
Visión general del proyecto
En este capstone construiremos un Asistente de Investigación Personal que integra todos los conceptos aprendidos durante el curso. Este agente combina búsqueda semántica en documentos propios mediante RAG, búsqueda web en tiempo real con Tavily, y memoria persistente para mantener el contexto de conversación y recordar preferencias del usuario.
El asistente permite al usuario cargar documentos de referencia, hacer preguntas sobre ellos, complementar la información con búsquedas web actualizadas, y guardar notas importantes para consultas futuras. Todo esto mientras muestra el progreso en tiempo real mediante streaming.
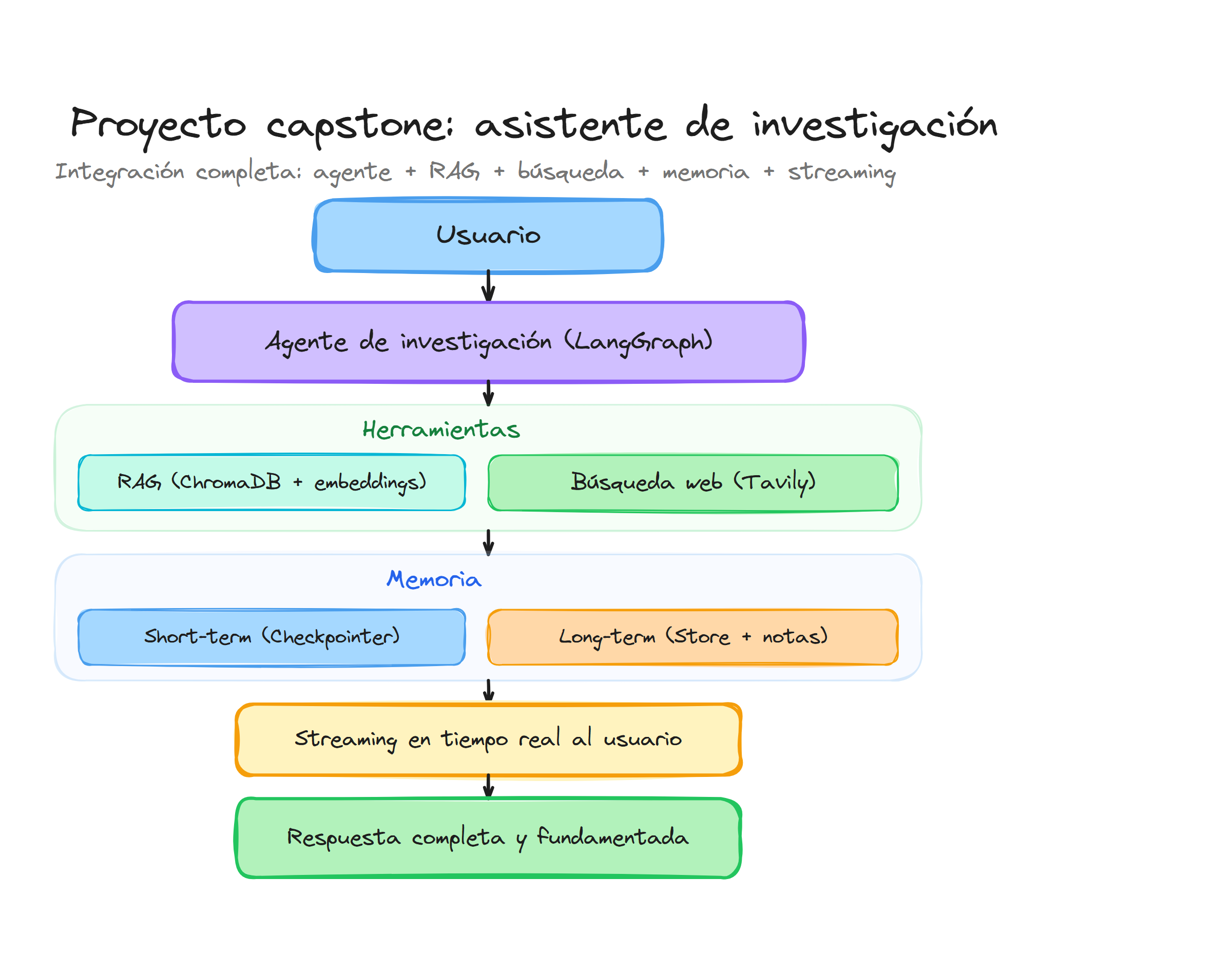
La arquitectura del sistema sigue este flujo:
[Usuario] → [Agente] → [Decisión: ¿qué herramienta usar?]
