
EnsembleRetriever para combinar algoritmos
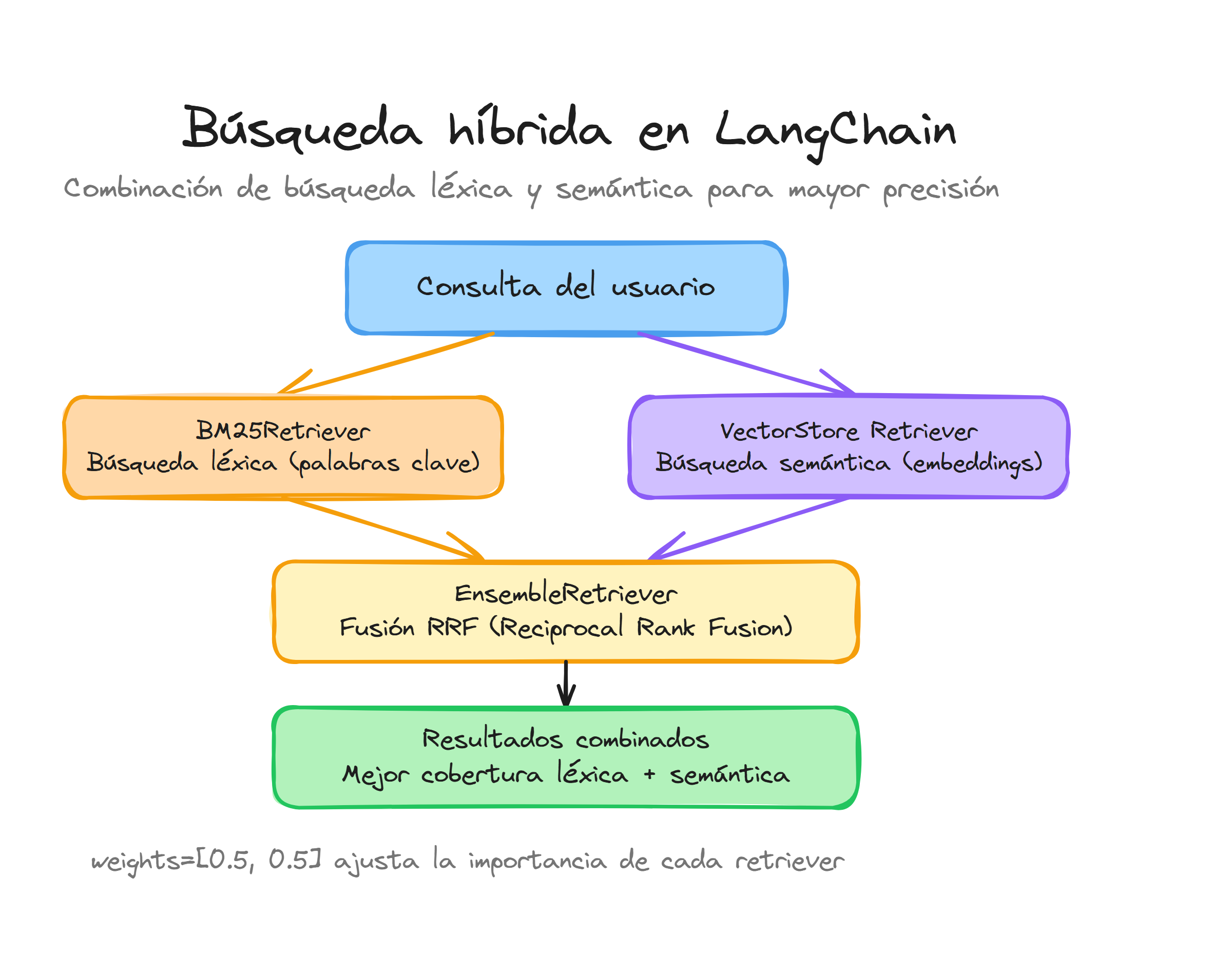
El EnsembleRetriever de LangChain permite combinar múltiples algoritmos de recuperación para aprovechar las fortalezas de cada uno.
Esta aproximación híbrida resulta especialmente efectiva cuando necesitamos equilibrar la precisión lexical de las búsquedas por palabras clave con la comprensión semántica de los embeddings vectoriales.

