
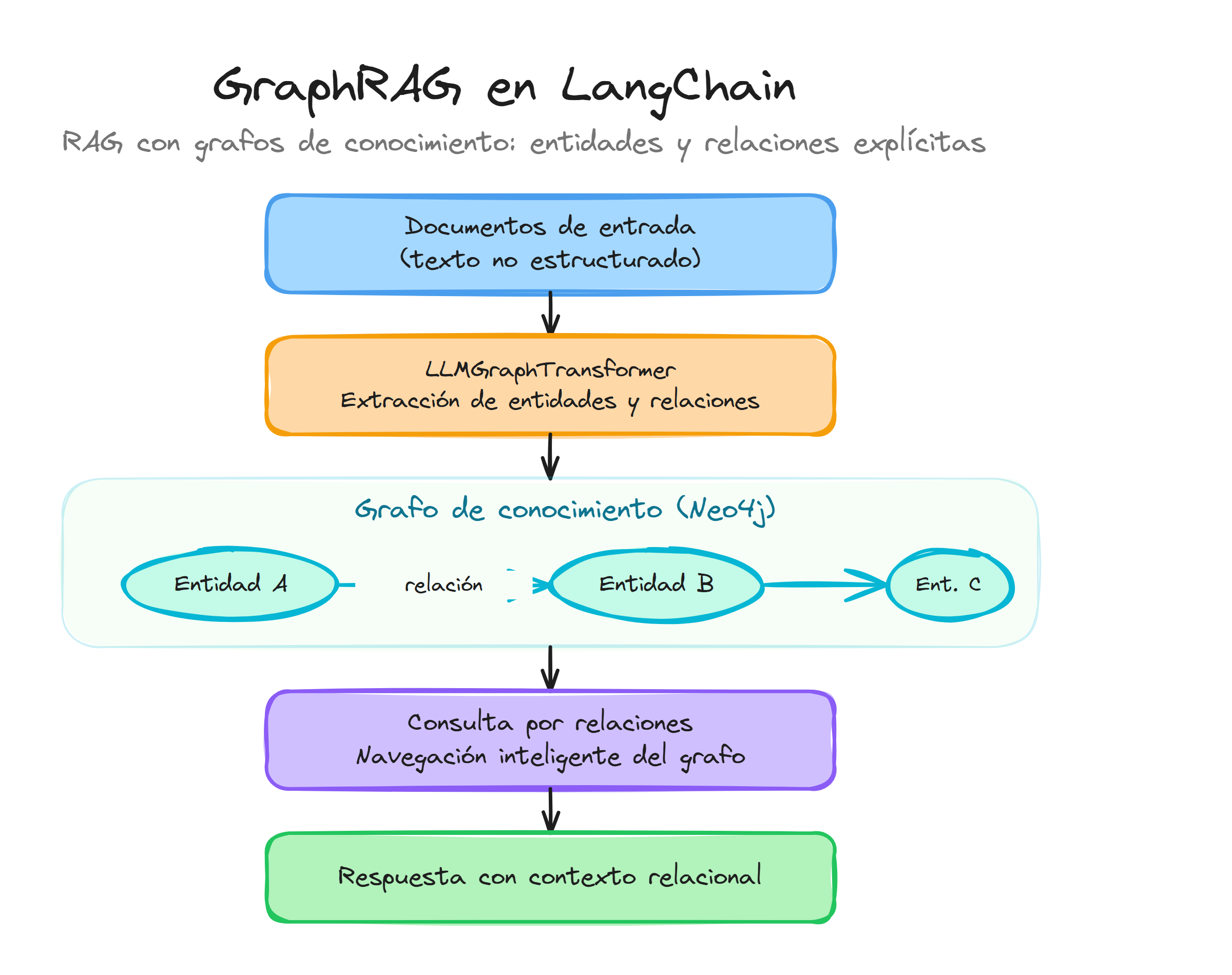
Knowledge graphs con LLMGraphTransformer
Los knowledge graphs representan información como una red de entidades conectadas por relaciones específicas, permitiendo capturar el contexto semántico que los embeddings vectoriales por sí solos no pueden preservar completamente. En el contexto de RAG, esta estructura nos permite realizar búsquedas que van más allá de la similaridad textual, explorando conexiones conceptuales entre diferentes elementos de nuestros documentos.
LLMGraphTransformer es la herramienta de LangChain que automatiza la extracción de entidades y relaciones desde texto no estructurado utilizando modelos de lenguaje. Esta clase analiza documentos y genera automáticamente los nodos (entidades) y aristas (relaciones) que formarán nuestro grafo de conocimiento.