↓
┌───────────────┼───────────────┐
↓ ↓ ↓
[Búsqueda RAG] [Búsqueda Web] [Guardar Nota]
↓ ↓ ↓
└───────────────┴───────────────┘
↓
[Respuesta Final]
Configuración del entorno
Instalación de dependencias
Crea un archivo requirements.txt con las dependencias necesarias:
langchain>=1.1.0
langchain-openai>=0.3.0
langchain-chroma>=0.2.0
langchain-tavily>=0.1.0
langgraph>=0.4.0
python-dotenv>=1.0.0
Instala las dependencias ejecutando:
pip install -r requirements.txt
Variables de entorno
Crea un archivo .env en la raíz del proyecto con tus claves API:
OPENAI_API_KEY=tu_clave_openai
TAVILY_API_KEY=tu_clave_tavily
Estructura del proyecto
Organiza el proyecto con la siguiente estructura de archivos:
asistente_investigacion/
├── .env
├── requirements.txt
├── documentos/
│ └── (tus archivos .txt o .pdf)
├── datos/
│ └── chroma_db/
└── main.py
Configuración inicial del código
Comenzamos creando la estructura base del proyecto con las importaciones y carga de variables de entorno:
import os
from dotenv import load_dotenv
# Cargar variables de entorno
load_dotenv()
# Verificar configuración
if not os.getenv("OPENAI_API_KEY"):
raise ValueError("OPENAI_API_KEY no configurada")
if not os.getenv("TAVILY_API_KEY"):
raise ValueError("TAVILY_API_KEY no configurada")
print("Configuración cargada correctamente")
Creación de la base de conocimientos RAG
La base de conocimientos permite al agente consultar documentos propios mediante búsqueda semántica. Implementamos el pipeline RAG completo: carga de documentos, división en chunks, generación de embeddings y almacenamiento vectorial.
Carga y procesamiento de documentos
from langchain_community.document_loaders import DirectoryLoader, TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
# Cargar documentos desde el directorio
loader = DirectoryLoader(
"documentos/",
glob="**/*.txt",
loader_cls=TextLoader
)
documents = loader.load()
# Dividir en chunks para mejor recuperación
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
separators=["\n\n", "\n", ". ", " ", ""]
)
chunks = text_splitter.split_documents(documents)
print(f"Documentos cargados: {len(documents)}")
print(f"Chunks generados: {len(chunks)}")
El RecursiveCharacterTextSplitter divide los documentos de forma inteligente respetando la estructura del texto. El overlap de 200 caracteres asegura que no se pierda contexto entre chunks adyacentes.
Creación del vector store con ChromaDB
from langchain_openai import OpenAIEmbeddings
from langchain_chroma import Chroma
# Modelo de embeddings
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
# Crear o cargar el vector store persistente
vectorstore = Chroma.from_documents(
documents=chunks,
embedding=embeddings,
persist_directory="datos/chroma_db",
collection_name="base_conocimientos"
)
# Crear retriever con búsqueda MMR para diversidad
retriever = vectorstore.as_retriever(
search_type="mmr",
search_kwargs={"k": 4, "fetch_k": 10}
)
Utilizamos MMR (Maximum Marginal Relevance) como estrategia de búsqueda para obtener resultados relevantes pero diversos, evitando documentos muy similares entre sí.
Herramienta de búsqueda RAG
Convertimos el retriever en una herramienta que el agente puede invocar:
from langchain_core.tools import tool
from typing import List
@tool(response_format="content_and_artifact")
def buscar_documentos(consulta: str) -> tuple[str, List[dict]]:
"""Busca información en la base de conocimientos local.
Usa esta herramienta cuando el usuario pregunte sobre temas
que podrían estar en los documentos cargados.
