
Late interaction con embeddings por token
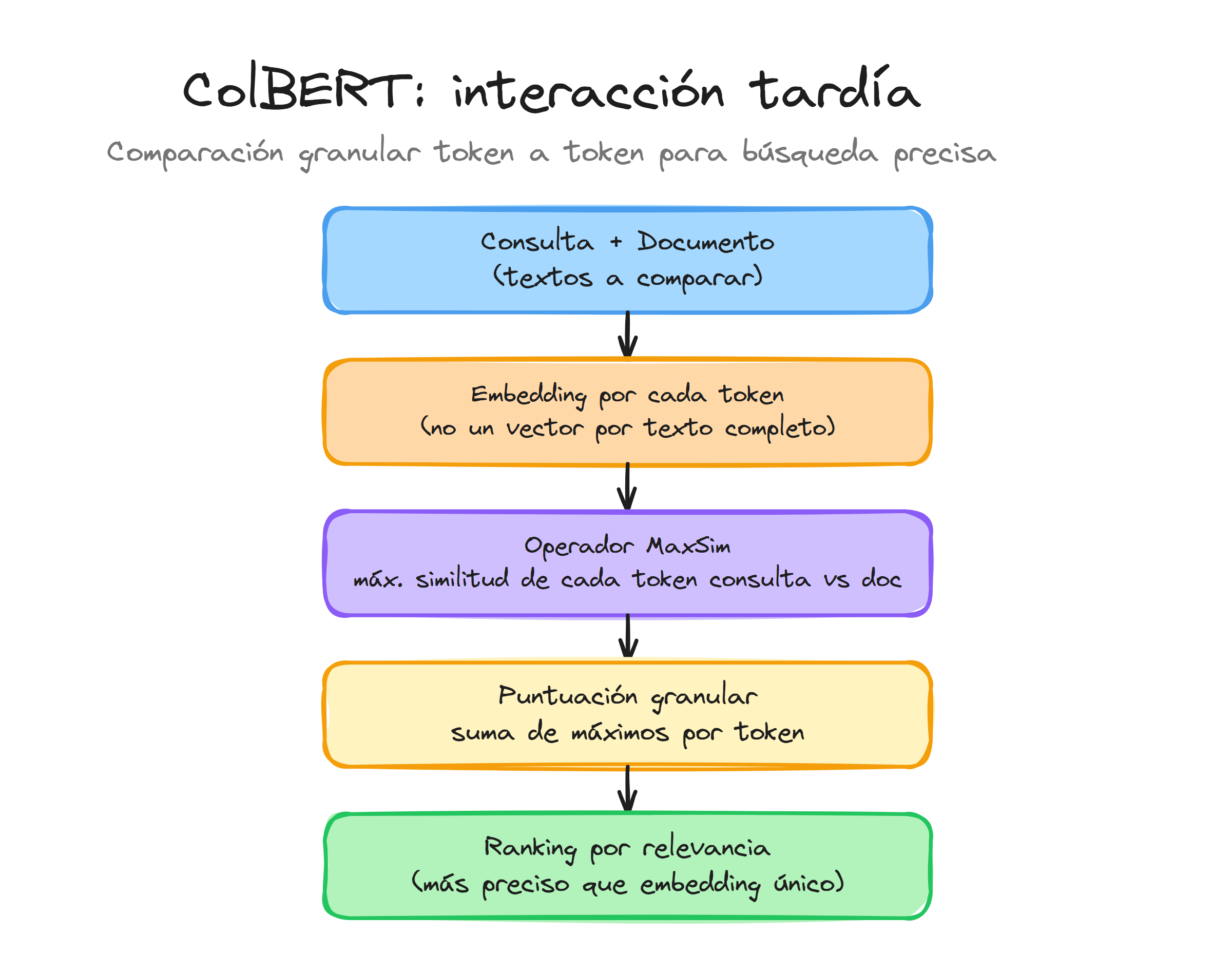
ColBERT representa un cambio fundamental en cómo abordamos la recuperación de información en sistemas RAG. Mientras que los métodos tradicionales generan un único embedding denso por documento completo, ColBERT adopta un enfoque más granular al crear embeddings individuales para cada token del texto.
Arquitectura de embeddings por token
La arquitectura ColBERT se basa en el principio de que cada token individual contiene información semántica específica que puede perderse cuando se comprime todo el documento en un único vector. En lugar de procesar el documento como una unidad monolítica, ColBERT tokeniza el texto y genera un embedding independiente para cada token.
# Conceptualmente, ColBERT transforma esto:
documento = "Python es un lenguaje de programación interpretado"
# En lugar de: [embedding_documento]
# Genera: [embedding_python, embedding_es, embedding_un, embedding_lenguaje, ...]
Esta aproximación permite que el modelo capture matices semánticos específicos de cada palabra en su contexto particular, manteniendo la información posicional y contextual que se perdería en un embedding agregado.
