
HTMLHeaderTextSplitter y MarkdownHeaderTextSplitter
Cuando trabajamos con documentos que tienen una estructura jerárquica bien definida, como páginas web HTML o documentación en Markdown, podemos aprovechar esta organización para crear chunks más inteligentes. Los splitters especializados HTMLHeaderTextSplitter y MarkdownHeaderTextSplitter preservan la información contextual de los encabezados.
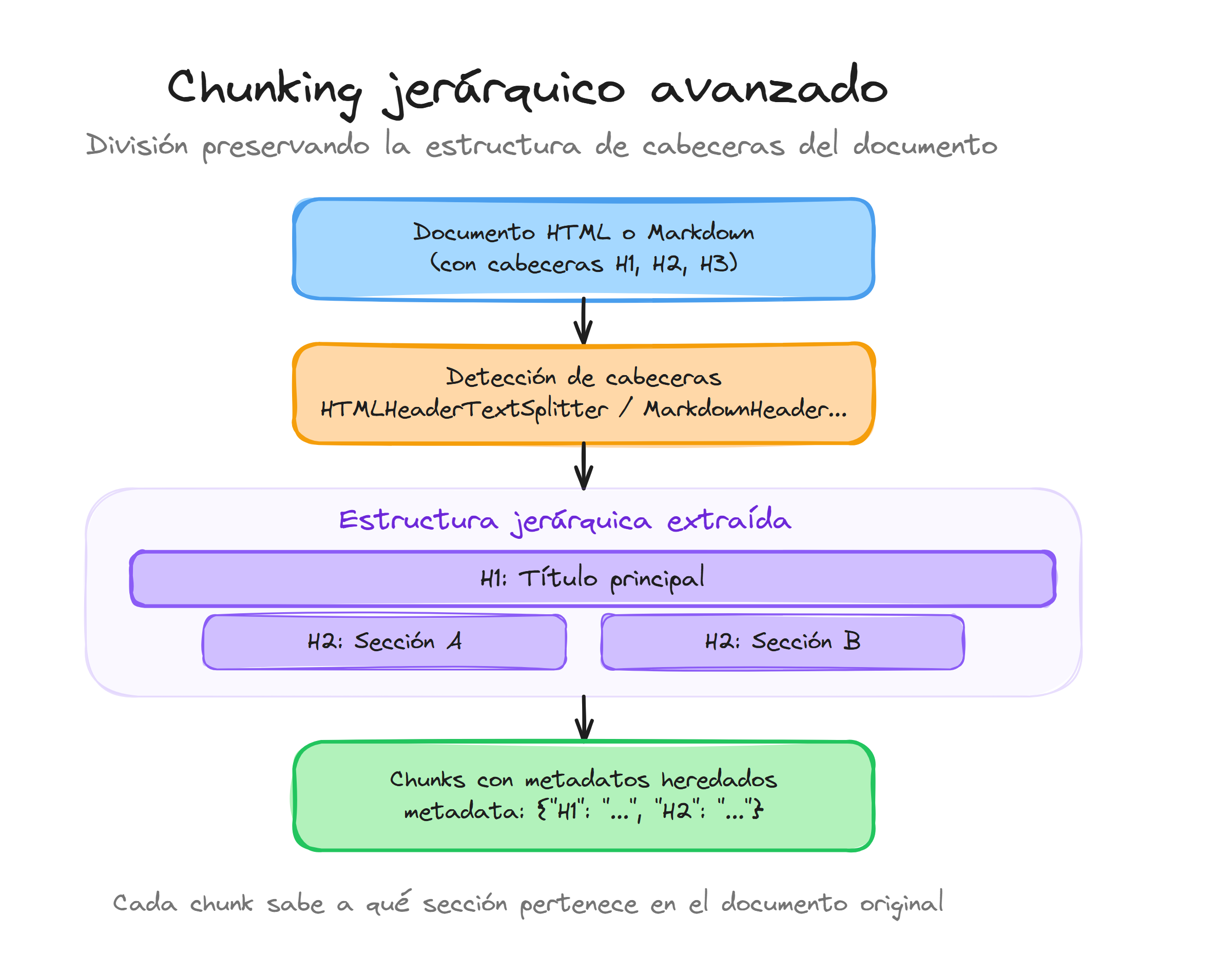
Preservando la estructura con HTMLHeaderTextSplitter
El HTMLHeaderTextSplitter analiza documentos HTML y utiliza las etiquetas de encabezado (<h1>, <h2>, <h3>, etc.) como puntos de división natural:
from langchain_text_splitters import HTMLHeaderTextSplitter
# Definir qué encabezados usar como separadores
headers_to_split_on = [
("h1", "Header 1"),
("h2", "Header 2"),
("h3", "Header 3"),
]
html_splitter = HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
html_content = """
<html>
<body>
<h1>Introducción a Machine Learning</h1>
<p>El machine learning es una rama de la inteligencia artificial...</p>
<h2>Algoritmos Supervisados</h2>
<p>Los algoritmos supervisados aprenden de datos etiquetados...</p>
<h3>Regresión Lineal</h3>
<p>La regresión lineal es uno de los algoritmos más básicos...</p>
<h2>Algoritmos No Supervisados</h2>
<p>Estos algoritmos trabajan con datos sin etiquetas...</p>
</body>
</html>
"""
html_chunks = html_splitter.split_text(html_content)
for i, chunk in enumerate(html_chunks):
print(f"Chunk {i + 1}:")
print(f"Contenido: {chunk.page_content}")
print(f"Metadatos: {chunk.metadata}")
print("-" * 50)
Cada chunk resultante incluye metadatos estructurados que indican su posición en la jerarquía del documento.
Trabajando con documentación Markdown
El MarkdownHeaderTextSplitter funciona de manera similar pero está optimizado para documentos Markdown, reconociendo la sintaxis de encabezados (#, ##, ###, etc.):
from langchain_text_splitters import MarkdownHeaderTextSplitter
markdown_headers = [
