
Output Parsers
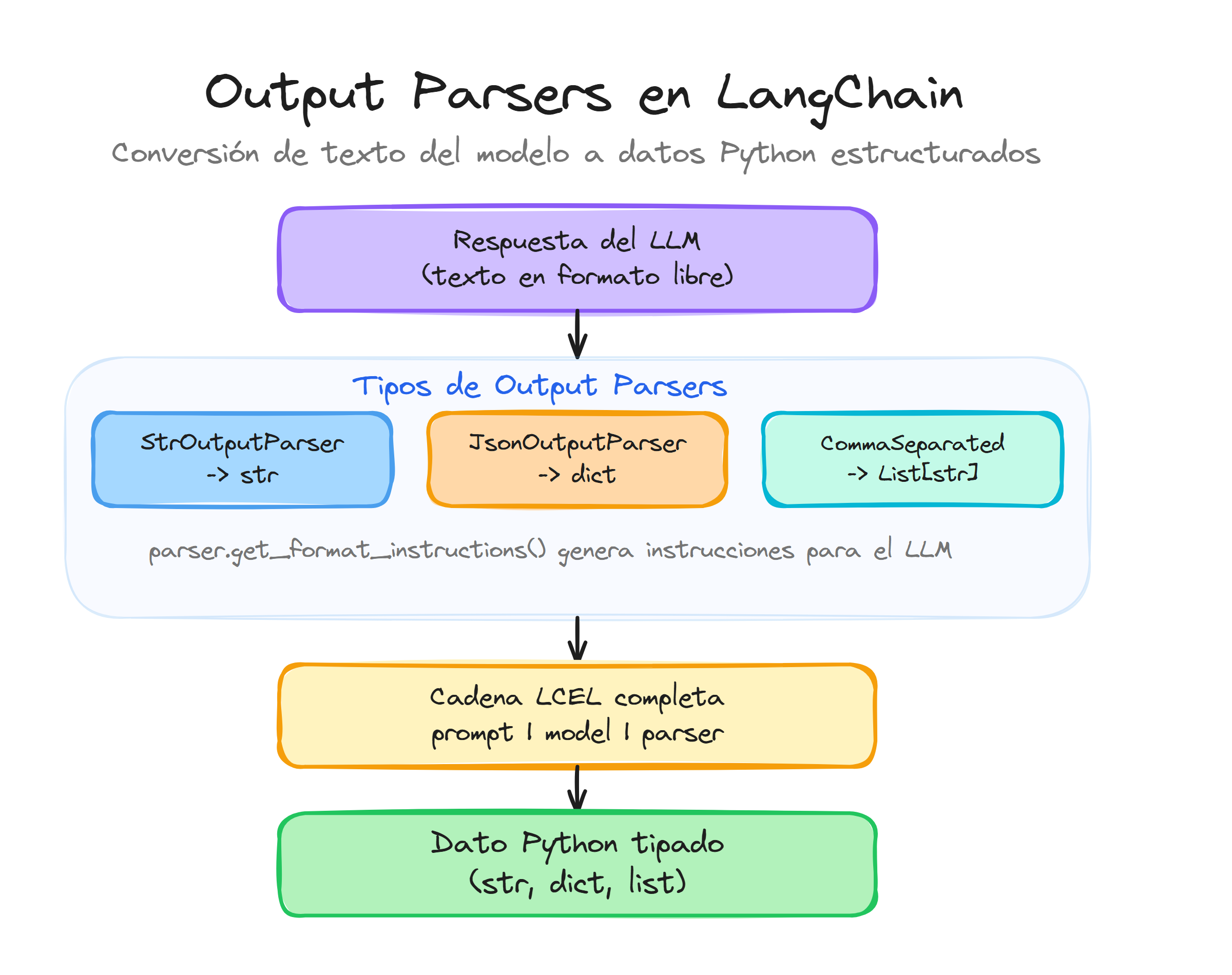
Los output parsers en LangChain son componentes que reciben el texto generado por un modelo y lo convierten en estructuras de datos útiles para tu código, como cadenas limpias, listas o diccionarios. Gracias a estos parsers puedes integrar la salida de un LLM en lógica de negocio, bases de datos o APIs sin tener que escribir parsing manual frágil con búsquedas de texto o expresiones regulares.
Históricamente los output parsers surgieron como una solución temprana al reto de obtener salida estructurada a partir de modelos que solo generaban texto libre. Hoy la mayoría de LLMs modernos soportan salida estructurada de forma nativa (por ejemplo, JSON o esquemas definidos), y en esos casos suele ser mejor aprovechar directamente esa capacidad consultando la documentación específica de tu modelo en lugar de añadir parsers innecesarios.