Configuración básica del transformador
Para comenzar a trabajar con LLMGraphTransformer, necesitamos importar las dependencias necesarias y configurar tanto el modelo de lenguaje como la conexión a la base de datos de grafos:
from langchain_experimental.graph_transformers import LLMGraphTransformer
from langchain_openai import ChatOpenAI
from langchain_neo4j import Neo4jGraph
from langchain_core.documents import Document

Instalar Neo4j para LangChain
pip install neo4j langchain-neo4j
La configuración inicial requiere establecer la conexión con Neo4j y crear una instancia del transformador:
from langchain_neo4j import Neo4jGraph
from langchain_experimental.graph_transformers import LLMGraphTransformer
from langchain_openai import ChatOpenAI
# Configuración de la base de datos Neo4j
graph = Neo4jGraph(
url="bolt://localhost:7687",
username="neo4j",
password="password"
)
# Configuración del modelo de lenguaje
llm = ChatOpenAI(
model="gpt-5.4",
temperature=0
)
# Creación del transformador
graph_transformer = LLMGraphTransformer(
llm=llm,
allowed_nodes=["Person", "Organization", "Location", "Technology"],
allowed_relationships=["WORKS_FOR", "LOCATED_IN", "USES", "COLLABORATES_WITH"]
)
Los parámetros allowed_nodes y allowed_relationships son cruciales para mantener la consistencia del grafo. Al especificar tipos permitidos, evitamos la creación de entidades y relaciones redundantes o inconsistentes que podrían surgir de las variaciones en el procesamiento del LLM.
Procesamiento de documentos
El proceso de transformación convierte documentos de texto en estructuras de grafo. Veamos cómo procesar un conjunto de documentos técnicos:
# Documentos de ejemplo sobre tecnología
documents = [
Document(
page_content="""
OpenAI desarrolló GPT-4, un modelo de lenguaje avanzado utilizado
por muchas empresas tecnológicas. La empresa tiene su sede en
San Francisco y colabora frecuentemente con Microsoft en
proyectos de inteligencia artificial.
""",
metadata={"source": "tech_news.txt"}
),
Document(
page_content="""
Microsoft Azure proporciona servicios de nube que incluyen
capacidades de IA. La compañía, ubicada en Redmond, utiliza
tecnologías de OpenAI para mejorar sus productos de productividad
como Office 365.
""",
metadata={"source": "cloud_services.txt"}
)
]
# Transformación a estructuras de grafo
graph_documents = graph_transformer.convert_to_graph_documents(documents)
El resultado de esta transformación son GraphDocument objects que contienen las entidades extraídas, sus relaciones y los metadatos asociados. Cada documento se procesa independientemente, pero las entidades comunes se pueden unificar posteriormente.
Almacenamiento en Neo4j
Una vez extraídas las estructuras de grafo, necesitamos almacenarlas en Neo4j para poder realizar consultas eficientes:
# Almacenamiento en la base de datos
graph.add_graph_documents(
graph_documents,
baseEntityLabel=True,
include_source=True
)
# Verificación del contenido almacenado
result = graph.query("""
MATCH (n)-[r]->(m)
RETURN n.id as source, type(r) as relationship, m.id as target
LIMIT 10
""")
for record in result:
print(f"{record['source']} -> {record['relationship']} -> {record['target']}")
El parámetro baseEntityLabel asegura que todas las entidades tengan una etiqueta base común, facilitando consultas generales. La opción include_source mantiene la trazabilidad hacia los documentos originales.
Personalización del proceso de extracción
Para casos específicos, podemos personalizar el comportamiento del transformador mediante prompts específicos y configuraciones avanzadas:
# Configuración avanzada con prompt personalizado
custom_transformer = LLMGraphTransformer(
llm=llm,
allowed_nodes=["Person", "Company", "Product", "Technology", "Location"],
allowed_relationships=[
"DEVELOPS", "USES", "COMPETES_WITH", "PARTNERS_WITH",
"LOCATED_IN", "WORKS_FOR"
],
prompt="""
Extrae entidades y relaciones del siguiente texto, enfocándote en:
- Personas y sus roles profesionales
- Empresas y sus productos principales
- Tecnologías y sus aplicaciones
- Ubicaciones geográficas relevantes
Texto: {text}
"""
)
Esta personalización permite adaptar la extracción a dominios específicos, mejorando la precisión y relevancia de las entidades y relaciones identificadas.
