
Chunks pequeños para retrieval, documentos completos para contexto
La estrategia parent-child del MultiVectorRetriever resuelve uno de los dilemas más comunes en sistemas RAG: el equilibrio entre precisión en la búsqueda y riqueza del contexto. Tradicionalmente, los chunks pequeños ofrecen mayor precisión en el retrieval pero pueden carecer del contexto necesario para respuestas completas, mientras que los chunks grandes proporcionan contexto rico pero pueden diluir la relevancia en las búsquedas.
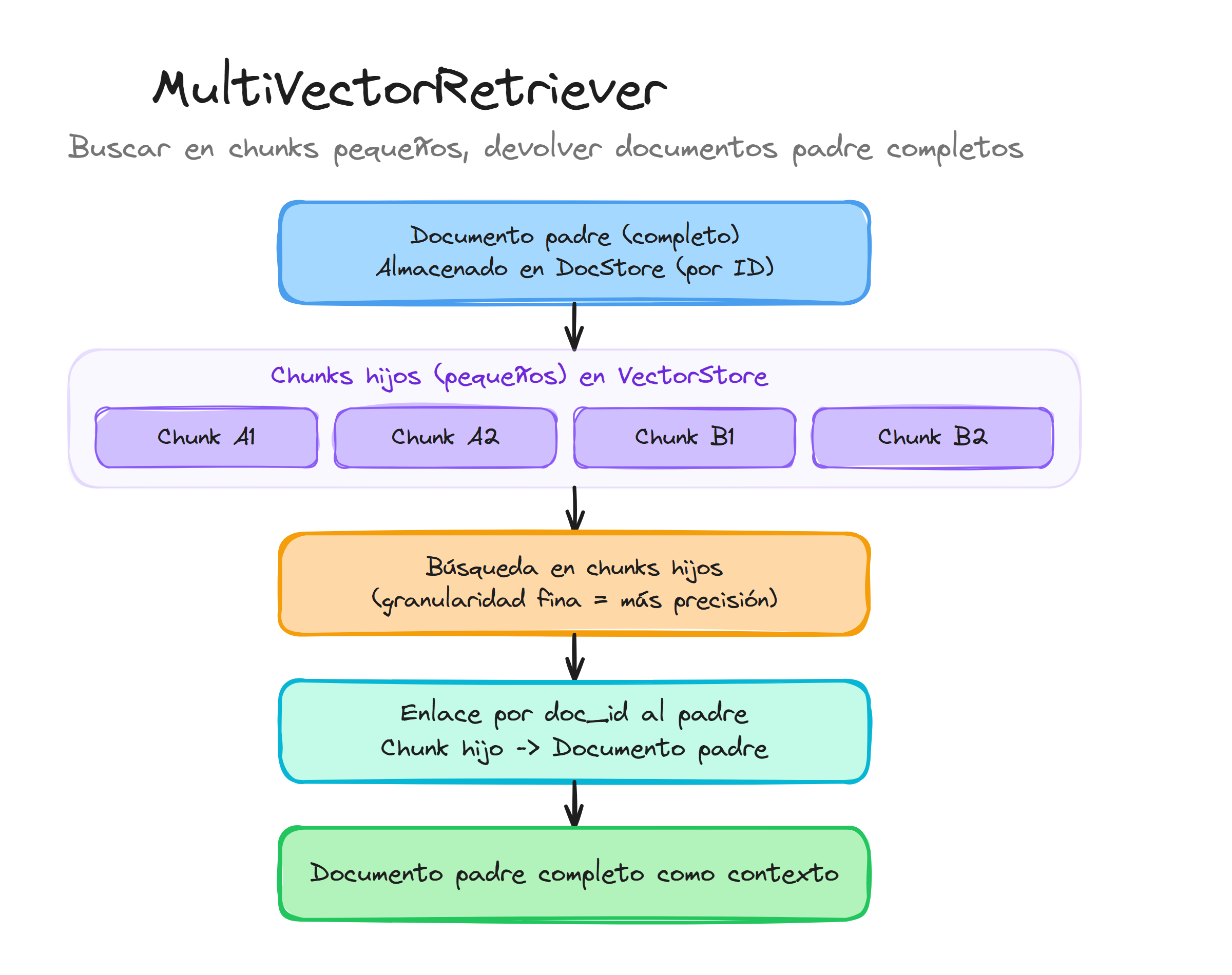
Configuración básica del MultiVectorRetriever
El MultiVectorRetriever utiliza dos almacenes separados para optimizar cada aspecto del proceso. El vectorstore almacena los embeddings de chunks pequeños para búsquedas precisas, mientras que el docstore mantiene los documentos completos para proporcionar contexto rico:
from langchain.retrievers.multi_vector import MultiVectorRetriever
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
from langchain.storage import InMemoryByteStore
from langchain_core.documents import Document
import uuid
# Configuración de los almacenes
vectorstore = Chroma(
collection_name="child_chunks",
embedding_function=OpenAIEmbeddings()
)
# Store para documentos padre
store = InMemoryByteStore()
# Configuración del retriever
retriever = MultiVectorRetriever(
vectorstore=vectorstore,
byte_store=store,
id_key="doc_id"
)
Implementación de la estrategia parent-child
La implementación práctica requiere dividir documentos largos en chunks pequeños manteniendo la referencia al documento padre. Cada chunk hijo se vincula a su documento padre mediante un identificador único:
from langchain_text_splitters import RecursiveCharacterTextSplitter
def create_parent_child_documents(documents, chunk_size=400, parent_chunk_size=10000):
"""
Crea documentos padre e hijo para MultiVectorRetriever
"""
# Splitter para documentos padre (contexto completo)
parent_splitter = RecursiveCharacterTextSplitter(
chunk_size=parent_chunk_size,
chunk_overlap=200
)
# Splitter para chunks hijo (retrieval preciso)
child_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=50
)
parent_docs = []
child_docs = []
for doc in documents:
# Crear documentos padre
parent_chunks = parent_splitter.split_documents([doc])
