
HuggingFacePipeline en LangChain
HuggingFacePipeline permite la ejecución local de modelos alojados en Hugging Face Hub. Esta aproximación descarga los pesos del modelo a tu infraestructura y utiliza tu propio hardware (CPU o GPU) para la inferencia, ofreciendo privacidad absoluta y control total sin depender de servicios externos.
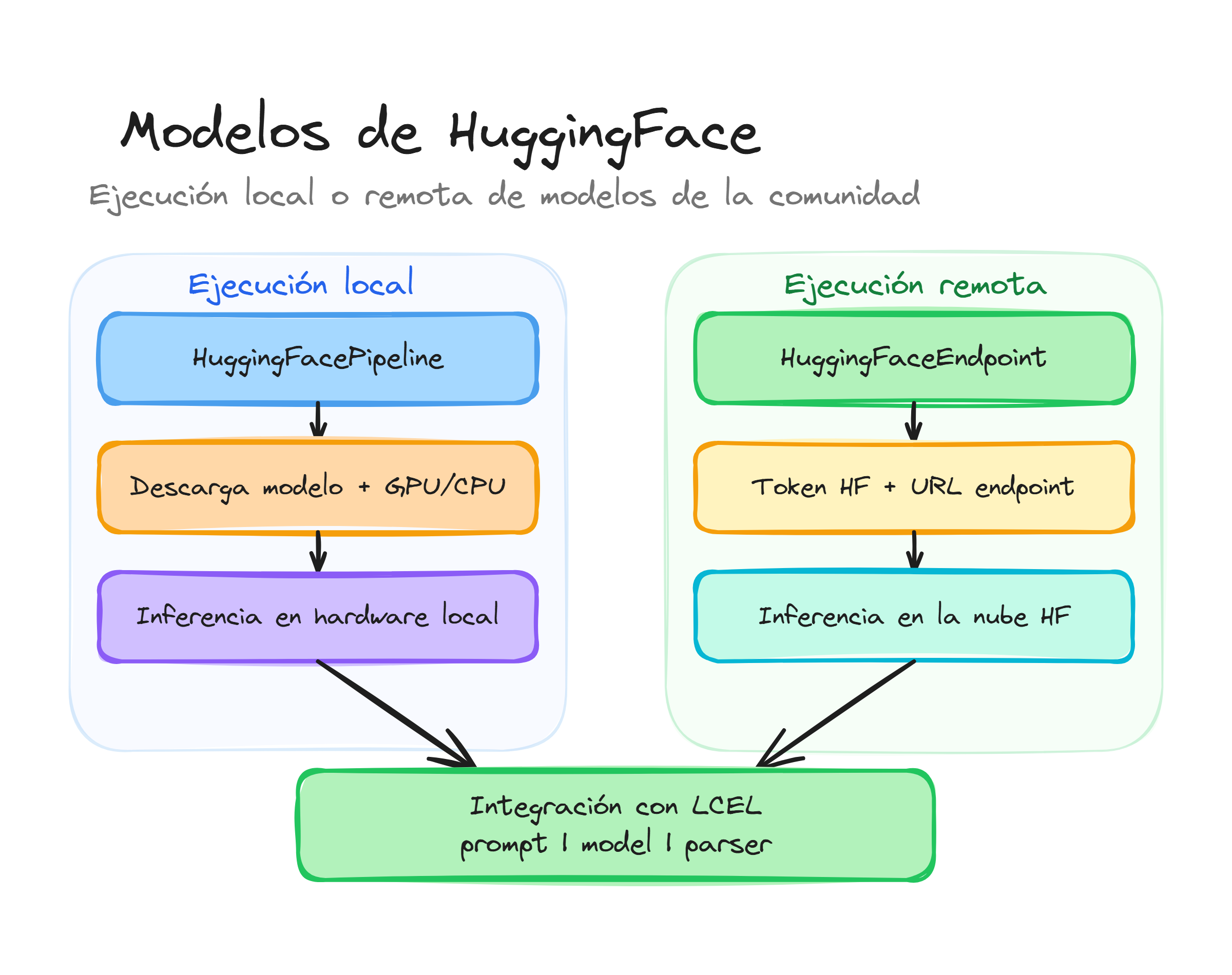
Es ideal para investigación, desarrollo offline o cuando las políticas de datos impiden el uso de APIs en la nube. Sin embargo, requiere recursos de hardware considerables dependiendo del tamaño del modelo elegido.
