
Clase Document en LangChain
En el ecosistema de LangChain, toda la información textual se estructura utilizando la clase Document, que actúa como el contenedor fundamental para trabajar con textos en aplicaciones de RAG. Esta clase proporciona una interfaz estandarizada que permite a LangChain procesar, indexar y recuperar información de manera consistente, independientemente del origen de los datos.
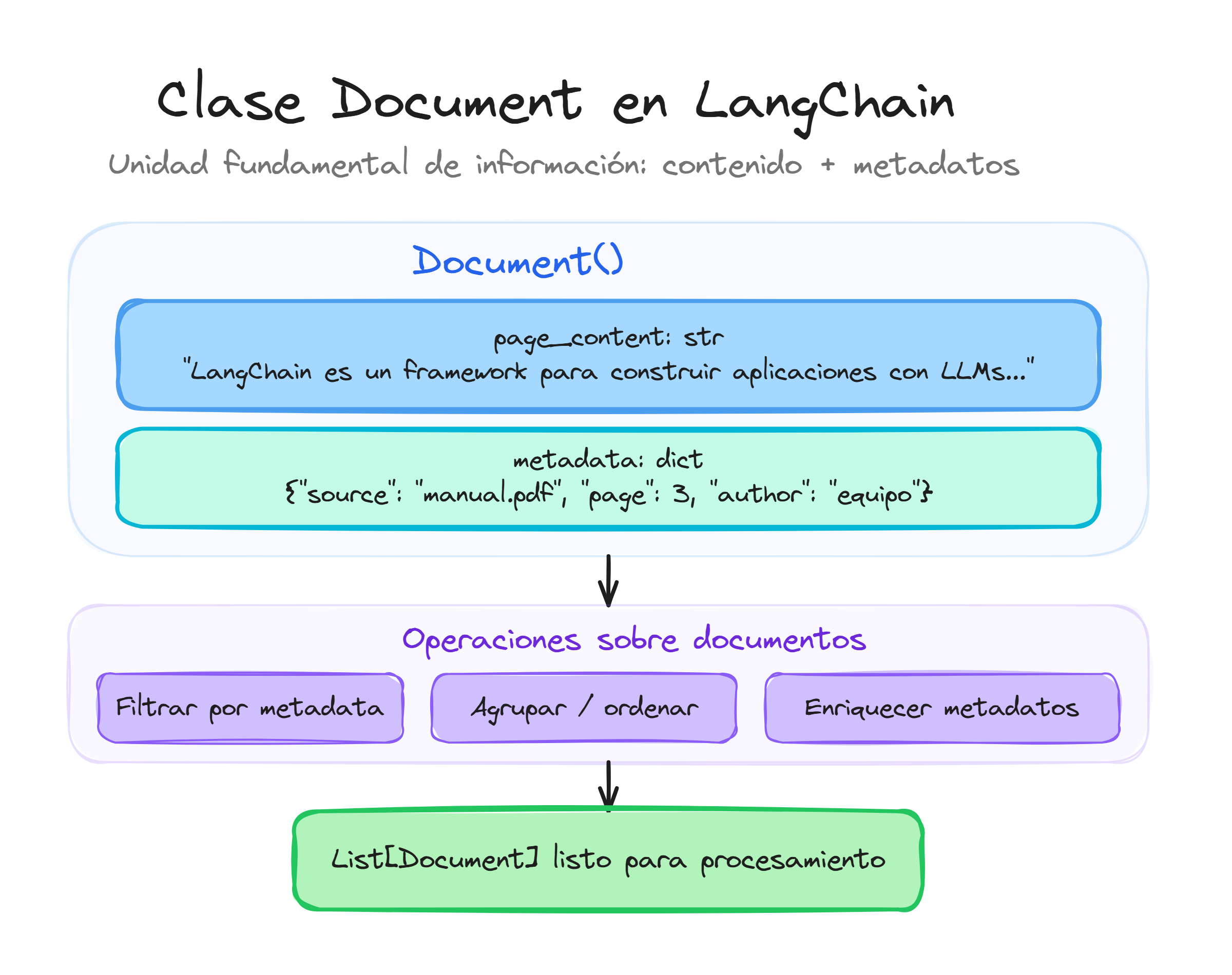
La clase Document se encuentra en el módulo langchain_core.documents y representa la unidad básica de información con la que trabajaremos a lo largo de todo el módulo RAG.