Fundamentos del EnsembleRetriever
El EnsembleRetriever utiliza el algoritmo Reciprocal Rank Fusion (RRF) para combinar los resultados de diferentes retrievers. Este método asigna puntuaciones basadas en la posición de cada documento en los rankings individuales, permitiendo una fusión equilibrada de resultados heterogéneos.
La implementación básica requiere definir los retrievers individuales y sus pesos relativos:
from langchain.retrievers import EnsembleRetriever, BM25Retriever
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
# Preparar documentos de ejemplo
documents = [
"Python es un lenguaje de programación interpretado",
"FastAPI es un framework web moderno para Python",
"Django proporciona un ORM robusto para bases de datos",
"Flask es un microframework minimalista para aplicaciones web"
]
# Crear retriever semántico
embeddings = OpenAIEmbeddings()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=0)
texts = text_splitter.create_documents(documents)
vectorstore = FAISS.from_documents(texts, embeddings)
vector_retriever = vectorstore.as_retriever(search_kwargs={"k": 3})
# Crear retriever BM25
bm25_retriever = BM25Retriever.from_documents(texts)
bm25_retriever.k = 3
# Combinar con EnsembleRetriever
ensemble_retriever = EnsembleRetriever(
retrievers=[vector_retriever, bm25_retriever],
weights=[0.5, 0.5]
)
Configuración de pesos y balanceado
Los pesos del EnsembleRetriever determinan la influencia relativa de cada algoritmo en el resultado final. La configuración óptima depende del tipo de consultas y contenido:
# Configuración equilibrada (50/50)
ensemble_balanced = EnsembleRetriever(
retrievers=[vector_retriever, bm25_retriever],
weights=[0.5, 0.5]
)
# Priorizar búsqueda semántica (70% vectorial, 30% BM25)
ensemble_semantic = EnsembleRetriever(
retrievers=[vector_retriever, bm25_retriever],
weights=[0.7, 0.3]
)
# Priorizar coincidencias exactas (30% vectorial, 70% BM25)
ensemble_lexical = EnsembleRetriever(
retrievers=[vector_retriever, bm25_retriever],
weights=[0.3, 0.7]
)
Para consultas técnicas con terminología específica, un peso mayor hacia BM25 mejora la precisión. Para consultas conceptuales o con sinónimos, priorizar la búsqueda vectorial ofrece mejor cobertura semántica.
Implementación práctica con múltiples retrievers
El EnsembleRetriever puede combinar más de dos algoritmos, permitiendo configuraciones sofisticadas:
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainExtractor
from langchain_openai import ChatOpenAI
# Crear un tercer retriever con compresión contextual
llm = ChatOpenAI(model="gpt-5.4-mini", temperature=0)
compressor = LLMChainExtractor.from_llm(llm)
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor,
base_retriever=vector_retriever
)
# Ensemble con tres retrievers
multi_ensemble = EnsembleRetriever(
retrievers=[vector_retriever, bm25_retriever, compression_retriever],
weights=[0.4, 0.4, 0.2]
)
# Probar con consulta específica
query = "¿Qué framework web de Python es mejor para APIs?"
results = multi_ensemble.invoke(query)
for i, doc in enumerate(results):
print(f"Resultado {i+1}: {doc.page_content}")
Optimización del rendimiento
El rendimiento del EnsembleRetriever puede optimizarse ajustando los parámetros de cada retriever individual:
# Configurar retrievers con parámetros específicos
vector_retriever = vectorstore.as_retriever(
search_type="similarity_score_threshold",
search_kwargs={
"k": 5,
"score_threshold": 0.7
}
)
bm25_retriever = BM25Retriever.from_documents(texts)
bm25_retriever.k = 5
# Ensemble optimizado
optimized_ensemble = EnsembleRetriever(
retrievers=[vector_retriever, bm25_retriever],
weights=[0.6, 0.4],
search_kwargs={"k": 3} # Limitar resultados finales
)
La configuración del parámetro k en cada retriever individual afecta la diversidad de resultados antes de la fusión RRF. Un valor mayor permite más candidatos para el ranking final, mientras que un valor menor reduce la latencia.