Manejo de entidades complejas
Cuando trabajamos con documentos que contienen referencias ambiguas o entidades con múltiples menciones, es importante configurar estrategias de resolución:
# Procesamiento con resolución de entidades
def process_with_entity_resolution(documents):
# Primera pasada: extracción básica
graph_docs = graph_transformer.convert_to_graph_documents(documents)
# Almacenamiento inicial
graph.add_graph_documents(graph_docs)
# Consulta para identificar posibles duplicados
duplicates_query = """
MATCH (n1), (n2)
WHERE n1.id <> n2.id
AND apoc.text.levenshteinSimilarity(n1.id, n2.id) > 0.8
RETURN n1.id as entity1, n2.id as entity2,
apoc.text.levenshteinSimilarity(n1.id, n2.id) as similarity
"""
potential_duplicates = graph.query(duplicates_query)
# Procesamiento manual o automático de duplicados
for duplicate in potential_duplicates:
if duplicate['similarity'] > 0.9:
print(f"Posible duplicado: {duplicate['entity1']} - {duplicate['entity2']}")
Esta aproximación nos permite identificar y resolver entidades duplicadas que podrían fragmentar nuestro grafo de conocimiento, manteniendo la coherencia de las relaciones.
El LLMGraphTransformer proporciona una base sólida para construir grafos de conocimiento automatizados, pero su efectividad depende en gran medida de la calidad de los prompts utilizados y la configuración específica para cada dominio de aplicación.
Retrieval navegando relaciones entre entidades
Una vez construido nuestro knowledge graph, podemos aprovechar las relaciones entre entidades para realizar búsquedas más sofisticadas que van más allá de la similaridad semántica tradicional. Este enfoque permite descubrir conexiones implícitas y realizar razonamiento contextual sobre la información almacenada.
Configuración del retriever basado en grafos
Para implementar retrieval navegacional, necesitamos configurar un sistema que pueda traversar las relaciones del grafo mientras mantiene la capacidad de búsqueda semántica:
from langchain_neo4j import Neo4jVector
from langchain_openai import OpenAIEmbeddings
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
# Configuración del vector store híbrido
vector_store = Neo4jVector.from_existing_graph(
embedding=OpenAIEmbeddings(),
graph=graph,
node_label="Document",
text_node_properties=["text"],
embedding_node_property="embedding"
)
# Retriever base para búsqueda semántica
base_retriever = vector_store.as_retriever(search_kwargs={"k": 5})
Esta configuración híbrida combina la búsqueda vectorial tradicional con la capacidad de navegación por el grafo, permitiendo que cada consulta aproveche ambas modalidades de búsqueda.
Implementación de consultas relacionales
El verdadero poder del GraphRAG se manifiesta cuando implementamos consultas que pueden seguir cadenas de relaciones. Veamos cómo crear un retriever que navega por conexiones específicas:
def create_relationship_query(entity_type, relationship, target_type, max_depth=2):
"""Genera consultas Cypher para navegación relacional"""
return f"""
MATCH (start:{entity_type})-[:{relationship}*1..{max_depth}]->(target:{target_type})
WHERE start.id CONTAINS $entity_name
RETURN DISTINCT target.id as related_entity,
target.text as content,
length((start)-[:{relationship}*]->(target)) as distance
ORDER BY distance ASC
LIMIT 10
"""
def relational_retriever(query: str, entity_name: str, relationship_type: str):
"""Retriever que navega relaciones específicas"""
# Búsqueda semántica inicial
semantic_results = base_retriever.invoke(query)
# Navegación relacional
cypher_query = create_relationship_query("Person", relationship_type, "Organization")
relational_results = graph.query(
cypher_query,
params={"entity_name": entity_name}
)
# Combinación de resultados
combined_context = []
# Agregar contexto semántico
for doc in semantic_results:
combined_context.append({
"content": doc.page_content,
"source": "semantic_search",
"metadata": doc.metadata
})
# Agregar contexto relacional
for result in relational_results:
combined_context.append({
"content": result["content"],
"source": "relationship_traversal",
"distance": result["distance"],
"related_entity": result["related_entity"]
})
return combined_context
Consultas multi-hop avanzadas
Para casos más complejos, podemos implementar navegación multi-hop que sigue múltiples tipos de relaciones en secuencia:
def multi_hop_retriever(start_entity: str, path_pattern: list, query: str):
"""
Retriever que sigue patrones de relaciones complejas
path_pattern: [("Person", "WORKS_FOR"), ("Organization", "USES"), ("Technology", "")]
"""
# Construcción dinámica de la consulta Cypher
match_clauses = []
where_clauses = []
return_clauses = []
for i, (node_type, relationship) in enumerate(path_pattern):
if i == 0:
match_clauses.append(f"(n{i}:{node_type})")
where_clauses.append(f"n{i}.id CONTAINS $start_entity")
else:
prev_rel = path_pattern[i-1][1]
match_clauses.append(f"-[:{prev_rel}]->(n{i}:{node_type})")
return_clauses.append(f"n{i}.id as entity_{i}")
return_clauses.append(f"n{i}.text as content_{i}")
cypher_query = f"""
MATCH {' '.join(match_clauses)}
WHERE {' AND '.join(where_clauses)}
RETURN {', '.join(return_clauses)}
LIMIT 5
"""
results = graph.query(cypher_query, params={"start_entity": start_entity})
# Procesamiento de resultados multi-hop
processed_results = []
for result in results:
hop_chain = []
for i in range(len(path_pattern)):
if f"entity_{i}" in result:
hop_chain.append({
"entity": result[f"entity_{i}"],
"content": result[f"content_{i}"],
"hop": i
})
processed_results.append(hop_chain)
return processed_results
Integración con LCEL para retrieval contextual
Podemos integrar nuestro retriever relacional en una cadena LCEL que combine automáticamente búsqueda semántica y navegación de grafos:
from langchain_core.prompts import ChatPromptTemplate
# Template que aprovecha contexto relacional
contextual_prompt = ChatPromptTemplate.from_messages([
("system", """
Responde usando tanto el contexto semántico como las relaciones entre entidades.
