
Uso de trim_messages
Cuando trabajamos con conversaciones largas en LangChain, uno de los principales desafíos es gestionar el límite de tokens que pueden procesar los modelos de lenguaje. Cada modelo tiene una ventana de contexto limitada, y si nuestros mensajes exceden este límite, obtendremos errores o comportamientos inesperados.
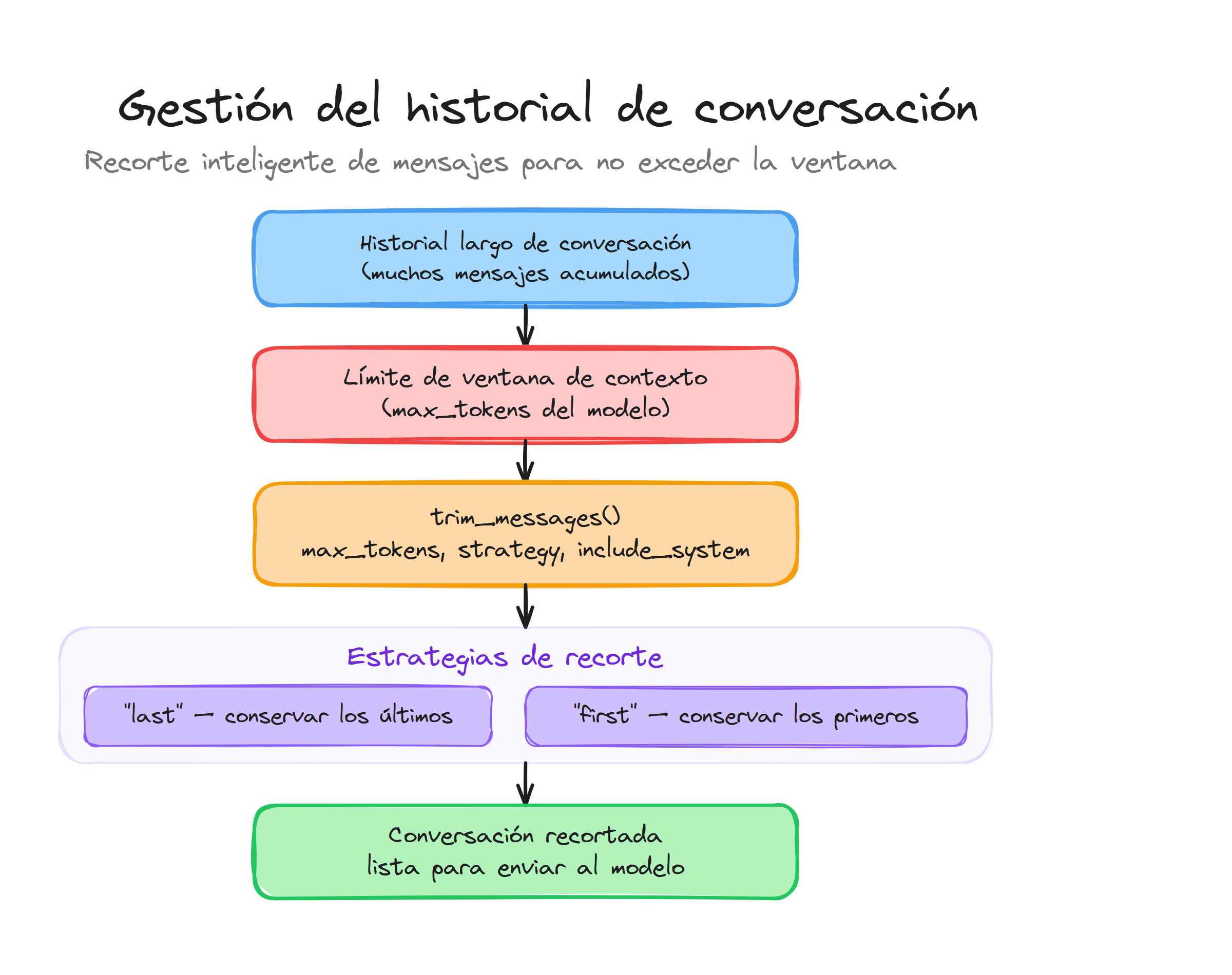
La función trim_messages nos proporciona una solución elegante para recortar automáticamente los mensajes de una conversación, manteniendo solo los más relevantes según diferentes estrategias.