from langchain_core.documents import Document
# Crear un documento básico
documento = Document(
page_content="LangChain es un framework para desarrollar aplicaciones con modelos de lenguaje.",
metadata={"fuente": "documentacion_oficial", "fecha": "2025-01-15"}
)
print(f"Contenido: {documento.page_content}")
print(f"Metadatos: {documento.metadata}")
Estructura interna de Document
La clase Document está diseñada con una arquitectura minimalista pero efectiva. Internamente, mantiene dos atributos principales que definen completamente la información que contiene:
- page_content: El texto principal del documento.
- metadata: Un diccionario con información adicional sobre el documento.
documento = Document(
page_content="Python es un lenguaje de programación versátil.",
metadata={
"autor": "Guido van Rossum",
"año": 1991,
"tipo": "lenguaje_programacion"
}
)
print(f"Tipo de page_content: {type(documento.page_content)}")
print(f"Tipo de metadata: {type(documento.metadata)}")
Creación de documentos desde diferentes fuentes
La flexibilidad de la clase Document permite crear instancias desde múltiples tipos de fuentes de información:
# Documento con contenido mínimo
doc_simple = Document(page_content="Este es un texto de ejemplo.")
# Documento con metadatos básicos
doc_con_metadata = Document(
page_content="Las funciones lambda en Python permiten crear funciones anónimas.",
metadata={"tema": "programacion", "dificultad": "intermedio"}
)
Trabajando con colecciones de documentos
En aplicaciones RAG reales, raramente trabajamos con documentos individuales. La clase Document está optimizada para funcionar eficientemente en colecciones grandes:
documentos_python = [
Document(
page_content="Las listas en Python son estructuras de datos mutables y ordenadas.",
metadata={"tema": "estructuras_datos", "nivel": "basico"}
),
Document(
page_content="Los diccionarios permiten almacenar pares clave-valor de manera eficiente.",
metadata={"tema": "estructuras_datos", "nivel": "basico"}
),
Document(
page_content="Las clases en Python implementan el paradigma de programación orientada a objetos.",
metadata={"tema": "poo", "nivel": "intermedio"}
)
]
# Operaciones sobre la colección
temas_unicos = set(doc.metadata.get("tema") for doc in documentos_python)
documentos_basicos = [doc for doc in documentos_python if doc.metadata.get("nivel") == "basico"]
print(f"Temas encontrados: {temas_unicos}")
print(f"Documentos básicos: {len(documentos_basicos)}")
page_content y metadata
Los dos atributos fundamentales de la clase Document definen completamente la información que contiene cada instancia. El page_content almacena el texto principal que será procesado por los modelos de lenguaje, mientras que metadata proporciona contexto adicional que enriquece la información.
El atributo page_content
El page_content es una cadena de texto que contiene la información principal del documento. Este atributo será directamente procesado por los modelos de lenguaje durante las operaciones de búsqueda y generación de respuestas.
from langchain_core.documents import Document
documento = Document(page_content="Las funciones en Python pueden recibir argumentos por defecto.")