Contexto semántico:
{semantic_context}
Relaciones relevantes:
{relational_context}
Considera las conexiones entre entidades para proporcionar una respuesta completa.
"""),
("human", "{question}")
])
def format_relational_context(relational_results):
"""Formatea resultados relacionales para el prompt"""
formatted = []
for result in relational_results:
if result["source"] == "relationship_traversal":
formatted.append(
f"- {result['related_entity']} (distancia: {result['distance']}): {result['content'][:200]}..."
)
return "\n".join(formatted)
def format_semantic_context(semantic_results):
"""Formatea resultados semánticos para el prompt"""
return "\n".join([doc["content"][:300] + "..." for doc in semantic_results])
# Cadena LCEL completa
graph_rag_chain = (
{
"question": RunnablePassthrough(),
"semantic_context": lambda x: format_semantic_context(
relational_retriever(x, "", "")[:3] # Solo contexto semántico
),
"relational_context": lambda x: format_relational_context(
relational_retriever(x, "OpenAI", "COLLABORATES_WITH") # Ejemplo específico
)
}
| contextual_prompt
| llm
| StrOutputParser()
)
Optimización de consultas relacionales
Para mejorar el rendimiento de las consultas relacionales, podemos implementar estrategias de caché y optimización:
from functools import lru_cache
import time
class OptimizedGraphRetriever:
def __init__(self, graph, vector_store, cache_size=128):
self.graph = graph
self.vector_store = vector_store
self.query_cache = {}
self.cache_size = cache_size
@lru_cache(maxsize=128)
def _cached_graph_query(self, query_hash, cypher_query, params_str):
"""Caché para consultas Cypher repetidas"""
params = eval(params_str) # En producción, usar json.loads
return self.graph.query(cypher_query, params=params)
def retrieve_with_relationships(self, query: str, entity_focus: str = None):
"""Retrieval optimizado con navegación relacional"""
# Búsqueda semántica base
semantic_docs = self.vector_store.similarity_search(query, k=3)
# Si hay entidad específica, buscar relaciones
if entity_focus:
relationship_query = """
MATCH (e)-[r]->(related)
WHERE e.id CONTAINS $entity
RETURN type(r) as relationship_type,
related.id as related_entity,
related.text as related_content
ORDER BY related.importance DESC
LIMIT 5
"""
query_hash = hash(f"{relationship_query}_{entity_focus}")
params_str = str({"entity": entity_focus})
related_entities = self._cached_graph_query(
query_hash, relationship_query, params_str
)
# Enriquecimiento del contexto
enriched_context = []
for doc in semantic_docs:
enriched_context.append({
"content": doc.page_content,
"type": "semantic",
"metadata": doc.metadata
})
for rel in related_entities:
enriched_context.append({
"content": rel["related_content"],
"type": "relational",
"relationship": rel["relationship_type"],
"entity": rel["related_entity"]
})
return enriched_context
return [{"content": doc.page_content, "type": "semantic"} for doc in semantic_docs]
Esta implementación optimizada combina caché inteligente con estrategias de enriquecimiento contextual, permitiendo que el sistema escale eficientemente mientras mantiene la riqueza del contexto relacional.
El retrieval navegacional transforma la búsqueda de información de un proceso basado únicamente en similaridad a uno que puede razonar sobre conexiones conceptuales, proporcionando respuestas más completas y contextualmente relevantes.
Fuentes y referencias
Documentación oficial y recursos externos para profundizar en LangChain
Documentación oficial de LangChain
Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, LangChain es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de LangChain
Explora más contenido relacionado con LangChain y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Usar LLMGraphTransformer para extraer entidades y relaciones, construir knowledge graphs desde documentos, realizar búsquedas basadas en grafos, trabajar con Neo4j u otras bases de datos de grafos, y entender cómo los grafos capturan contexto semántico que los embeddings no pueden preservar.