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3"),
]
markdown_splitter = MarkdownHeaderTextSplitter(
headers_to_split_on=markdown_headers,
strip_headers=False
)
markdown_content = """
# API de Autenticación
Esta API proporciona endpoints para la autenticación de usuarios.
## Endpoints Disponibles
La API incluye los siguientes endpoints principales.
### POST /auth/login
Autentica un usuario con credenciales.
**Parámetros:**
- username: Nombre de usuario
- password: Contraseña
### POST /auth/refresh
Renueva un token de acceso existente.
## Códigos de Error
La API utiliza códigos de estado HTTP estándar.
"""
markdown_chunks = markdown_splitter.split_text(markdown_content)
for i, chunk in enumerate(markdown_chunks):
print(f"Chunk {i + 1}:")
print(f"Contenido: {chunk.page_content[:100]}...")
print(f"Metadatos: {chunk.metadata}")
Combinando splitters para documentos complejos
En muchos casos reales, necesitamos combinar múltiples estrategias de splitting:
from langchain_text_splitters import (
MarkdownHeaderTextSplitter,
RecursiveCharacterTextSplitter
)
# Primer paso: dividir por encabezados
markdown_splitter = MarkdownHeaderTextSplitter(
headers_to_split_on=[
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3"),
]
)
# Segundo paso: controlar el tamaño de chunks
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=50
)
# Aplicar splitting en dos fases
header_chunks = markdown_splitter.split_text(markdown_content)
final_chunks = []
for chunk in header_chunks:
if len(chunk.page_content) > 500:
sub_chunks = text_splitter.split_documents([chunk])
final_chunks.extend(sub_chunks)
else:
final_chunks.append(chunk)
print(f"Chunks finales generados: {len(final_chunks)}")
Configuración avanzada de separadores
Más allá de los separadores predeterminados, RecursiveCharacterTextSplitter ofrece configuraciones avanzadas que permiten adaptar el comportamiento de división a las características específicas de diferentes tipos de contenido.
