicación ya utiliza PostgreSQL como base de datos principal, ya que permite:
- Consultas híbridas: Combinar filtros SQL tradicionales con búsqueda vectorial en una sola consulta.
- Transacciones ACID: Garantizar la consistencia de los datos vectoriales junto con el resto de la aplicación.
- Infraestructura existente: Reutilizar la infraestructura de PostgreSQL sin añadir un nuevo servicio.
- Herramientas familiares: Aprovechar pgAdmin, psql y el ecosistema de herramientas de PostgreSQL.
En la siguiente lección aprenderemos sobre reranking, una técnica avanzada para mejorar la relevancia de los resultados recuperados.
Fuentes y referencias
Documentación oficial y recursos externos para profundizar en LangChain
Documentación oficial de LangChain
Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, LangChain es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de LangChain
Explora más contenido relacionado con LangChain y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Configurar PostgreSQL con extensión pgvector usando Docker, crear bases de datos vectoriales con PGVector, realizar búsquedas por similitud, trabajar con operadores vectoriales, y entender las ventajas de una solución híbrida SQL-vectorial.
Cursos que incluyen esta lección
Esta lección forma parte de los siguientes cursos estructurados con rutas de aprendizaje