El mecanismo de late interaction
El término "late interaction" describe el momento en que se realiza la comparación entre la consulta y los documentos. En sistemas tradicionales, la interacción ocurre temprano durante la indexación, cuando se genera un embedding único por documento. ColBERT retrasa esta interacción hasta el momento de la búsqueda.
El proceso funciona de la siguiente manera:
1 - Indexación por tokens:
# Durante la indexación, cada documento se procesa token por token
documento = "Machine learning algorithms require large datasets"
tokens_doc = ["machine", "learning", "algorithms", "require", "large", "datasets"]
embeddings_doc = [embed(token) for token in tokens_doc]
2 - Procesamiento de la consulta:
# La consulta también se tokeniza y embebida
query = "machine learning datasets"
tokens_query = ["machine", "learning", "datasets"]
embeddings_query = [embed(token) for token in tokens_query]
3 - Interacción tardía con MaxSim:
El operador MaxSim es el corazón del mecanismo de late interaction. Para cada token de la consulta, encuentra el token del documento con mayor similitud coseno:
# Pseudocódigo del operador MaxSim
def maxsim_score(query_embeddings, doc_embeddings):
total_score = 0
for q_embed in query_embeddings:
max_similarity = 0
for d_embed in doc_embeddings:
similarity = cosine_similarity(q_embed, d_embed)
max_similarity = max(max_similarity, similarity)
total_score += max_similarity
return total_score
Ventajas del matching granular
La aproximación de ColBERT ofrece precisión superior en varios escenarios específicos. El matching a nivel de token permite identificar correspondencias exactas que podrían diluirse en embeddings agregados.
Para nombres propios y terminología técnica, ColBERT mantiene la integridad semántica:
# Ejemplo: búsqueda de "TensorFlow optimization"
# ColBERT puede hacer matching exacto de:
# - "TensorFlow" token vs "TensorFlow" token
# - "optimization" token vs "optimization" token
# Sin que se diluya en el embedding general del documento
El sistema también maneja mejor las consultas multi-aspecto, donde diferentes partes de la consulta pueden corresponder a diferentes secciones del documento:
# Consulta: "Python pandas DataFrame performance"
# Puede hacer matching con un documento que contenga:
# - "Python" en la introducción
# - "pandas DataFrame" en una sección específica
# - "performance" en las conclusiones
Consideraciones de almacenamiento y latencia
El enfoque de ColBERT introduce trade-offs importantes en términos de recursos. Cada documento requiere almacenar múltiples vectores en lugar de uno solo, incrementando significativamente los requisitos de storage.
# Comparación de almacenamiento:
# Método tradicional: 1 documento → 1 vector (ej: 768 dimensiones)
# ColBERT: 1 documento → N vectores (N = número de tokens × 768 dimensiones)
La latencia adicional surge durante la fase de scoring, donde el operador MaxSim debe calcular similitudes entre todos los pares de tokens query-documento. Sin embargo, esta latencia se compensa parcialmente mediante optimizaciones como la cuantización de vectores y técnicas de indexación especializadas.
Contextualización con BERT
ColBERT aprovecha la arquitectura BERT bidireccional para generar embeddings contextualizados. A diferencia de embeddings estáticos como Word2Vec, cada token recibe un embedding que considera todo el contexto circundante.
# El token "bank" tendrá embeddings diferentes según el contexto:
# "river bank" → embedding contextualizado hacia geografía
# "bank account" → embedding contextualizado hacia finanzas
Esta contextualización permite que ColBERT capture ambigüedades semánticas y genere representaciones más precisas para cada token en su contexto específico, mejorando la calidad del matching durante la recuperación.
RAGatouille para ColBERT en LangChain
RAGatouille es la librería que facilita la integración de ColBERT con LangChain, proporcionando una interfaz simplificada para aprovechar las capacidades de late interaction sin necesidad de implementar la arquitectura desde cero. Esta librería abstrae la complejidad del modelo ColBERT y ofrece componentes compatibles con el ecosistema LCEL.
Instalación y configuración inicial
Para comenzar a trabajar con RAGatouille, necesitas instalar la librería junto con sus dependencias:
pip install ragatouille langchain langchain-openai
La configuración básica requiere cargar el modelo preentrenado de ColBERT:
from ragatouille import RAGPretrainedModel
from langchain_openai import ChatOpenAI
from langchain_core.documents import Document
# Cargar el modelo ColBERT preentrenado
RAG = RAGPretrainedModel.from_pretrained("colbert-ir/colbertv2.0")
# Configurar el modelo de chat
llm = ChatOpenAI(model="gpt-5.4", temperature=0)
El modelo colbert-ir/colbertv2.0 es la versión estable más reciente que incluye optimizaciones de rendimiento y mejor compatibilidad con textos en múltiples idiomas.