Separadores personalizados por tipo de contenido
El comportamiento por defecto utiliza una jerarquía de separadores que funciona bien para texto general, pero podemos definir separadores específicos:
from langchain_text_splitters import RecursiveCharacterTextSplitter
# Separadores optimizados para documentación técnica
technical_separators = [
"\n\n",
"\n### ",
"\n## ",
"\n# ",
"\n```\n",
"\n---\n",
"\n",
". ",
" ",
""
]
tech_splitter = RecursiveCharacterTextSplitter(
separators=technical_separators,
chunk_size=800,
chunk_overlap=100
)
Separadores para código fuente
Para código fuente, podemos definir separadores que respeten la estructura del lenguaje:
# Separadores para código Python
python_separators = [
"\n\nclass ",
"\n\ndef ",
"\n\n```",
"\n```\n",
"\n\n",
"\n",
" ",
""
]
code_splitter = RecursiveCharacterTextSplitter(
separators=python_separators,
chunk_size=1000,
chunk_overlap=100
)
Configuración adaptativa según el contenido
Para sistemas RAG que procesan múltiples tipos de documentos, podemos implementar una estrategia adaptativa:
def create_adaptive_splitter(content: str) -> RecursiveCharacterTextSplitter:
"""Crea un splitter adaptado al tipo de contenido"""
has_code = '```' in content or 'def ' in content
has_markdown = content.count('#') > 2
if has_code:
separators = ["\n\nclass ", "\n\ndef ", "\n\n", "\n", " ", ""]
chunk_size = 1000
overlap = 100
elif has_markdown:
separators = ["\n## ", "\n### ", "\n\n", "\n", ". ", " ", ""]
chunk_size = 800
overlap = 80
else:
separators = ["\n\n", "\n", ". ", " ", ""]
chunk_size = 700
overlap = 70
return RecursiveCharacterTextSplitter(
separators=separators,
chunk_size=chunk_size,
chunk_overlap=overlap
)
# Uso del splitter adaptativo
adaptive_splitter = create_adaptive_splitter(markdown_content)
adaptive_chunks = adaptive_splitter.split_text(markdown_content)
Esta aproximación estructural al chunking es especialmente valiosa cuando trabajamos con documentación técnica, manuales de usuario, artículos académicos o cualquier contenido que siga una jerarquía clara.
Recomendaciones prácticas para chunking
La elección de la estrategia de chunking tiene un impacto directo en la calidad de los resultados del sistema RAG. A continuación se presentan guías prácticas según el tipo de contenido:
Estrategia por tipo de documento
- Documentación técnica (Markdown/HTML): Usar
MarkdownHeaderTextSplitteroHTMLHeaderTextSplittercomo primera fase, seguido deRecursiveCharacterTextSplitterpara controlar el tamaño final. - Documentos de texto plano: Aplicar directamente
RecursiveCharacterTextSplittercon separadores por defecto. - Código fuente: Utilizar separadores específicos del lenguaje que respeten las fronteras de funciones y clases.
- PDFs extensos: Combinar la carga por páginas de
PyPDFLoadercon splitting posterior para fragmentos uniformes.
Verificación de la calidad del chunking
Antes de indexar los chunks en un vector store, es recomendable verificar que la distribución de tamaños es adecuada:
def analizar_chunks(chunks):
"""Analiza la distribución de tamaños de los chunks generados."""
longitudes = [len(chunk.page_content) for chunk in chunks]
print(f"Total de chunks: {len(longitudes)}")
print(f"Tamaño medio: {sum(longitudes) / len(longitudes):.0f} caracteres")
print(f"Tamaño mínimo: {min(longitudes)} caracteres")
print(f"Tamaño máximo: {max(longitudes)} caracteres")
analizar_chunks(final_chunks)
Un buen chunking produce fragmentos de tamaño relativamente uniforme, con suficiente contenido para ser informativos pero no tan extensos que diluyan la relevancia en las búsquedas por similitud.
En la siguiente lección aprenderemos sobre embeddings, que nos permitirán convertir estos chunks de texto en representaciones vectoriales para realizar búsquedas semánticas.
Fuentes y referencias
Documentación oficial y recursos externos para profundizar en LangChain
Documentación oficial de LangChain
Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, LangChain es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de LangChain
Explora más contenido relacionado con LangChain y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Usar HTMLHeaderTextSplitter para documentos HTML preservando estructura de encabezados, trabajar con MarkdownHeaderTextSplitter para documentación Markdown, entender cómo preservar contexto jerárquico, y aplicar estrategias de chunking inteligentes según el tipo de documento.
Cursos que incluyen esta lección
Esta lección forma parte de los siguientes cursos estructurados con rutas de aprendizaje