Incluso en ese contexto, los output parsers siguen siendo relevantes cuando trabajas con modelos sin soporte de salida estructurada, cuando quieres aplicar validaciones adicionales al resultado o cuando necesitas normalizar la salida de distintos modelos bajo un mismo formato. De esta forma se convierten en una capa intermedia que hace de contrato claro entre el modelo y el resto de tu aplicación.
Al decidir si usar un output parser puedes guiarte por estos casos típicos:
- 1. Modelos sin salida estructurada nativa: cuando tu proveedor solo devuelve texto libre y necesitas tipos de datos concretos como
dict, listas o booleanos. - 2. Validación y saneamiento: cuando quieres rechazar salidas que no cumplan un formato mínimo, en lugar de que la aplicación falle más adelante en silencio.
- 3. Normalización entre modelos: cuando combinas varios modelos y quieres que todos devuelvan el mismo tipo de dato, independientemente del proveedor.
- 4. Postprocesado adicional: cuando necesitas aplicar lógica extra sobre el texto (por ejemplo, limpiar, recortar o enriquecer datos) antes de entregarlos a otra parte del sistema.
En el contexto de LCEL, un parser es simplemente un eslabón más de la cadena que recibe texto y devuelve otro tipo de dato. Conceptualmente puedes imaginar el flujo como un diagrama lineal: prompt → modelo → output parser → tu lógica de negocio, donde cada bloque conoce con claridad qué tipo de dato entra y qué tipo sale.
Un patrón de uso muy habitual consiste en encadenar un prompt, un modelo y un output parser en una sola cadena:
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
# Prompt sencillo
prompt = ChatPromptTemplate.from_messages(
[
("human", "Responde brevemente a la pregunta: {pregunta}"),
]
)
# Modelo de chat
model = ChatOpenAI(model="gpt-5.4-mini", temperature=0)
# Parser que extrae solo el contenido como cadena
parser = StrOutputParser()
# Cadena LCEL: prompt -> modelo -> parser
chain = prompt | model | parser
respuesta = chain.invoke({"pregunta": "¿Qué es un output parser en LangChain?"})
print(respuesta)
En este ejemplo el modelo sigue generando texto, pero la cadena siempre produce un str limpio, sin metadatos de chat, lo que simplifica el consumo de la salida en el resto de tu código.
StrOutputParser
StrOutputParser es el parser más sencillo y sirve para transformar la respuesta del modelo en una cadena de texto normal de Python. Cuando llamas a un modelo de chat sueles obtener objetos ricos (por ejemplo, mensajes con rol, contenido y metadatos), mientras que este parser se queda solo con el contenido textual que te interesa.
Este comportamiento convierte a StrOutputParser en una especie de adaptador entre la interfaz orientada a mensajes de los modelos de chat y el mundo de funciones tradicionales que esperan recibir y devolver cadenas. Así reduces ruido y evitas tener que manipular manualmente estructuras internas de LangChain cada vez que usas el modelo.
Algunos usos habituales de StrOutputParser en una aplicación son:
- 1. Simplificar el tipo de salida: cuando solo necesitas texto plano y quieres olvidarte de mensajes estructurados.
- 2. Integrar con librerías externas: cuando pasas la respuesta a herramientas que esperan un
str, como motores de plantillas, visores o sistemas de logging. - 3. Paso previo a otros procesados: cuando posteriormente aplicarás expresiones regulares, análisis de sentimiento u otros parsers hechos a medida sobre la cadena ya limpia.
A partir del patrón mostrado en la sección anterior, puedes seguir usando StrOutputParser con los mismos métodos de la cadena (invoke, batch, stream), sabiendo que siempre trabajarás con cadenas en lugar de con objetos de mensaje más complejos.
JsonOutputParser
JsonOutputParser está pensado para transformar el texto generado por un modelo en un objeto JSON válido (en Python, un dict con listas y tipos primitivos). El modelo sigue produciendo texto, pero se le indica mediante instrucciones claras que debe generar un JSON bien formado, y el parser se encarga de comprobarlo y convertirlo en estructura de datos.
En muchos modelos actuales puedes pedir directamente salida JSON garantizada usando las opciones de salida estructurada del propio modelo (por ejemplo, esquemas o modos JSON), lo que en ocasiones hace innecesario este parser. Aun así, JsonOutputParser es muy útil cuando el modelo que usas no ofrece esa capacidad, cuando quieres tener una capa de validación explícita o cuando prefieres mantener la lógica de formato en tu código en lugar de depender de extensiones específicas del proveedor.