Configuración básica de trim_messages
Para utilizar trim_messages, primero necesitamos importarla y configurar sus parámetros principales:
from langchain_core.messages.utils import trim_messages, count_tokens_approximately
from langchain_core.messages import SystemMessage, HumanMessage, AIMessage
from langchain.chat_models import init_chat_model
model = init_chat_model("gpt-5.4")
# Crear el trimmer con configuración básica
trimmer = trim_messages(
max_tokens=100,
strategy="last",
token_counter=count_tokens_approximately,
include_system=True
)
El parámetro max_tokens define el límite máximo de tokens que queremos mantener. La strategy determina qué mensajes conservar cuando necesitamos recortar, y token_counter especifica la función para contar tokens.
Estrategias de recorte
LangChain ofrece diferentes estrategias de recorte para adaptarse a distintos casos de uso:
Estrategia "last": Mantiene los mensajes más recientes:
from langchain_core.messages.utils import trim_messages, count_tokens_approximately
trimmer_last = trim_messages(
max_tokens=80,
strategy="last",
token_counter=count_tokens_approximately,
include_system=True
)
messages = [
SystemMessage(content="Eres un asistente útil especializado en matemáticas"),
HumanMessage(content="Hola, soy María"),
AIMessage(content="¡Hola María! ¿En qué puedo ayudarte hoy?"),
HumanMessage(content="¿Cuánto es 15 + 27?"),
AIMessage(content="15 + 27 = 42"),
HumanMessage(content="¿Y 42 dividido entre 6?"),
AIMessage(content="42 / 6 = 7"),
HumanMessage(content="Perfecto, gracias por tu ayuda")
]
trimmed_messages = trimmer_last.invoke(messages)
print(f"Mensajes originales: {len(messages)}")
print(f"Mensajes después del recorte: {len(trimmed_messages)}")
Estrategia "first": Mantiene los mensajes más antiguos:
trimmer_first = trim_messages(
max_tokens=80,
strategy="first",
token_counter=count_tokens_approximately,
include_system=True
)
trimmed_first = trimmer_first.invoke(messages)
Parámetros avanzados de configuración
La función trim_messages incluye varios parámetros para personalizar el comportamiento:
Control de mensajes del sistema:
# Siempre incluir el mensaje del sistema
trimmer_with_system = trim_messages(
max_tokens=60,
strategy="last",
token_counter=count_tokens_approximately,
include_system=True # El SystemMessage siempre se mantiene
)
# Excluir el mensaje del sistema del recorte
trimmer_without_system = trim_messages(
max_tokens=60,
strategy="last",
token_counter=count_tokens_approximately,
include_system=False # El SystemMessage puede ser recortado
)
Configuración de punto de inicio:
# Comenzar el recorte desde mensajes humanos
trimmer_start_human = trim_messages(
max_tokens=70,
strategy="last",
token_counter=count_tokens_approximately,
start_on="human" # Asegura que el primer mensaje sea de tipo HumanMessage
)
Integración con cadenas LCEL
Una de las ventajas principales de trim_messages es su integración perfecta con las cadenas LCEL:
from langchain_core.output_parsers import StrOutputParser
from langchain_core.messages.utils import trim_messages, count_tokens_approximately
model = init_chat_model("gpt-5.4")
# Cadena que incluye recorte automático
chain = (
trim_messages(
max_tokens=150,
strategy="last",
token_counter=count_tokens_approximately,
include_system=True,
start_on="human"
)
| model
| StrOutputParser()
)
conversation = [
SystemMessage(content="Eres un experto en programación Python"),
HumanMessage(content="¿Qué es una lista en Python?"),
AIMessage(content="Una lista es una estructura de datos mutable"),
HumanMessage(content="¿Cómo agrego elementos?"),
AIMessage(content="Puedes usar el método append()"),
HumanMessage(content="Dame un ejemplo práctico de uso de listas")
]
# La cadena automáticamente recorta los mensajes antes de enviarlos al modelo
response = chain.invoke(conversation)
print(response)
Uso con contador de tokens del modelo
Para un conteo de tokens más preciso, puedes utilizar directamente el modelo como contador:
