
Qué es LCEL
LCEL es el lenguaje de expresión de LangChain que te permite describir cadenas de procesamiento de forma declarativa usando Python normal, componiendo piezas como prompts, modelos y parsers sin tener que orquestarlo todo a mano con funciones o clases específicas de cada proveedor.
En lugar de pensar en "cómo" ejecutar cada paso, con LCEL describes "qué" etapas componen tu flujo y cómo se conectan, y la propia biblioteca se encarga de ejecutar la cadena con una API uniforme (invoke, batch, stream) y con optimizaciones internas como streaming y ejecución en paralelo cuando procede.
La idea central es ver cada bloque de LangChain Core como una transformación de datos: un prompt transforma un diccionario de entrada en mensajes, un modelo transforma mensajes en una respuesta y un parser transforma texto en tipos de datos de Python, y LCEL te permite encadenar estas transformaciones con el operador | como si fuera una tubería.
Un diagrama mental útil es imaginar un flujo donde cada eslabón recibe un tipo de dato y devuelve otro tipo claro, de forma que puedas razonar sobre cada paso de tu cadena sin perderte en detalles de bajo nivel.
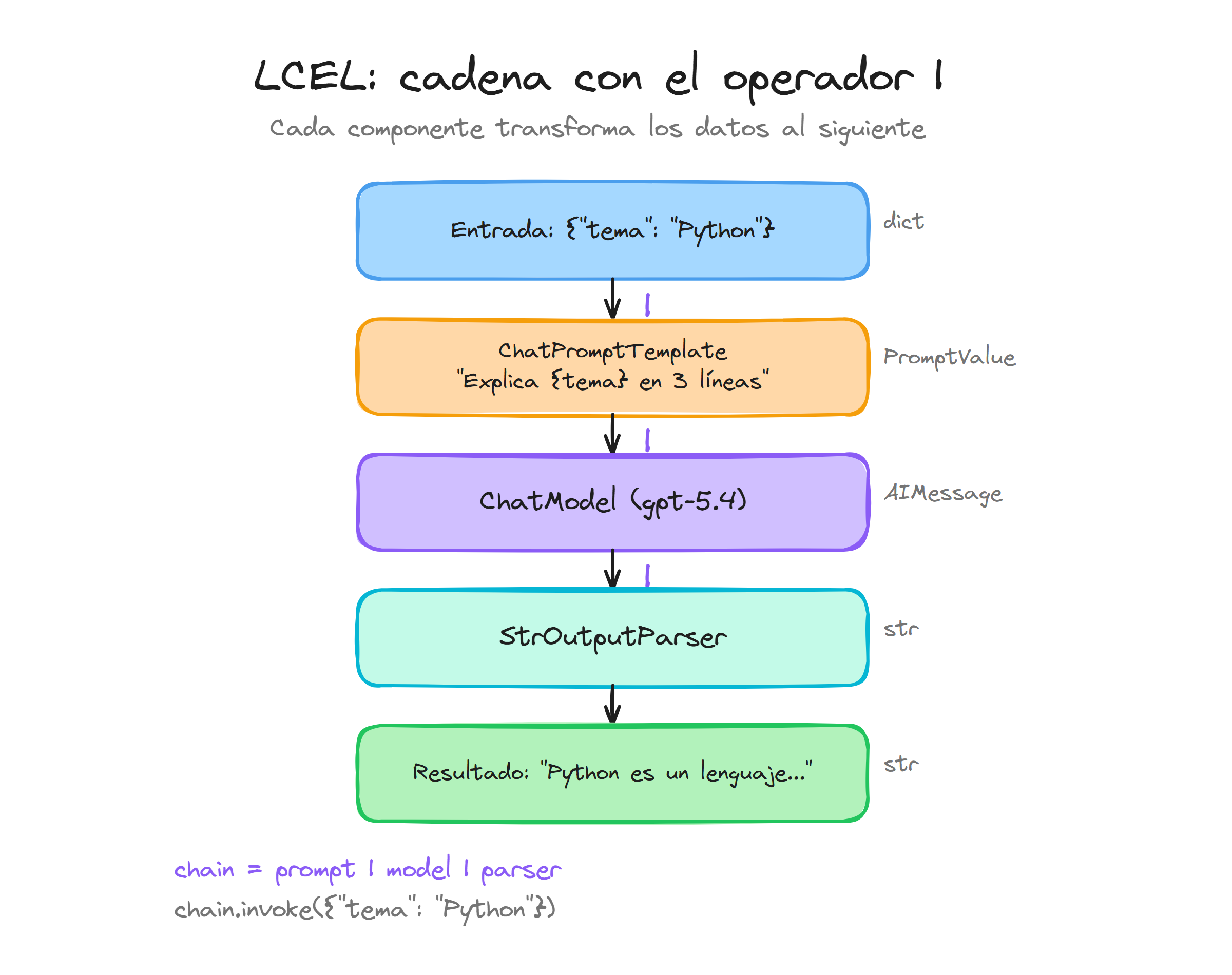
En las siguientes secciones verás el patrón más habitual de uso de LCEL en el día a día: primero prompt | model para convertir datos de negocio en peticiones al modelo, y después prompt | model | parser para terminar la cadena en un tipo que encaje bien con el resto de tu aplicación.
prompt | model
El patrón prompt | model es la columna vertebral de la mayoría de cadenas en LangChain, porque captura la idea de convertir una entrada estructurada en un mensaje bien redactado y después delegar la generación de texto en un modelo de lenguaje.
