
Embeddings
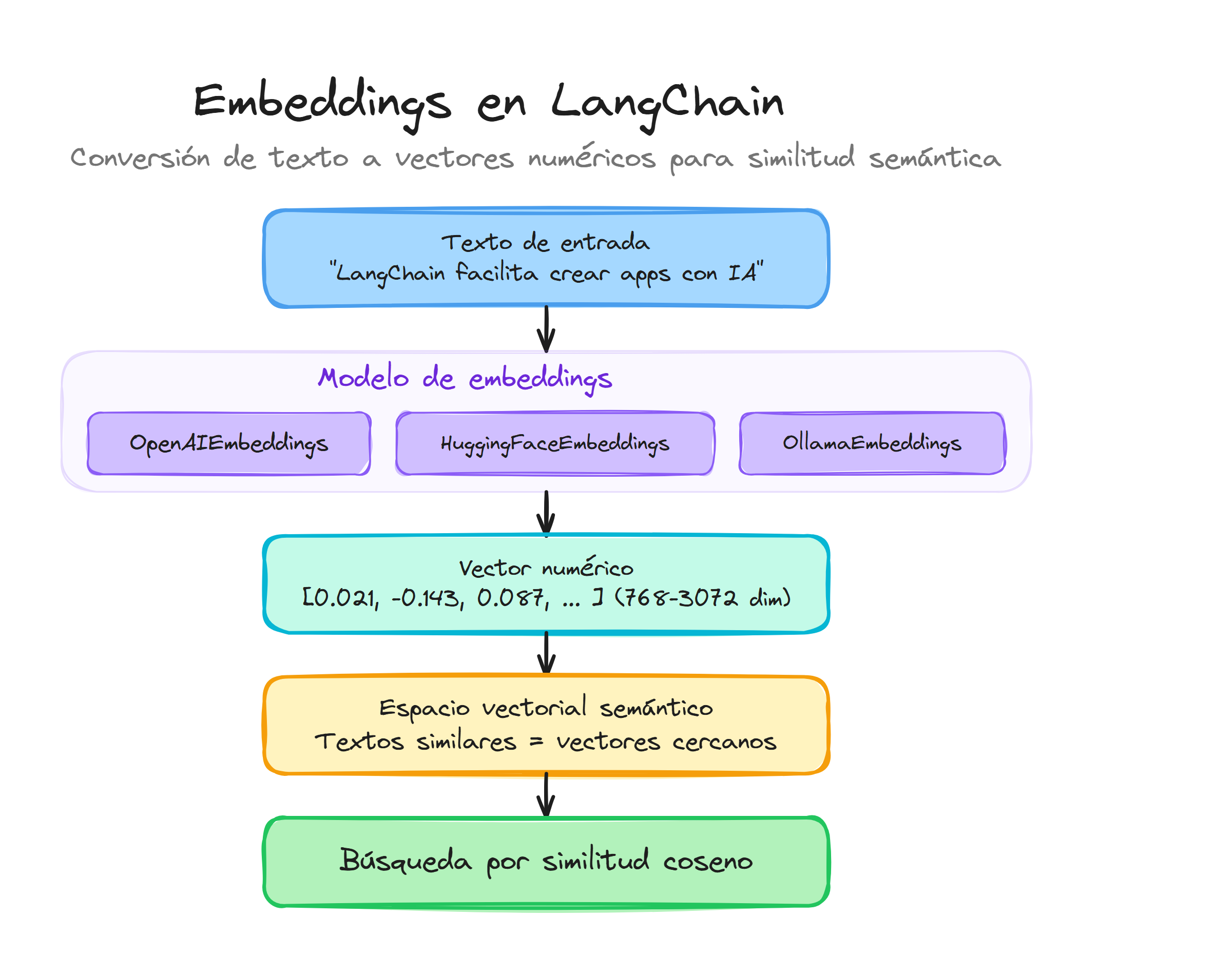
Los embeddings son una forma de convertir palabras o textos en números que un ordenador puede entender y procesar. Imagínate que tienes un diccionario donde cada palabra tiene asignada una serie de números que representan su "significado matemático".