for parent_chunk in parent_chunks:
# Generar ID único para el documento padre
parent_id = str(uuid.uuid4())
parent_chunk.metadata["doc_id"] = parent_id
parent_docs.append(parent_chunk)
# Crear chunks hijo del documento padre
child_chunks = child_splitter.split_documents([parent_chunk])
for child_chunk in child_chunks:
# Vincular chunk hijo con documento padre
child_chunk.metadata["doc_id"] = parent_id
child_docs.append(child_chunk)
return parent_docs, child_docs
Proceso de indexación y retrieval
El proceso de indexación almacena los chunks pequeños en el vectorstore para búsquedas y los documentos padre en el docstore para contexto. Durante el retrieval, el sistema busca en los chunks pequeños pero devuelve los documentos padre correspondientes:
# Ejemplo con documentos académicos
documents = [
Document(
page_content="""
La inteligencia artificial ha experimentado un crecimiento exponencial
en las últimas décadas. Los modelos de lenguaje grandes (LLMs) representan
un avance significativo en el procesamiento de lenguaje natural...
[contenido extenso del paper]
""",
metadata={"source": "paper_ai_2024.pdf", "title": "Advances in AI"}
)
]
# Crear documentos padre e hijo
parent_docs, child_docs = create_parent_child_documents(documents)
# Indexar en el MultiVectorRetriever
retriever.vectorstore.add_documents(child_docs)
retriever.docstore.mset(
[(doc.metadata["doc_id"], doc) for doc in parent_docs]
)
Ventajas del enfoque parent-child
Esta estrategia ofrece múltiples beneficios en escenarios reales. Los chunks pequeños permiten búsquedas más precisas al reducir el ruido semántico, mientras que los documentos padre proporcionan el contexto completo necesario para respuestas comprehensivas:
# Búsqueda con chunks pequeños, contexto con documentos padre
query = "¿Cuáles son las limitaciones actuales de los LLMs?"
# El retriever busca en chunks de 400 tokens pero devuelve documentos de 10k tokens
relevant_docs = retriever.invoke(query)
# Los documentos devueltos contienen el contexto completo
for doc in relevant_docs:
print(f"Documento: {doc.metadata.get('title', 'Sin título')}")
print(f"Tamaño del contexto: {len(doc.page_content)} caracteres")
print(f"Fragmento: {doc.page_content[:200]}...")