En este patrón, el prompt actúa como plantilla parametrizable que recibe un diccionario de entrada y produce mensajes, mientras que el modelo recibe esos mensajes y devuelve una respuesta de chat; la composición prompt | model es a su vez un objeto invocable que sigue la interfaz estándar de LCEL.
El siguiente ejemplo resuelve un problema muy habitual: dado el texto de una duda técnica, queremos obtener una respuesta breve y clara que podamos mostrar en una interfaz interna de soporte.
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
# Prompt que define el comportamiento del asistente
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"Eres un asistente técnico que responde de forma breve, precisa y en castellano de España.",
),
("human", "{pregunta}"),
]
)
# Modelo de chat del proveedor que prefieras
model = ChatOpenAI(model="gpt-5.4-mini", temperature=0)
En este fragmento defines por separado el prompt y el modelo, de forma que cada pieza tenga una única responsabilidad clara y puedas reutilizarla más adelante en otros flujos si lo necesitas.
Ahora puedes componer ambos elementos usando el operador | de LCEL y ejecutar la cadena resultante con el método invoke, que es la forma directa de procesar una sola entrada.
# Cadena LCEL de dos pasos: prompt -> modelo
chain = prompt | model
respuesta = chain.invoke({"pregunta": "¿Qué es LangChain Expression Language?"})
print(type(respuesta)) # langchain_core.messages.AIMessage
print(respuesta.content) # Texto generado por el modelo
Lo importante aquí es entender que chain es un único objeto que ya sabe cómo transformar tu diccionario de entrada en mensajes y pasarlos al modelo, y que ofrece siempre la misma API (invoke, batch, stream) independientemente del proveedor concreto que haya detrás.
Si más adelante necesitas procesar varias preguntas a la vez o quieres mostrar las respuestas en streaming, no tendrás que reescribir la lógica de composición, bastará con cambiar el método que llamas sobre la misma cadena prompt | model, lo que simplifica mucho el código de tu aplicación.
prompt | model | parser
El patrón prompt | model | parser añade un tercer eslabón a la cadena anterior para resolver otro problema muy práctico: el modelo devuelve mensajes ricos pensados para LangChain, pero tu código suele necesitar tipos simples como str, diccionarios o listas para integrarse con APIs, bases de datos o tests automatizados.
En la lección de output parsers ya has visto distintos tipos de parsers, así que aquí nos centraremos en cómo encajan dentro de una cadena LCEL para que la salida final tenga exactamente la forma que necesitas.
Siguiendo el ejemplo de soporte técnico, imaginemos que ahora quieres exponer este flujo desde una API HTTP que devuelve texto plano sin metadatos de chat, de modo que te interesa que la cadena produzca directamente una cadena de Python.
from langchain_core.output_parsers import StrOutputParser
# Parser que extrae solo el contenido textual del mensaje del modelo
parser = StrOutputParser()
Una vez definido el parser, basta con añadirlo al final de la cadena usando de nuevo el operador |, de forma que el resultado deje de ser un mensaje de chat y pase a ser una cadena lista para usar.
# Cadena completa: prompt -> modelo -> parser
text_chain = prompt | model | parser
respuesta_texto = text_chain.invoke(
{"pregunta": "Resume en una frase qué es LCEL en LangChain."}
)
print(type(respuesta_texto)) # str
print(respuesta_texto) # Texto listo para enviar por HTTP, guardar, etc.
Este pequeño cambio en el último eslabón tiene un impacto grande en la limpieza del código, porque te permite tratar la cadena LCEL como una función de negocio que recibe un diccionario y devuelve un str, sin exponer detalles internos de LangChain al resto de tu sistema.
En escenarios donde necesitas estructurar más la salida (por ejemplo, separar un campo respuesta de un campo nivel_confianza), puedes terminar la cadena con un parser que devuelva un diccionario, manteniendo el mismo esquema general prompt | model | parser y aprovechando que la última etapa siempre adapta el resultado al tipo que espera el resto de tu aplicación.
Fuentes y referencias
Documentación oficial y recursos externos para profundizar en LangChain
Documentación oficial de LangChain
Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, LangChain es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de LangChain
Explora más contenido relacionado con LangChain y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Comprender el concepto de LCEL y su sintaxis con el operador |, construir cadenas prompt. model y prompt. model. parser, entender cómo LCEL abstrae la ejecución, y crear flujos de procesamiento reutilizables y mantenibles.
Cursos que incluyen esta lección
Esta lección forma parte de los siguientes cursos estructurados con rutas de aprendizaje