Integración con LCEL
El EnsembleRetriever se integra naturalmente con LangChain Expression Language (LCEL) para crear pipelines de RAG híbrido:
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
# Definir prompt para RAG
prompt = ChatPromptTemplate.from_template("""
Responde la pregunta basándote únicamente en el contexto proporcionado:
Contexto: {context}
Pregunta: {question}
Respuesta:
""")
# Crear cadena RAG híbrida
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
rag_chain = (
{"context": ensemble_retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| ChatOpenAI(model="gpt-5.4", temperature=0)
| StrOutputParser()
)
# Ejecutar consulta
response = rag_chain.invoke("¿Cuáles son las ventajas de FastAPI?")
print(response)
Esta implementación aprovecha las capacidades de composición de LCEL para crear un sistema RAG que combina automáticamente resultados de múltiples algoritmos de recuperación, proporcionando respuestas más completas y precisas.
BM25 + búsqueda semántica
La combinación de BM25 con búsqueda semántica representa el núcleo de los sistemas de recuperación híbrida. Mientras que BM25 excele en encontrar coincidencias exactas de términos, la búsqueda vectorial captura relaciones semánticas y conceptuales que las palabras clave por sí solas no pueden detectar.
Ventajas complementarias de cada algoritmo
El algoritmo BM25 utiliza estadísticas de frecuencia de términos para calcular la relevancia, siendo especialmente efectivo para:
- Nombres propios y entidades específicas: "OpenAI", "LangChain", "FastAPI"
- Términos técnicos exactos: "async/await", "middleware", "serialización"
- Consultas con palabras clave precisas: "error 404", "status code 200"
La búsqueda semántica mediante embeddings vectoriales complementa estas capacidades manejando:
- Sinónimos y variaciones: "rápido" vs "veloz", "error" vs "fallo"
- Conceptos relacionados: "machine learning" conecta con "inteligencia artificial"
- Consultas en lenguaje natural: "¿Cómo puedo hacer que mi API sea más rápida?"
Implementación práctica del sistema híbrido
La implementación efectiva requiere configurar ambos retrievers con parámetros optimizados para el dominio específico:
from langchain.retrievers import BM25Retriever
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
# Documentación técnica de ejemplo
tech_docs = [
"FastAPI utiliza Pydantic para validación automática de datos",
"El decorador @app.get() define endpoints HTTP GET en FastAPI",
"Uvicorn es el servidor ASGI recomendado para aplicaciones FastAPI",
"SQLAlchemy ORM proporciona mapeo objeto-relacional para Python",
"Alembic maneja migraciones de base de datos en proyectos SQLAlchemy",
"JWT tokens proporcionan autenticación stateless en APIs REST"
]
# Preparar documentos
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=200,
chunk_overlap=20
)
documents = text_splitter.create_documents(tech_docs)
# Configurar retriever BM25
bm25_retriever = BM25Retriever.from_documents(documents)
bm25_retriever.k = 4
# Configurar retriever semántico
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
vectorstore = FAISS.from_documents(documents, embeddings)
semantic_retriever = vectorstore.as_retriever(
search_type="similarity",
search_kwargs={"k": 4}
)
Casos de uso donde hybrid search supera semantic search
El rendimiento superior del sistema híbrido se manifiesta claramente en escenarios específicos:
1. Consultas con nombres propios:
# Consulta que requiere matching exacto
query_exact = "¿Cómo configurar Uvicorn para producción?"
# BM25 encuentra "Uvicorn" exactamente
bm25_results = bm25_retriever.invoke(query_exact)
print("BM25 - Primer resultado:")
print(bm25_results[0].page_content)
# Búsqueda semántica puede no capturar el término específico
semantic_results = semantic_retriever.invoke(query_exact)
print("\nSemántica - Primer resultado:")
print(semantic_results[0].page_content)
2. Terminología técnica específica:
# Consulta con término técnico preciso
query_technical = "¿Qué es SQLAlchemy ORM?"