Casos de uso optimizados
El enfoque parent-child resulta especialmente efectivo en documentos largos y estructurados. Los papers académicos, informes técnicos y documentos legales se benefician significativamente de esta estrategia:
# Configuración específica para documentos legales
legal_retriever = MultiVectorRetriever(
vectorstore=Chroma(
collection_name="legal_chunks",
embedding_function=OpenAIEmbeddings()
),
byte_store=InMemoryByteStore(),
id_key="doc_id"
)
# Chunks pequeños para encontrar cláusulas específicas
# Documentos padre para contexto legal completo
legal_parent_docs, legal_child_docs = create_parent_child_documents(
legal_documents,
chunk_size=300, # Cláusulas específicas
parent_chunk_size=15000 # Secciones completas del documento
)
La flexibilidad del MultiVectorRetriever permite ajustar los tamaños de chunks según el tipo de contenido y los requisitos específicos del dominio, optimizando tanto la precisión del retrieval como la riqueza del contexto proporcionado al modelo de lenguaje.
Summaries y hypothetical questions como índices
Más allá de la estrategia parent-child, el MultiVectorRetriever permite utilizar representaciones alternativas de los documentos como índices de búsqueda. Estas técnicas transforman el contenido original en formatos optimizados para el retrieval, manteniendo la capacidad de devolver el documento completo como contexto.
Estrategia de summaries como índices
La técnica de summaries genera resúmenes concisos de documentos largos que se utilizan como índices de búsqueda. Los embeddings se crean a partir de estos resúmenes, pero el sistema devuelve el documento original completo cuando encuentra una coincidencia relevante:
from langchain_openai import ChatOpenAI
from langchain_core.prompts import PromptTemplate
# Configuración del modelo para generar resúmenes
llm = ChatOpenAI(model="gpt-5.4", temperature=0)
# Template para generar resúmenes estructurados
summary_prompt = PromptTemplate(
template="""
Genera un resumen conciso y preciso del siguiente documento que capture:
- Los conceptos principales y temas centrales
- Las conclusiones o hallazgos más importantes
- El contexto y dominio del contenido
Documento:
{document}
Resumen:
""",
input_variables=["document"]
)
def generate_summaries(documents):
"""
Genera resúmenes para cada documento usando el LLM
"""
summaries = []
for doc in documents:
# Generar resumen del documento
summary_chain = summary_prompt | llm
summary_response = summary_chain.invoke({"document": doc.page_content})
# Crear documento de resumen con referencia al original
doc_id = str(uuid.uuid4())
summary_doc = Document(
page_content=summary_response.content,
metadata={
"doc_id": doc_id,
"type": "summary",
"original_title": doc.metadata.get("title", "Sin título")
}
)
# Mantener documento original con el mismo ID
original_doc = Document(
page_content=doc.page_content,
metadata={**doc.metadata, "doc_id": doc_id}
)
summaries.append((summary_doc, original_doc))
return summaries
Implementación práctica con summaries
La indexación con summaries requiere almacenar los resúmenes en el vectorstore y los documentos originales en el docstore. Esta separación permite búsquedas eficientes en contenido condensado mientras se mantiene acceso al contexto completo:
# Generar summaries para documentos técnicos
technical_documents = [
Document(
page_content="""
Este informe técnico analiza la implementación de microservicios
en arquitecturas distribuidas. Se examinan patrones de comunicación,
estrategias de deployment, y consideraciones de escalabilidad...
[contenido técnico extenso de 50 páginas]
""",
metadata={"source": "microservices_report.pdf", "type": "technical"}
)
]
# Crear summaries y documentos originales
summary_pairs = generate_summaries(technical_documents)
# Configurar retriever para summaries
summary_retriever = MultiVectorRetriever(
vectorstore=Chroma(
collection_name="document_summaries",
embedding_function=OpenAIEmbeddings()
),
byte_store=InMemoryByteStore(),
id_key="doc_id"
)
# Indexar summaries y documentos originales
summary_docs = [pair[0] for pair in summary_pairs]
original_docs = [pair[1] for pair in summary_pairs]
summary_retriever.vectorstore.add_documents(summary_docs)
summary_retriever.docstore.mset(
[(doc.metadata["doc_id"], doc) for doc in original_docs]
)
Estrategia de hypothetical questions
La técnica de hypothetical questions genera preguntas que cada documento podría responder, utilizando estas preguntas como índices de búsqueda. Este enfoque resulta especialmente efectivo para mejorar la coincidencia semántica entre queries de usuarios y contenido relevante:
# Template para generar preguntas hipotéticas
questions_prompt = PromptTemplate(
template="""
Basándote en el siguiente documento, genera 3-5 preguntas específicas
que este contenido podría responder de manera completa y precisa.
