
TextLoader y DirectoryLoader
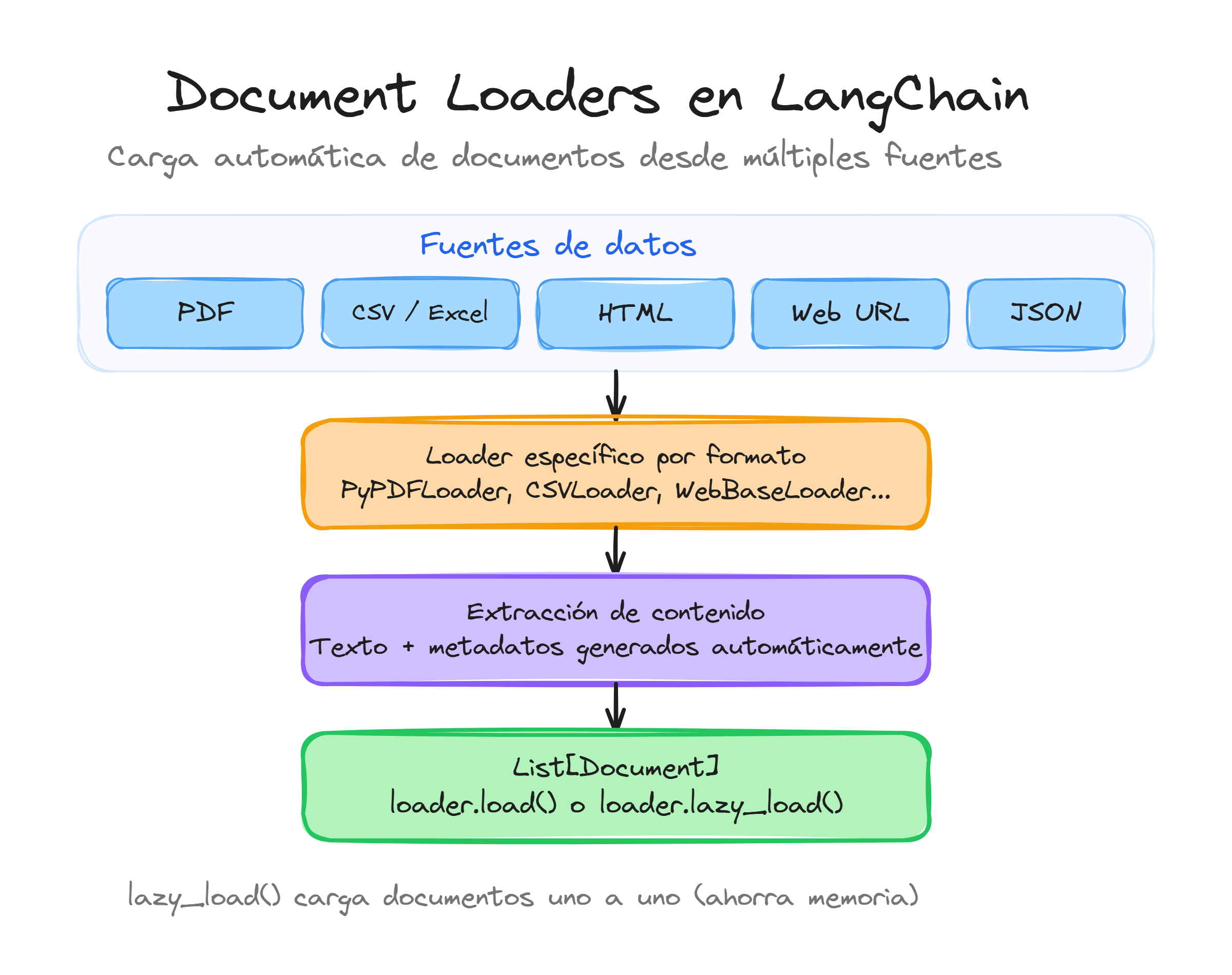
Los document loaders de LangChain automatizan el proceso de carga de documentos desde archivos, eliminando la necesidad de crear objetos Document manualmente. Estos loaders no solo cargan el contenido, sino que también generan automáticamente metadatos útiles como la fuente del archivo, que serán fundamentales para el sistema de retrieval.