Instalación y configuración
Para utilizar esta integración, es necesario instalar el paquete langchain-huggingface junto con las librerías base de transformers.
pip install langchain-huggingface transformers torch
Creación de un Pipeline local
El pipeline carga el modelo en memoria. Puedes especificar parámetros para optimizar el uso de recursos, como la cuantización o el mapeo automático de dispositivos.
- 1. Configuración del Pipeline:
from langchain_huggingface import HuggingFacePipeline
# Cargar un modelo ligero para generación de texto
llm = HuggingFacePipeline.from_model_id(
model_id="gpt2", # Modelo de ejemplo ligero
task="text-generation",
pipeline_kwargs={
"max_new_tokens": 100,
"top_k": 50,
"temperature": 0.7,
},
)
print(llm.invoke("La inteligencia artificial es"))
- 2. Uso con ChatHuggingFace:
Para modelos instructivos o de chat, es recomendable envolver el pipeline en ChatHuggingFace para manejar correctamente el formato de los mensajes.
from langchain_huggingface import ChatHuggingFace
chat_model = ChatHuggingFace(llm=llm)
Consideraciones de Hardware
La ejecución local depende críticamente de tu hardware. Si dispones de una GPU NVIDIA, asegúrate de tener instalada la versión correcta de torch con soporte CUDA para acelerar la inferencia.
# Ejemplo de configuración para usar GPU si está disponible
pipeline_kwargs={
"device_map": "auto", # Usa GPU automáticamente si es posible
"torch_dtype": "auto"
}
HuggingFaceEndpoint en LangChain
HuggingFaceEndpoint es la alternativa para consumir modelos a través de la API de Inferencia Serverless de Hugging Face. A diferencia del pipeline local, no requiere descargar el modelo ni tener hardware potente, ya que la computación se realiza en los servidores de Hugging Face.
Esta opción es excelente para probar modelos grandes (como Llama 4 70B o Mixtral) que no cabrían en la memoria de un ordenador personal estándar.
Configuración del Token
Para usar la API, necesitas un User Access Token de Hugging Face.
-
1. Obtención del token: Ve a tus ajustes en Hugging Face, sección "Access Tokens", y crea un token con permisos de lectura.
-
2. Configuración en Python:
import os
from dotenv import load_dotenv
load_dotenv()
# Asegúrate de tener HUGGINGFACEHUB_API_TOKEN en tu .env
Uso de HuggingFaceEndpoint
La clase HuggingFaceEndpoint se conecta a la API remota. Puedes elegir entre miles de modelos disponibles en el Hub.
- 1. Inicialización del Endpoint:
from langchain_huggingface import HuggingFaceEndpoint
llm_remoto = HuggingFaceEndpoint(
repo_id="HuggingFaceH4/zephyr-7b-beta",
task="text-generation",
max_new_tokens=512,
do_sample=True,
temperature=0.7
)
response = llm_remoto.invoke("Explica qué es un Transformer en NLP")
print(response)
Integración con Cadenas (Chains)
Ambas opciones (Pipeline y Endpoint) son totalmente compatibles con el ecosistema de LangChain y pueden usarse dentro de cadenas LCEL.
- 1. Ejemplo de cadena con LCEL:
from langchain_core.prompts import PromptTemplate
template = PromptTemplate.from_template(
"Resume el siguiente concepto técnico en una frase: {concepto}"
)
chain = template | llm_remoto
print(chain.invoke({"concepto": "Regularización en Machine Learning"}))
Comparativa: Pipeline vs Endpoint
-
Pipeline (Local):
- Pros: Privacidad total, sin latencia de red, sin costes por token.