Las preguntas deben:
- Ser específicas y concretas
- Reflejar el conocimiento único del documento
- Usar terminología que los usuarios reales emplearían
Documento:
{document}
Preguntas (una por línea):
""",
input_variables=["document"]
)
def generate_hypothetical_questions(documents):
"""
Genera preguntas hipotéticas para cada documento
"""
question_pairs = []
for doc in documents:
# Generar preguntas hipotéticas
questions_chain = questions_prompt | llm
questions_response = questions_chain.invoke({"document": doc.page_content})
# Procesar respuesta y crear documentos de preguntas
questions = [q.strip() for q in questions_response.content.split('\n') if q.strip()]
doc_id = str(uuid.uuid4())
# Crear documento combinando todas las preguntas
questions_doc = Document(
page_content='\n'.join(questions),
metadata={
"doc_id": doc_id,
"type": "hypothetical_questions",
"question_count": len(questions)
}
)
# Documento original con mismo ID
original_doc = Document(
page_content=doc.page_content,
metadata={**doc.metadata, "doc_id": doc_id}
)
question_pairs.append((questions_doc, original_doc))
return question_pairs
Combinación de estrategias avanzadas
Las diferentes estrategias pueden combinarse para crear sistemas de retrieval más robustos. Un enfoque híbrido utiliza múltiples representaciones del mismo documento para maximizar las oportunidades de coincidencia:
def create_multi_representation_index(documents):
"""
Crea múltiples representaciones de documentos para retrieval optimizado
"""
# Generar summaries
summary_pairs = generate_summaries(documents)
# Generar hypothetical questions
question_pairs = generate_hypothetical_questions(documents)
# Configurar retriever híbrido
hybrid_retriever = MultiVectorRetriever(
vectorstore=Chroma(
collection_name="hybrid_representations",
embedding_function=OpenAIEmbeddings()
),
byte_store=InMemoryByteStore(),
id_key="doc_id"
)
# Indexar todas las representaciones
all_index_docs = []
all_original_docs = []
# Agregar summaries
all_index_docs.extend([pair[0] for pair in summary_pairs])
all_original_docs.extend([pair[1] for pair in summary_pairs])
# Agregar hypothetical questions
all_index_docs.extend([pair[0] for pair in question_pairs])
all_original_docs.extend([pair[1] for pair in question_pairs])
# Indexar en el retriever
hybrid_retriever.vectorstore.add_documents(all_index_docs)
hybrid_retriever.docstore.mset(
[(doc.metadata["doc_id"], doc) for doc in all_original_docs]
)
return hybrid_retriever
Optimización para dominios específicos
Cada estrategia se adapta mejor a tipos específicos de contenido. Los summaries funcionan excepcionalmente bien con documentos técnicos y académicos, mientras que las hypothetical questions son ideales para contenido de FAQ y documentación de productos:
# Configuración específica para documentación de API
api_docs = [
Document(
page_content="""
La API de autenticación OAuth 2.0 permite a las aplicaciones
acceder a recursos protegidos mediante tokens de acceso.
Endpoints disponibles: /auth/token, /auth/refresh, /auth/revoke...
[documentación técnica detallada]
""",
metadata={"source": "api_docs.md", "section": "authentication"}
)
]
# Las hypothetical questions capturan mejor las consultas de desarrolladores
api_questions_retriever = MultiVectorRetriever(
vectorstore=Chroma(collection_name="api_questions"),
byte_store=InMemoryByteStore(),
id_key="doc_id"
)
# Preguntas como: "¿Cómo implementar OAuth 2.0?", "¿Qué endpoints están disponibles?"
api_question_pairs = generate_hypothetical_questions(api_docs)
La flexibilidad del MultiVectorRetriever permite experimentar con diferentes representaciones según las características del contenido y los patrones de consulta esperados, optimizando la experiencia de retrieval para casos de uso específicos.
Fuentes y referencias
Documentación oficial y recursos externos para profundizar en LangChain
Documentación oficial de LangChain
Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, LangChain es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de LangChain
Explora más contenido relacionado con LangChain y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Implementar MultiVectorRetriever con estrategia parent-child, usar vectorstore para chunks pequeños y docstore para documentos completos, entender cómo optimiza precisión y contexto, trabajar con metadatos para vincular chunks y documentos, y aplicar esta estrategia en sistemas RAG complejos.