TextLoader para archivos individuales
El TextLoader es el loader más básico y se utiliza para cargar archivos de texto plano:
from langchain_community.document_loaders import TextLoader
# Cargar un archivo de texto individual
loader = TextLoader("documentos/manual_usuario.txt")
documents = loader.load()
print(f"Documentos cargados: {len(documents)}")
print(f"Contenido: {documents[0].page_content[:200]}...")
print(f"Metadatos: {documents[0].metadata}")
El TextLoader genera automáticamente metadatos que incluyen la ruta del archivo como fuente. Esto es especialmente útil cuando necesitas rastrear de dónde proviene cada fragmento de información en tu sistema RAG.
Configuración de encoding
Uno de los aspectos importantes del TextLoader es la gestión del encoding, especialmente cuando trabajas con archivos que contienen caracteres especiales:
# Especificar encoding explícitamente
loader = TextLoader(
"documentos/texto_espanol.txt",
encoding="utf-8"
)
documents = loader.load()
# Para archivos con encoding automático
loader = TextLoader(
"documentos/archivo_mixto.txt",
autodetect_encoding=True
)
documents = loader.load()
DirectoryLoader para múltiples archivos
El DirectoryLoader permite cargar múltiples archivos de un directorio de forma eficiente:
from langchain_community.document_loaders import DirectoryLoader
# Cargar todos los archivos .txt de un directorio
loader = DirectoryLoader(
"documentos/",
glob="*.txt",
loader_cls=TextLoader
)
documents = loader.load()
print(f"Total de documentos cargados: {len(documents)}")
for doc in documents:
print(f"Archivo: {doc.metadata['source']}")
Filtrado y patrones específicos
El DirectoryLoader ofrece flexibilidad para cargar solo los archivos que necesitas mediante patrones glob:
# Cargar solo archivos con patrón específico
loader = DirectoryLoader(
"manuales/",
glob="manual_*.txt",
loader_cls=TextLoader
)
documents = loader.load()
# Cargar múltiples tipos de archivo en subdirectorios
loader = DirectoryLoader(
"documentos/",
glob="**/*.txt",
loader_cls=TextLoader,
recursive=True
)
documents = loader.load()
Procesamiento con configuraciones específicas
Puedes pasar argumentos específicos al loader subyacente a través del DirectoryLoader:
# Configurar encoding para todos los archivos
loader = DirectoryLoader(
"documentos/",
glob="*.txt",
loader_cls=TextLoader,
loader_kwargs={"encoding": "utf-8", "autodetect_encoding": True}
)
documents = loader.load()
for doc in documents:
print(f"Fuente: {doc.metadata['source']}")
print(f"Tamaño del contenido: {len(doc.page_content)} caracteres")
Los metadatos generados automáticamente por estos loaders son fundamentales para el funcionamiento del sistema RAG, ya que permiten al usuario final saber exactamente de qué archivo proviene cada respuesta.
PyPDFLoader para PDFs
Los archivos PDF representan uno de los formatos más comunes en aplicaciones empresariales y académicas. El PyPDFLoader de LangChain está específicamente diseñado para extraer texto de documentos PDF y generar metadatos enriquecidos que incluyen información sobre páginas individuales.
Instalación y configuración básica
Antes de utilizar PyPDFLoader, necesitas instalar la dependencia correspondiente:
pip install langchain-community pypdf
Una vez instalado, puedes cargar documentos PDF de forma directa:
from langchain_community.document_loaders import PyPDFLoader
# Cargar un documento PDF
loader = PyPDFLoader("informes/reporte_anual.pdf")
documents = loader.load()
print(f"Páginas extraídas: {len(documents)}")
print(f"Primera página: {documents[0].page_content[:200]}...")
print(f"Metadatos: {documents[0].metadata}")
Metadatos enriquecidos por página
La característica más valiosa del PyPDFLoader es que divide automáticamente el PDF en documentos individuales por página, generando metadatos específicos para cada una:
loader = PyPDFLoader("manuales/manual_tecnico.pdf")
pages = loader.load()
# Examinar metadatos de cada página
for i, page in enumerate(pages[:3]):
print(f"Página {i+1}:")
print(f" Fuente: {page.metadata['source']}")
print(f" Número de página: {page.metadata['page']}")
print(f" Contenido: {page.page_content[:150]}...")