La gracia está en que palabras con significados parecidos tendrán números similares. Por ejemplo, "perro" y "gato" estarían más cerca numéricamente que "perro" y "frigorífico", porque tienen más relación semántica.
En el contexto del RAG, los embeddings son fundamentales porque actúan como el "traductor" entre el lenguaje humano y lo que entiende la máquina. Cuando haces una pregunta, el sistema convierte tu pregunta en embeddings, y luego busca en su base de datos documentos que tengan embeddings similares.
Para obtener embeddings necesitamos un modelo. Podemos usar un modelo de pago como los que ofrece OpenAI, o podemos usar un modelo opensource. A continuación veremos ambas opciones.
OpenAIEmbeddings con text-embedding-3-large
OpenAI proporciona modelos de embeddings especializados que transforman texto en representaciones vectoriales densas de alta calidad. El modelo text-embedding-3-large ofrece una dimensionalidad de 3072 y un rendimiento superior en tareas de búsqueda semántica.
Configuración inicial
Para utilizar OpenAI Embeddings en LangChain, necesitas instalar las dependencias correspondientes y configurar tu clave API:
from langchain_openai import OpenAIEmbeddings
import os
os.environ["OPENAI_API_KEY"] = "tu-clave-api-aquí"
embeddings = OpenAIEmbeddings(
model="text-embedding-3-large"
)
Generación de embeddings para documentos
El método embed_query() está diseñado para generar embeddings de consultas de búsqueda, mientras que embed_documents() procesa listas de documentos:
# Embedding para una consulta
query = "¿Cuáles son los beneficios de la inteligencia artificial?"
query_embedding = embeddings.embed_query(query)
print(f"Dimensiones del embedding: {len(query_embedding)}")
print(f"Primeros 5 valores: {query_embedding[:5]}")
Para procesar múltiples documentos:
documentos = [
"La programación funcional enfatiza el uso de funciones puras.",
"Los algoritmos de machine learning requieren grandes datasets.",
"La ciberseguridad es fundamental en aplicaciones web modernas."
]
doc_embeddings = embeddings.embed_documents(documentos)
print(f"Procesados {len(doc_embeddings)} documentos")
for i, embedding in enumerate(doc_embeddings):
print(f"Documento {i+1}: {len(embedding)} dimensiones")
Configuración avanzada
El modelo text-embedding-3-large permite personalizar varios parámetros:
embeddings_configurado = OpenAIEmbeddings(
model="text-embedding-3-large",
dimensions=1536, # Reducir dimensionalidad para menor costo
chunk_size=1000,
max_retries=3,
request_timeout=60
)
La opción dimensions es útil cuando necesitas equilibrar rendimiento y costo. Reducir las dimensiones de 3072 a 1536 puede disminuir significativamente los costos de almacenamiento manteniendo una calidad aceptable.
Comparación de modelos OpenAI
OpenAI ofrece diferentes modelos de embeddings:
# Modelo más económico
embeddings_small = OpenAIEmbeddings(model="text-embedding-3-small")
# Modelo de alta calidad
embeddings_large = OpenAIEmbeddings(model="text-embedding-3-large")
texto_prueba = "Ejemplo de texto para comparar modelos"
small_embedding = embeddings_small.embed_query(texto_prueba)
large_embedding = embeddings_large.embed_query(texto_prueba)
print(f"text-embedding-3-small: {len(small_embedding)} dimensiones")
print(f"text-embedding-3-large: {len(large_embedding)} dimensiones")
HuggingFaceEmbeddings como alternativa gratuita
Para proyectos con restricciones presupuestarias o que requieren procesamiento completamente local, HuggingFace ofrece una amplia gama de modelos de embeddings gratuitos que pueden ejecutarse sin depender de APIs externas.
Configuración de HuggingFaceEmbeddings
La integración con HuggingFace en LangChain se realiza a través de la clase HuggingFaceEmbeddings:
from langchain_huggingface import HuggingFaceEmbeddings
embeddings_hf = HuggingFaceEmbeddings(
model_name="sentence-transformers/all-mpnet-base-v2"
)
El modelo all-mpnet-base-v2 es una opción equilibrada que ofrece buen rendimiento en tareas de búsqueda semántica con un tamaño razonable.