- Contras: Requiere hardware potente, descarga inicial lenta, gestión de dependencias compleja.
-
Endpoint (Remoto):
- Pros: Acceso inmediato a modelos grandes, no requiere GPU local, fácil de configurar.
- Contras: Dependencia de internet, límites de rate (en capa gratuita), datos viajan a servidores externos.
Selección de modelos y consideraciones prácticas
La elección del modelo adecuado en Hugging Face depende de varios factores: el tamaño del modelo, los recursos de hardware disponibles y el tipo de tarea a realizar. A continuación se presentan recomendaciones prácticas para diferentes escenarios.
Modelos recomendados por caso de uso
Para tareas de generación de texto con recursos limitados, los modelos más ligeros ofrecen un buen equilibrio entre calidad y rendimiento:
from langchain_huggingface import HuggingFacePipeline
# Modelo ligero para clasificación y tareas simples
llm_ligero = HuggingFacePipeline.from_model_id(
model_id="distilgpt2",
task="text-generation",
pipeline_kwargs={"max_new_tokens": 200}
)
# Modelo intermedio para generación de texto más elaborada
llm_intermedio = HuggingFacePipeline.from_model_id(
model_id="microsoft/phi-2",
task="text-generation",
pipeline_kwargs={
"max_new_tokens": 512,
"device_map": "auto"
}
)
Gestión de memoria y recursos
La ejecución local de modelos puede consumir una cantidad significativa de memoria RAM y VRAM. Es importante monitorizar y gestionar estos recursos para evitar errores de memoria:
import torch
# Verificar disponibilidad de GPU
if torch.cuda.is_available():
print(f"GPU disponible: {torch.cuda.get_device_name(0)}")
print(f"VRAM total: {torch.cuda.get_device_properties(0).total_mem / 1e9:.1f} GB")
print(f"VRAM libre: {torch.cuda.mem_get_info()[0] / 1e9:.1f} GB")
else:
print("Sin GPU, se usará CPU (más lento)")
Embeddings con Hugging Face
Además de la generación de texto, Hugging Face ofrece modelos de embeddings que pueden ejecutarse localmente, lo cual resulta esencial para aplicaciones RAG completamente privadas:
from langchain_huggingface import HuggingFaceEmbeddings
embeddings = HuggingFaceEmbeddings(
model_name="sentence-transformers/all-mpnet-base-v2",
model_kwargs={"device": "cpu"},
encode_kwargs={"normalize_embeddings": True}
)
vector = embeddings.embed_query("Ejemplo de texto para vectorizar")
print(f"Dimensiones del embedding: {len(vector)}")
El modelo all-mpnet-base-v2 produce embeddings de 768 dimensiones y ofrece un rendimiento sólido en tareas de búsqueda semántica. Para aplicaciones que requieren mayor precisión, el modelo all-MiniLM-L12-v2 proporciona un buen equilibrio entre calidad y velocidad de inferencia.
La integración de Hugging Face con LangChain democratiza el acceso a modelos de inteligencia artificial, permitiendo a los desarrolladores ejecutar inferencia localmente con total control sobre los datos y sin dependencia de servicios externos.
Fuentes y referencias
Documentación oficial y recursos externos para profundizar en LangChain
Documentación oficial de LangChain
Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, LangChain es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de LangChain
Explora más contenido relacionado con LangChain y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Instalar langchain-huggingface y transformers, crear pipelines locales con HuggingFacePipeline, configurar modelos para ejecución en CPU o GPU, optimizar recursos con cuantización, y entender las ventajas y limitaciones de modelos locales.
Cursos que incluyen esta lección
Esta lección forma parte de los siguientes cursos estructurados con rutas de aprendizaje