Procesamiento de documentos extensos
Los PDFs empresariales suelen ser extensos, y el PyPDFLoader facilita el manejo eficiente de estos documentos:
loader = PyPDFLoader("documentos/politicas_empresa.pdf")
pages = loader.load()
# Analizar distribución de contenido
total_caracteres = sum(len(page.page_content) for page in pages)
print(f"Total de páginas: {len(pages)}")
print(f"Total de caracteres: {total_caracteres}")
# Encontrar páginas con contenido específico
termino_busqueda = "política de vacaciones"
for page in pages:
if termino_busqueda.lower() in page.page_content.lower():
print(f"Encontrado en página {page.metadata['page']}")
Integración con sistemas RAG
Los metadatos de página son especialmente útiles para sistemas RAG donde necesitas proporcionar referencias precisas:
from langchain_community.document_loaders import PyPDFLoader
def procesar_manual_usuario(ruta_pdf):
"""Procesa un manual de usuario en PDF para sistema RAG"""
loader = PyPDFLoader(ruta_pdf)
pages = loader.load()
# Enriquecer metadatos con información adicional
for page in pages:
page.metadata['tipo_documento'] = 'manual_usuario'
page.metadata['seccion'] = f"Página {page.metadata['page']}"
return pages
manual_pages = procesar_manual_usuario("manuales/manual_software.pdf")
# Filtrar solo páginas con contenido sustancial
contenido_util = [page for page in manual_pages if len(page.page_content.strip()) > 100]
print(f"Páginas de contenido útil: {len(contenido_util)}")
La granularidad por página que proporciona PyPDFLoader es fundamental para crear sistemas RAG precisos, ya que permite a los usuarios obtener referencias exactas sobre dónde se encuentra la información en el documento original.
WebBaseLoader para contenido web
Para aplicaciones RAG que necesitan incorporar contenido de páginas web, LangChain proporciona WebBaseLoader, que descarga y procesa HTML automáticamente:
from langchain_community.document_loaders import WebBaseLoader
import bs4
loader = WebBaseLoader(
web_paths=("https://ejemplo.com/documentacion",),
bs_kwargs={"parse_only": bs4.SoupStrainer(class_="contenido-principal")}
)
web_docs = loader.load()
print(f"Documentos web cargados: {len(web_docs)}")
El parámetro bs_kwargs permite filtrar el HTML usando BeautifulSoup, extrayendo únicamente las secciones relevantes y descartando menús de navegación, barras laterales y otros elementos no informativos.
CSVLoader para datos tabulares
Para cargar datos desde archivos CSV, LangChain proporciona un loader especializado que convierte cada fila en un documento independiente:
from langchain_community.document_loaders import CSVLoader
loader = CSVLoader("datos/productos.csv", encoding="utf-8")
csv_docs = loader.load()
print(f"Filas cargadas: {len(csv_docs)}")
print(f"Primera fila: {csv_docs[0].page_content[:100]}...")
Cada fila del CSV se transforma en un Document cuyo page_content contiene los pares clave-valor de las columnas, lo que facilita su indexación posterior en un vector store.
En la siguiente lección aprenderemos a dividir estos documentos en chunks más pequeños utilizando los Text Splitters de LangChain.
Fuentes y referencias
Documentación oficial y recursos externos para profundizar en LangChain
Documentación oficial de LangChain
Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, LangChain es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de LangChain
Explora más contenido relacionado con LangChain y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Usar TextLoader para archivos individuales, DirectoryLoader para cargar múltiples archivos, trabajar con loaders especializados (PDF, HTML, etc.), entender cómo los loaders generan metadatos automáticamente, y cargar documentos desde URLs y APIs.
Cursos que incluyen esta lección
Esta lección forma parte de los siguientes cursos estructurados con rutas de aprendizaje