
Qué es Ollama, instalación y uso de modelos
Ollama es una herramienta esencial para la ejecución local de modelos de lenguaje (LLMs). Permite correr modelos como Llama 4, Mistral o Phi directamente en tu ordenador, garantizando privacidad total de los datos y eliminando costes por uso de API.
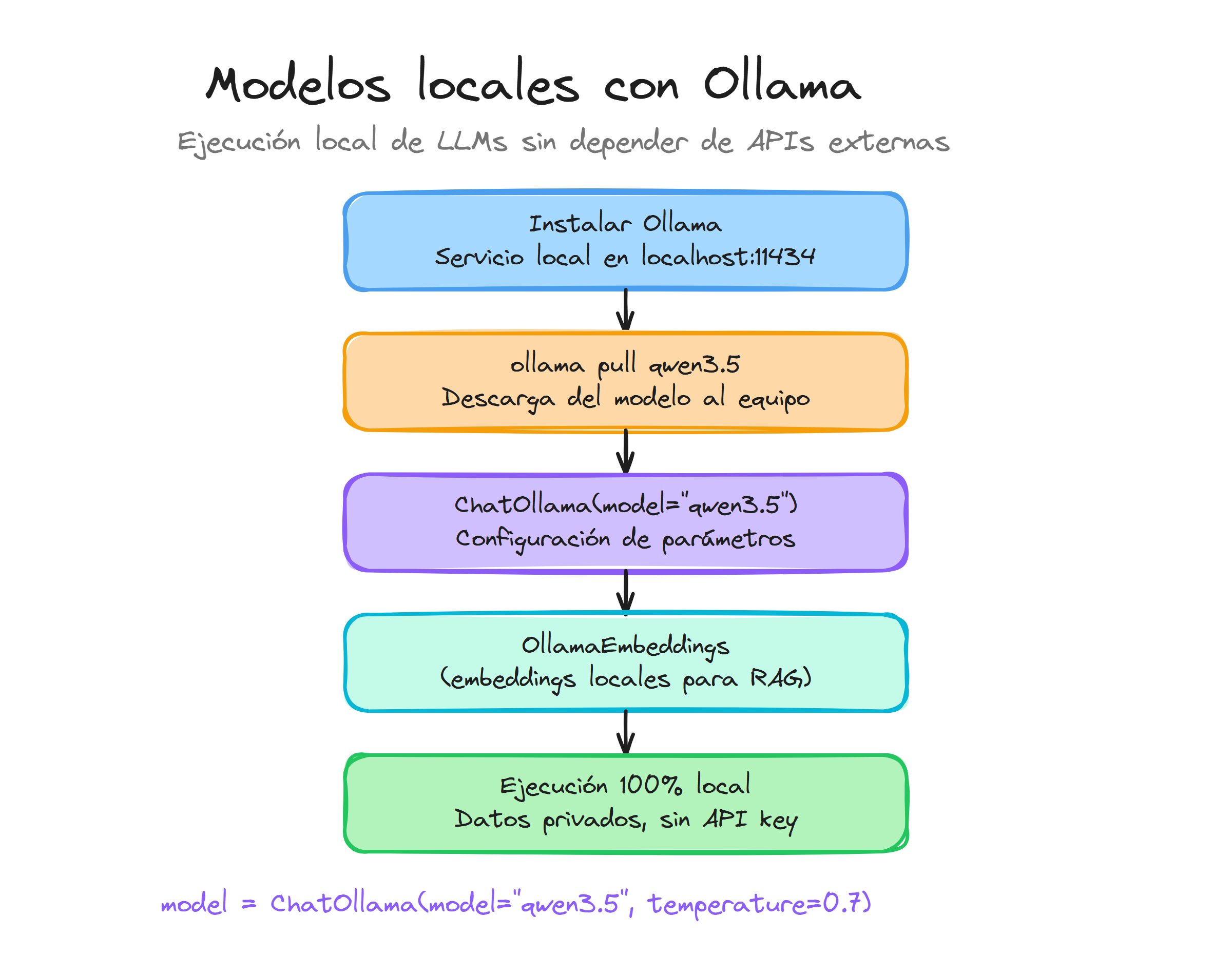
Su diseño simplifica enormemente la gestión de modelos locales, funcionando de manera similar a Docker pero enfocado en IA. Es la solución estándar para desarrollo offline o cuando se maneja información confidencial que no debe salir de la infraestructura local.
Instalación de Ollama
El proceso de instalación es directo y varía ligeramente según el sistema operativo. Puedes descargar el instalador oficial desde ollama.com.
- 1. Instalación:
- macOS/Linux: Generalmente mediante terminal o gestor de paquetes.
- Windows: Ejecutando el instalador
.exeoficial.
Una vez instalado, Ollama funciona como un servicio en segundo plano que expone una API local en el puerto 11434.
- 2. Verificación:
Abre tu terminal y comprueba que el servicio responde correctamente:
ollama --version
Descarga de modelos (Pull)
Ollama no incluye modelos por defecto; debes descargarlos según tus necesidades. El comando pull se encarga de bajar los pesos del modelo a tu máquina.
- 1. Descargar Llama 4:
ollama pull llama4:8b
Este comando descarga la versión de 8 billones de parámetros de Llama 4, un modelo muy eficiente capaz de ejecutarse en la mayoría de portátiles modernos con GPU dedicada.