# Comparar resultados de ambos enfoques
print("=== Resultados BM25 ===")
for doc in bm25_retriever.invoke(query_technical)[:2]:
print(f"- {doc.page_content}")
print("\n=== Resultados Semánticos ===")
for doc in semantic_retriever.invoke(query_technical)[:2]:
print(f"- {doc.page_content}")
3. Consultas conceptuales amplias:
# Consulta que requiere comprensión semántica
query_conceptual = "¿Cómo validar datos de entrada en APIs?"
# La búsqueda semántica conecta conceptos relacionados
semantic_results = semantic_retriever.invoke(query_conceptual)
print("Semántica captura conceptos relacionados:")
for doc in semantic_results[:2]:
print(f"- {doc.page_content}")
Configuración de pesos según el dominio
La configuración óptima de pesos varía según las características del contenido y tipos de consulta esperados:
from langchain.retrievers import EnsembleRetriever
# Para documentación técnica con muchos términos específicos
tech_ensemble = EnsembleRetriever(
retrievers=[semantic_retriever, bm25_retriever],
weights=[0.3, 0.7] # Priorizar BM25 para términos exactos
)
# Para contenido general con consultas conceptuales
general_ensemble = EnsembleRetriever(
retrievers=[semantic_retriever, bm25_retriever],
weights=[0.7, 0.3] # Priorizar semántica para comprensión
)
# Configuración equilibrada para casos mixtos
balanced_ensemble = EnsembleRetriever(
retrievers=[semantic_retriever, bm25_retriever],
weights=[0.5, 0.5]
)
Evaluación comparativa del rendimiento
Para evaluar la efectividad del sistema híbrido, podemos comparar resultados con diferentes tipos de consultas:
# Conjunto de consultas de prueba
test_queries = [
"FastAPI validación Pydantic", # Términos exactos
"¿Cómo validar datos automáticamente?", # Conceptual
"servidor ASGI para APIs Python", # Mixta
"JWT autenticación stateless" # Técnica específica
]
def evaluate_retriever(retriever, query, name):
results = retriever.invoke(query)
print(f"\n=== {name} - '{query}' ===")
for i, doc in enumerate(results[:2]):
print(f"{i+1}. {doc.page_content}")
# Comparar rendimiento
for query in test_queries:
evaluate_retriever(bm25_retriever, query, "BM25")
evaluate_retriever(semantic_retriever, query, "Semántica")
evaluate_retriever(balanced_ensemble, query, "Híbrido")
print("-" * 60)
Soporte nativo en vectorstores modernos
Muchos vectorstores modernos implementan búsqueda híbrida de forma nativa, eliminando la necesidad de combinar retrievers separados:
# Ejemplo conceptual con MongoDB Atlas
# (requiere configuración específica del cluster)
"""
from langchain_mongodb import MongoDBAtlasVectorSearch
# MongoDB Atlas con índice híbrido
atlas_search = MongoDBAtlasVectorSearch(
collection=collection,
embedding=embeddings,
index_name="hybrid_index",
# Configuración híbrida nativa
search_type="hybrid",
alpha=0.5 # Balance entre semántica (0) y lexical (1)
)
"""
# Elasticsearch con búsqueda híbrida
"""
from langchain_elasticsearch import ElasticsearchStore
# Elasticsearch con capacidades híbridas
es_store = ElasticsearchStore(
es_url="http://localhost:9200",
index_name="hybrid_docs",
embedding=embeddings,
# Configuración para búsqueda híbrida
strategy=ElasticsearchStore.SparseVectorRetrievalStrategy()
)
"""
La ventaja de los vectorstores nativos radica en la optimización a nivel de índice, donde la fusión de resultados ocurre directamente en la base de datos, reduciendo latencia y mejorando el rendimiento general del sistema.
Esta aproximación híbrida establece las bases para técnicas más avanzadas de recuperación, donde la combinación inteligente de algoritmos complementarios produce resultados superiores a cualquier método individual.
Fuentes y referencias
Documentación oficial y recursos externos para profundizar en LangChain
Documentación oficial de LangChain
Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, LangChain es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de LangChain
Explora más contenido relacionado con LangChain y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Implementar EnsembleRetriever combinando retrievers múltiples, equilibrar búsqueda lexical y semántica, trabajar con pesos para diferentes retrievers, entender cómo mejora cobertura de resultados, y aplicar técnicas de ensemble retrieval en sistemas RAG.