Indexación de documentos
RAGatouille maneja automáticamente el proceso de tokenización y embedding por cada token. El proceso de indexación difiere significativamente de los vectorstores tradicionales:
# Preparar documentos de ejemplo
documentos = [
"Python es un lenguaje de programación interpretado y de alto nivel",
"LangChain facilita el desarrollo de aplicaciones con modelos de lenguaje",
"ColBERT mejora la precisión del retrieval mediante late interaction",
"Los embeddings por token permiten matching más granular"
]
# Crear índice ColBERT
RAG.index(
collection=documentos,
index_name="mi_coleccion_colbert",
max_document_length=256, # Longitud máxima por documento
split_documents=True # División automática de documentos largos
)
Durante la indexación, RAGatouille procesa cada documento token por token, generando los embeddings contextualizados que posteriormente utilizará el operador MaxSim.
Integración como retriever en LCEL
RAGatouille se integra perfectamente con LangChain Expression Language mediante el método as_langchain_retriever():
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
# Configurar el retriever ColBERT
retriever = RAG.as_langchain_retriever(k=3)
# Crear prompt template
prompt = ChatPromptTemplate.from_template("""
Responde la pregunta basándote únicamente en el siguiente contexto:
{context}
Pregunta: {question}
Respuesta:
""")
# Construir cadena LCEL
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
# Ejecutar consulta
resultado = chain.invoke("¿Qué ventajas ofrece ColBERT?")
print(resultado)
Uso como document compressor
Una aplicación particularmente útil de RAGatouille es como reranker para mejorar los resultados de otros retrievers:
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
from langchain_core.retrievers import BaseRetriever
# Crear vectorstore tradicional como retriever inicial
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_texts(documentos, embeddings)
base_retriever = vectorstore.as_retriever(search_kwargs={"k": 10})
# Configurar ColBERT como compressor/reranker
colbert_compressor = RAG.as_langchain_document_compressor(k=3)
# Crear retriever híbrido
from langchain.retrievers import ContextualCompressionRetriever
hybrid_retriever = ContextualCompressionRetriever(
base_compressor=colbert_compressor,
base_retriever=base_retriever
)
# Usar en cadena LCEL
chain = (
{"context": hybrid_retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
Configuración avanzada de parámetros
RAGatouille permite ajustar varios parámetros de rendimiento para optimizar el comportamiento según tus necesidades específicas:
# Configuración avanzada del retriever
retriever_avanzado = RAG.as_langchain_retriever(
k=5, # Número de documentos a recuperar
return_documents=True, # Retornar objetos Document completos
include_metadata=True # Incluir metadatos en los resultados
)
# Configuración del compressor con parámetros específicos
compressor_avanzado = RAG.as_langchain_document_compressor(
k=3,
similarity_threshold=0.7, # Umbral mínimo de similitud
diversity_bias=0.3 # Balance entre relevancia y diversidad
)
Manejo de metadatos y filtrado
RAGatouille preserva los metadatos de los documentos originales, permitiendo filtrado y enriquecimiento de resultados:
# Documentos con metadatos
docs_con_metadata = [
Document(
page_content="Python es un lenguaje interpretado",
metadata={"categoria": "programacion", "nivel": "basico"}
),
Document(
page_content="ColBERT mejora el retrieval",
metadata={"categoria": "ia", "nivel": "avanzado"}
)
]
# Indexar con metadatos
RAG.index(
collection=[doc.page_content for doc in docs_con_metadata],
document_metadatas=[doc.metadata for doc in docs_con_metadata],
index_name="coleccion_con_metadata"
)
# Los metadatos se mantienen en los resultados del retriever
resultados = retriever.invoke("¿Qué es Python?")
for doc in resultados:
print(f"Contenido: {doc.page_content}")
print(f"Metadatos: {doc.metadata}")
Optimización de memoria y rendimiento
Para colecciones grandes, RAGatouille ofrece opciones de optimización que reducen el uso de memoria sin comprometer significativamente la precisión:
# Configuración optimizada para grandes volúmenes
RAG_optimizado = RAGPretrainedModel.from_pretrained(
"colbert-ir/colbertv2.0",
verbose=1,
n_gpu=1 if torch.cuda.is_available() else 0
)
# Indexación con compresión
RAG_optimizado.index(
collection=documentos,
index_name="coleccion_optimizada",
max_document_length=180,
use_faiss=True, # Usar FAISS para indexación eficiente
overwrite=True # Sobrescribir índice existente
)
Esta configuración es especialmente útil cuando trabajas con miles de documentos y necesitas mantener tiempos de respuesta razonables sin sacrificar la calidad del matching granular que caracteriza a ColBERT.
Fuentes y referencias
Documentación oficial y recursos externos para profundizar en LangChain
Documentación oficial de LangChain
Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, LangChain es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de LangChain
Explora más contenido relacionado con LangChain y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Comprender arquitectura de embeddings por token en ColBERT, implementar late interaction para matching granular, trabajar con embeddings individuales por token, entender ventajas sobre embeddings densos tradicionales, y aplicar técnicas avanzadas de retrieval con ColBERT.