Este parser encaja bien en escenarios como:
- 1. Formularios y entidades: cuando quieres que el modelo devuelva campos bien definidos (por ejemplo,
titulo,prioridad,fecha_limite) que luego guardarás en una base de datos. - 2. Integración con APIs: cuando necesitas construir un cuerpo JSON a partir de lenguaje natural para llamar a otro servicio.
- 3. Extracción de información: cuando el modelo extrae datos concretos de un texto largo y quieres procesarlos con código Python de forma segura.
Un patrón de uso típico consiste en combinar JsonOutputParser con un prompt que incluye las instrucciones de formato generadas por el propio parser:
from langchain_core.output_parsers import JsonOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
# Parser que espera un objeto JSON
parser = JsonOutputParser()
# Prompt con instrucciones de formato inyectadas
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"Devuelve SIEMPRE un objeto JSON con las claves 'titulo' y 'prioridad'. "
"Sigue exactamente estas instrucciones de formato:\n{format_instructions}",
),
("human", "Tarea: {descripcion}"),
]
).partial(format_instructions=parser.get_format_instructions())
model = ChatOpenAI(model="gpt-5.4-mini", temperature=0)
chain = prompt | model | parser
resultado = chain.invoke({"descripcion": "Preparar el informe semanal de ventas"})
print(type(resultado)) # dict
print(resultado["titulo"]) # Título sugerido por el modelo
print(resultado["prioridad"])
En este ejemplo el problema es obtener un objeto estructurado que puedas manipular con normalidad en Python, y la solución pasa por delegar en el modelo la generación del JSON pero dejando en manos del parser la validación y conversión a tipos nativos. Si en un futuro cambias a un modelo con salida estructurada nativa, podrás sustituir el uso de JsonOutputParser por la API de structured output del proveedor manteniendo intacto el resto de tu cadena.
CommaSeparatedListOutputParser
CommaSeparatedListOutputParser resuelve un problema muy frecuente: quieres que el modelo genere una lista de elementos, pero trabajar con una cadena única separada por comas resulta incómodo y propenso a errores. Este parser convierte esa salida en una lista de cadenas de Python (list[str]), lo que facilita recorrer, filtrar o guardar los elementos en otras estructuras de datos.
A nivel de uso, la idea es pedir al modelo que genere los ítems separados por comas siguiendo unas instrucciones claras, y dejar que CommaSeparatedListOutputParser se encargue de dividir y limpiar cada elemento. De nuevo, el modelo devuelve texto y el parser lo adapta a un tipo de dato más útil para tu lógica de negocio.
Algunos escenarios típicos donde este parser resulta práctico son:
- 1. Generación de ideas o bullet points: cuando pides al modelo varias propuestas breves y luego quieres iterar sobre ellas en tu código.
- 2. Etiquetado y categorías: cuando necesitas una lista de etiquetas, categorías o palabras clave a partir de una descripción en lenguaje natural.
- 3. Parametrización rápida: cuando a partir de una frase quieres obtener una lista de parámetros para alimentar otro proceso o herramienta dentro de tu sistema.
El siguiente ejemplo muestra cómo integrar CommaSeparatedListOutputParser en una cadena LCEL:
from langchain_core.output_parsers import CommaSeparatedListOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
parser = CommaSeparatedListOutputParser()
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"Genera una lista de ideas de producto separadas por comas. "
"Sigue exactamente estas instrucciones de formato:\n{format_instructions}",
),
("human", "Tema: {tema}"),
]
).partial(format_instructions=parser.get_format_instructions())
model = ChatOpenAI(model="gpt-5.4-mini", temperature=0)
chain = prompt | model | parser
ideas = chain.invoke({"tema": "mejoras para la página de inicio de la web"})
print(type(ideas)) # list
for idea in ideas:
print("-", idea)
En este caso el resultado ya es una lista de cadenas, sin necesidad de partir la cadena manualmente ni gestionar espacios, lo que simplifica la integración con el resto de la aplicación. El patrón es el mismo que con otros output parsers: el prompt describe el formato deseado, el modelo genera texto acorde a esas reglas y el parser lo convierte en una estructura de datos coherente para tu código.
Fuentes y referencias
Documentación oficial y recursos externos para profundizar en LangChain
Documentación oficial de LangChain
Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, LangChain es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de LangChain
Explora más contenido relacionado con LangChain y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Comprender el propósito de los output parsers, usar StrOutputParser para extraer texto limpio, integrar parsers en cadenas LCEL, aplicar validación y saneamiento de salidas, y normalizar respuestas entre diferentes modelos.
Cursos que incluyen esta lección
Esta lección forma parte de los siguientes cursos estructurados con rutas de aprendizaje