Uso básico con documentos
Una vez inicializado, el uso es idéntico a OpenAIEmbeddings:
consulta = "¿Cómo implementar autenticación en aplicaciones web?"
embedding_consulta = embeddings_hf.embed_query(consulta)
print(f"Dimensiones del embedding: {len(embedding_consulta)}")
documentos_tecnicos = [
"JWT tokens proporcionan autenticación stateless en APIs REST.",
"OAuth 2.0 es el estándar para autorización en aplicaciones modernas.",
"La autenticación multifactor mejora significativamente la seguridad."
]
embeddings_docs = embeddings_hf.embed_documents(documentos_tecnicos)
print(f"Procesados {len(embeddings_docs)} documentos localmente")
Configuración avanzada y optimización
HuggingFaceEmbeddings permite personalizar varios aspectos del procesamiento:
embeddings_optimizado = HuggingFaceEmbeddings(
model_name="sentence-transformers/all-mpnet-base-v2",
model_kwargs={
'device': 'cpu',
'trust_remote_code': False
},
encode_kwargs={
'normalize_embeddings': True,
'batch_size': 32
}
)
Integración con Ollama para embeddings locales
Para usuarios que prefieren máximo control sobre sus modelos, LangChain también soporta embeddings a través de Ollama:
from langchain_ollama import OllamaEmbeddings
# Requiere tener Ollama instalado y el modelo descargado
embeddings_ollama = OllamaEmbeddings(
model="nomic-embed-text"
)
texto_ejemplo = "Ejemplo de procesamiento local con Ollama"
embedding_local = embeddings_ollama.embed_query(texto_ejemplo)
Los modelos de HuggingFace requieren espacio de almacenamiento local y pueden consumir memoria RAM significativa durante la ejecución. Sin embargo, ofrecen la ventaja de procesamiento completamente offline y sin costes por uso.
Similitud entre embeddings
Para entender cómo funcionan las búsquedas semánticas, es útil calcular la similitud entre vectores directamente. La métrica más utilizada es la similitud del coseno, que mide el ángulo entre dos vectores independientemente de su magnitud:
import numpy as np
def similitud_coseno(vec_a, vec_b):
"""Calcula la similitud del coseno entre dos vectores."""
dot_product = np.dot(vec_a, vec_b)
norm_a = np.linalg.norm(vec_a)
norm_b = np.linalg.norm(vec_b)
return dot_product / (norm_a * norm_b)
# Comparar similitud entre textos relacionados y no relacionados
texto_a = "Python es un lenguaje de programación"
texto_b = "Java es un lenguaje de programación"
texto_c = "La receta de paella lleva arroz y azafrán"
emb_a = embeddings.embed_query(texto_a)
emb_b = embeddings.embed_query(texto_b)
emb_c = embeddings.embed_query(texto_c)
print(f"Python vs Java: {similitud_coseno(emb_a, emb_b):.4f}")
print(f"Python vs Paella: {similitud_coseno(emb_a, emb_c):.4f}")
Los textos semánticamente relacionados producen valores de similitud cercanos a 1.0, mientras que los no relacionados se aproximan a 0. Esta propiedad es la base de toda la búsqueda semántica en sistemas RAG.
En la siguiente lección aprenderemos sobre Vector Stores, que nos permitirán almacenar estos embeddings y realizar búsquedas eficientes por similitud.
Fuentes y referencias
Documentación oficial y recursos externos para profundizar en LangChain
Documentación oficial de LangChain
Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, LangChain es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de LangChain
Explora más contenido relacionado con LangChain y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Comprender qué son los embeddings y su papel en RAG, usar OpenAIEmbeddings con modelos como text-embedding-3-large, trabajar con modelos open-source de HuggingFace, generar embeddings para documentos y consultas, y entender la dimensionalidad y métricas de similitud.
Cursos que incluyen esta lección
Esta lección forma parte de los siguientes cursos estructurados con rutas de aprendizaje