- 2. Listar modelos disponibles:
Para ver qué modelos tienes ya instalados en tu sistema:
ollama list
Ejecución interactiva
Antes de integrarlo en código, puedes probar el modelo directamente desde la terminal para asegurar su funcionamiento.
ollama run llama4:8b "Explica qué es la recursividad en programación"
Invocar modelos de Ollama en LangChain
LangChain se integra con Ollama a través del paquete langchain-ollama, permitiendo usar tus modelos locales con la misma interfaz que los modelos en la nube de OpenAI o Anthropic.
Instalación del paquete
Necesitas instalar la librería de integración específica:
pip install langchain-ollama
Configuración con ChatOllama
La clase ChatOllama es el componente principal para interactuar con los modelos de chat. Se conecta automáticamente a tu instancia local de Ollama.
- 1. Inicialización básica:
from langchain_ollama import ChatOllama
# Configura el modelo coincidiendo con el nombre del tag en Ollama
llm = ChatOllama(
model="llama4:8b",
temperature=0.7
)
Es crucial que el parámetro model coincida exactamente con el nombre del modelo que descargaste (por ejemplo, llama4:8b).
Invocación del modelo
El uso del modelo local sigue el estándar de LangChain, utilizando el método invoke.
- 1. Invocación simple:
response = llm.invoke("¿Cuáles son los principios SOLID?")
print(response.content)
- 2. Uso con mensajes estructurados:
from langchain_core.messages import HumanMessage, SystemMessage
messages = [
SystemMessage(content="Eres un asistente experto en SQL."),
HumanMessage(content="Escribe una query para obtener los usuarios activos.")
]
response = llm.invoke(messages)
print(response.content)
Parámetros avanzados
Puedes ajustar el comportamiento del modelo local configurando parámetros específicos de generación y rendimiento.
- 1. Configuración detallada:
llm_avanzado = ChatOllama(
model="llama4:8b",
temperature=0.1, # Más determinista
num_predict=512, # Máximo de tokens a generar
top_k=10, # Limitar opciones de tokens
base_url="http://localhost:11434" # URL personalizada si es necesario
)
Embeddings con Ollama
Además de generación de texto, Ollama permite ejecutar modelos de embeddings localmente, lo cual es fundamental para aplicaciones RAG (Retrieval Augmented Generation) completamente privadas.
- 1. Uso de OllamaEmbeddings:
from langchain_ollama import OllamaEmbeddings
embeddings = OllamaEmbeddings(
model="nomic-embed-text"
)
vector = embeddings.embed_query("Texto para convertir a vector")
print(f"Dimensión del vector: {len(vector)}")
Asegúrate de haber hecho ollama pull nomic-embed-text previamente para tener el modelo de embeddings disponible.
Selección de modelos y recomendaciones
Ollama proporciona acceso a una amplia variedad de modelos de código abierto que se pueden ejecutar localmente. La elección del modelo adecuado depende del hardware disponible y de la tarea a realizar.
Modelos recomendados según hardware
La cantidad de memoria RAM y VRAM disponible determina qué modelos puedes ejecutar con fluidez:
- 8 GB de RAM: Modelos de hasta 3B de parámetros como
phi3:miniollama4:1b. - 16 GB de RAM: Modelos de 7-8B como
llama4:8b,mistralogemma2. - 32 GB+ de RAM: Modelos de 14-70B como
llama4:70bomixtral:8x7b.
# Modelo ligero para hardware limitado
llm_ligero = ChatOllama(model="phi3:mini", temperature=0.5)
# Modelo equilibrado para hardware intermedio
llm_medio = ChatOllama(model="llama4:8b", temperature=0.7)
Integración con cadenas LCEL
Los modelos de Ollama se integran perfectamente con LCEL para construir cadenas de procesamiento:
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
prompt = ChatPromptTemplate.from_template(
"Traduce al inglés el siguiente texto técnico: {texto}"
)
chain = prompt | llm | StrOutputParser()
resultado = chain.invoke({"texto": "Despliegue continuo con contenedores"})
print(resultado)
Streaming con modelos locales
El streaming funciona de forma idéntica a los proveedores en la nube, permitiendo recibir las respuestas token a token:
for chunk in llm.stream("Escribe una función Python que ordene una lista"):
print(chunk.content, end="", flush=True)
La principal ventaja de Ollama es que el streaming se produce sin latencia de red, ya que toda la inferencia se ejecuta en tu propia máquina. Esto resulta especialmente beneficioso para aplicaciones interactivas donde la velocidad de respuesta es crítica.
Verificación del estado del servidor
Antes de ejecutar consultas, puedes verificar que el servidor Ollama está activo y los modelos están disponibles:
# Comprobar que Ollama está ejecutándose
curl http://localhost:11434/api/tags
Este endpoint devuelve la lista de modelos disponibles en formato JSON, facilitando la verificación programática del estado del servidor.
Fuentes y referencias
Documentación oficial y recursos externos para profundizar en LangChain
Documentación oficial de LangChain
Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, LangChain es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de LangChain
Explora más contenido relacionado con LangChain y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Instalar y configurar Ollama, usar ChatOllama para ejecutar modelos locales, seleccionar modelos apropiados según necesidades, entender las ventajas de ejecución local para privacidad y costes, y trabajar con la API local de Ollama.
Cursos que incluyen esta lección
Esta lección forma parte de los siguientes cursos estructurados con rutas de aprendizaje