print(f"Contenido: {documento.page_content}")
print(f"Longitud: {len(documento.page_content)} caracteres")
El atributo metadata
Los metadatos proporcionan información contextual sobre el documento que no forma parte del contenido principal pero resulta crucial para el procesamiento inteligente:
documento_completo = Document(
page_content="NumPy es la biblioteca fundamental para computación científica en Python.",
metadata={
"biblioteca": "NumPy",
"categoria": "computacion_cientifica",
"fecha_creacion": "2025-01-15",
"autor": "Equipo NumPy"
}
)
for clave, valor in documento_completo.metadata.items():
print(f" {clave}: {valor}")
Patrones comunes de metadata
Existen patrones establecidos para organizar metadatos que facilitan el procesamiento posterior:
Información de origen:
documento_origen = Document(
page_content="La documentación oficial de Python está disponible en docs.python.org",
metadata={
"fuente": "docs.python.org",
"url": "https://docs.python.org/3/tutorial/",
"fecha_acceso": "2025-01-20",
"idioma": "es"
}
)
Clasificación y categorización:
documento_clasificado = Document(
page_content="Los decoradores en Python permiten modificar el comportamiento de funciones.",
metadata={
"categoria": "programacion",
"subcategoria": "python_avanzado",
"dificultad": "intermedio",
"tiempo_lectura": 5
}
)
Filtrado por metadata
Una de las ventajas principales de mantener metadatos estructurados es la capacidad de filtrar colecciones de documentos de manera eficiente:
documentos_biblioteca = [
Document(
page_content="Requests simplifica las peticiones HTTP en Python.",
metadata={"biblioteca": "Requests", "categoria": "http", "dificultad": "basico"}
),
Document(
page_content="SQLAlchemy es un ORM para bases de datos en Python.",
metadata={"biblioteca": "SQLAlchemy", "categoria": "base_datos", "dificultad": "avanzado"}
),
Document(
page_content="Beautiful Soup facilita el web scraping en Python.",
metadata={"biblioteca": "Beautiful Soup", "categoria": "web_scraping", "dificultad": "intermedio"}
)
]
# Filtrar por dificultad
docs_basicos = [doc for doc in documentos_biblioteca
if doc.metadata.get("dificultad") == "basico"]
print(f"Documentos básicos: {len(docs_basicos)}")
La separación clara entre contenido y metadatos en la clase Document permite construir sistemas RAG sofisticados donde la información contextual juega un papel tan importante como el contenido textual en la recuperación y generación de respuestas precisas.
Serialización y transformaciones
Los objetos Document soportan serialización a formatos estándar, lo que facilita su almacenamiento y transmisión entre componentes del sistema:
from langchain_core.documents import Document
doc = Document(
page_content="FastAPI permite crear APIs REST de alto rendimiento.",
metadata={"framework": "FastAPI", "tipo": "web"}
)
# Convertir a diccionario
doc_dict = doc.dict()
print(f"Diccionario: {doc_dict}")
# Reconstruir desde diccionario
doc_restaurado = Document(**doc_dict)
print(f"Restaurado: {doc_restaurado.page_content}")
Transformación de metadatos
En aplicaciones reales, es habitual enriquecer los metadatos después de cargar los documentos para añadir información útil para el retrieval:
def enriquecer_metadatos(documentos: list, proyecto: str, version: str) -> list:
"""Añade metadatos de proyecto a una lista de documentos."""
for doc in documentos:
doc.metadata["proyecto"] = proyecto
doc.metadata["version"] = version
doc.metadata["longitud"] = len(doc.page_content)
return documentos
docs_enriquecidos = enriquecer_metadatos(documentos_python, "certidevs", "2.0")
Esta capacidad de transformación resulta esencial cuando se combinan documentos de múltiples fuentes en un mismo vector store, ya que los metadatos adicionales permiten filtrar resultados por origen, fecha o cualquier otro criterio relevante.
En la siguiente lección aprenderemos a cargar documentos automáticamente desde archivos utilizando los Document Loaders de LangChain.
Fuentes y referencias
Documentación oficial y recursos externos para profundizar en LangChain
Documentación oficial de LangChain
Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, LangChain es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de LangChain
Explora más contenido relacionado con LangChain y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Comprender la estructura de la clase Document con page_content y metadata, crear documentos manualmente, trabajar con metadatos para rastrear fuentes, y entender cómo Document actúa como unidad básica en el pipeline RAG.
Cursos que incluyen esta lección
Esta lección forma parte de los siguientes cursos estructurados con rutas de aprendizaje