model = init_chat_model("gpt-5.4")
trimmer = trim_messages(
max_tokens=100,
strategy="last",
token_counter=model, # Usa el tokenizador del modelo
include_system=True
)
Manejo de mensajes parciales
El parámetro allow_partial controla si permitimos que los mensajes se corten parcialmente:
# No permitir mensajes parciales (comportamiento por defecto)
trimmer_no_partial = trim_messages(
max_tokens=50,
strategy="last",
token_counter=count_tokens_approximately,
allow_partial=False # Si un mensaje no cabe completo, se excluye
)
# Permitir mensajes parciales
trimmer_partial = trim_messages(
max_tokens=50,
strategy="last",
token_counter=count_tokens_approximately,
allow_partial=True # Los mensajes pueden cortarse para ajustarse al límite
)
Monitoreo del recorte
Para supervisar el comportamiento del recorte, puedes implementar un sistema de logging:
def log_trimming(original_messages, trimmed_messages):
"""Función para registrar información sobre el recorte"""
original_count = len(original_messages)
trimmed_count = len(trimmed_messages)
if original_count > trimmed_count:
removed_count = original_count - trimmed_count
print(f"Recorte aplicado: {removed_count} mensajes eliminados")
print(f"Mensajes: {original_count} -> {trimmed_count}")
else:
print("No se requirió recorte")
messages = [
SystemMessage(content="Eres un asistente útil"),
HumanMessage(content="Hola"),
AIMessage(content="¡Hola! ¿Cómo puedo ayudarte?"),
HumanMessage(content="¿Qué tiempo hace?"),
AIMessage(content="No tengo acceso a información meteorológica"),
HumanMessage(content="Entiendo, gracias")
]
trimmer = trim_messages(
max_tokens=40,
strategy="last",
token_counter=count_tokens_approximately,
include_system=True
)
trimmed = trimmer.invoke(messages)
log_trimming(messages, trimmed)
Esta funcionalidad de recorte automático es especialmente útil en aplicaciones de chat donde las conversaciones pueden extenderse indefinidamente, permitiendo mantener un rendimiento óptimo sin perder el contexto más relevante de la interacción.
Estrategias según el caso de uso
La elección de la estrategia de recorte y sus parámetros depende directamente del tipo de aplicación que estemos construyendo:
- Chatbots de atención al cliente: Estrategia
"last"coninclude_system=Trueystart_on="human". Prioriza el contexto reciente porque las consultas suelen ser independientes entre sí. - Asistentes de análisis documental: Estrategia
"last"con unmax_tokenselevado para mantener la mayor cantidad de contexto posible del documento analizado. - Tutores educativos: Estrategia
"last"conallow_partial=Falsepara garantizar que las explicaciones previas se conserven íntegramente o se eliminen por completo.
# Configuración para un chatbot de atención al cliente
trimmer_soporte = trim_messages(
max_tokens=200,
strategy="last",
token_counter=count_tokens_approximately,
include_system=True,
start_on="human",
allow_partial=False
)
La función trim_messages es la solución recomendada para gestionar conversaciones que exceden la ventana de contexto del modelo. Para escenarios más avanzados que requieren persistencia de estado entre sesiones, la gestión de memoria se traslada al sistema de checkpointers del módulo de agentes.
Fuentes y referencias
Documentación oficial y recursos externos para profundizar en LangChain
Documentación oficial de LangChain
Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, LangChain es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de LangChain
Explora más contenido relacionado con LangChain y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Usar trim_messages para gestionar conversaciones largas, aplicar estrategias de recorte (last, first), configurar límites de tokens y contadores, integrar trim_messages con cadenas LCEL, y manejar mensajes parciales y del sistema.
Cursos que incluyen esta lección
Esta lección forma parte de los siguientes cursos estructurados con rutas de aprendizaje