Args:
consulta: La pregunta o tema a buscar en los documentos
"""
docs = retriever.invoke(consulta)
if not docs:
return "No se encontró información relevante en los documentos.", []
# Formatear contenido para el modelo
contenido = "\n\n".join([
f"[Fuente: {doc.metadata.get('source', 'desconocida')}]\n{doc.page_content}"
for doc in docs
])
# Metadatos como artefacto
metadatos = [
{"fuente": doc.metadata.get("source"), "contenido": doc.page_content[:200]}
for doc in docs
]
return contenido, metadatos
El formato content_and_artifact separa el contenido que ve el modelo de los metadatos que puede usar la aplicación.
Herramientas del agente
Además de la búsqueda RAG, el agente dispone de herramientas para buscar en la web y guardar notas importantes.
Búsqueda web con Tavily
from langchain_tavily import TavilySearch
# Configurar herramienta de búsqueda web
buscar_web = TavilySearch(
max_results=5,
search_depth="basic",
include_answer=True,
include_raw_content=False
)
buscar_web.name = "buscar_web"
buscar_web.description = """Busca información actualizada en Internet.
Usa esta herramienta para consultas sobre eventos recientes,
noticias, precios actuales o cualquier información que requiera datos en tiempo real."""
TavilySearch proporciona resultados optimizados para modelos de lenguaje, con información estructurada y fuentes verificadas.
Herramienta para guardar notas con acceso al Store
En LangChain 1.1.0, las herramientas pueden acceder al store del agente mediante el parámetro ToolRuntime. Esto permite que las herramientas lean y escriban en la memoria a largo plazo:
from langchain_core.tools import tool, ToolRuntime
from dataclasses import dataclass
@dataclass
class AppContext:
"""Contexto de la aplicación con el ID del usuario."""
user_id: str
@tool
def guardar_nota(titulo: str, contenido: str, runtime: ToolRuntime[AppContext]) -> str:
"""Guarda una nota importante para referencia futura.
Usa esta herramienta cuando el usuario quiera recordar
algo específico de la investigación.
Args:
titulo: Título breve de la nota
contenido: Contenido detallado a guardar
"""
store = runtime.store
user_id = runtime.context.user_id
nota = {"titulo": titulo, "contenido": contenido}
store.put(
namespace=("notas", user_id),
key=titulo.lower().replace(" ", "_"),
value=nota
)
return f"Nota '{titulo}' guardada correctamente."
@tool
def listar_notas(runtime: ToolRuntime[AppContext]) -> str:
"""Lista todas las notas guardadas por el usuario."""
store = runtime.store
user_id = runtime.context.user_id
items = list(store.search(("notas", user_id)))
if not items:
return "No hay notas guardadas."
resultado = "Notas guardadas:\n"
for item in items:
nota = item.value
resultado += f"- {nota['titulo']}: {nota['contenido'][:100]}...\n"
return resultado
El ToolRuntime proporciona acceso al store y al contexto de la aplicación, permitiendo que las herramientas interactúen con la memoria a largo plazo de forma segura.
Construcción del agente con memoria
Configuración del agente
Creamos el agente utilizando create_agent con todas las herramientas configuradas:
from langchain.agents import create_agent
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.store.memory import InMemoryStore
# Checkpointer para memoria a corto plazo (estado de conversación)
checkpointer = InMemorySaver()
# Store para memoria a largo plazo (datos persistentes entre sesiones)
store = InMemoryStore()
# Lista de herramientas disponibles
tools = [
buscar_documentos,
buscar_web,
guardar_nota,
listar_notas
]
# System prompt del asistente
system_prompt = """Eres un asistente de investigación personal experto y metódico.
Tu objetivo es ayudar al usuario a investigar cualquier tema combinando:
1. Búsqueda en documentos locales (base de conocimientos del usuario)
2. Búsqueda web para información actualizada
3. Gestión de notas para guardar hallazgos importantes
Directrices de comportamiento:
- Primero busca en los documentos locales si el tema podría estar ahí
- Complementa con búsqueda web cuando necesites información actualizada
- Cita las fuentes de información cuando sea relevante
- Sugiere guardar notas cuando encuentres información valiosa
- Sé conciso pero completo en tus respuestas
Siempre indica qué herramientas usaste para obtener la información."""
# Crear el agente
agent = create_agent(
model="gpt-5.4",
tools=tools,
checkpointer=checkpointer,
store=store,
context_schema=AppContext,
system_prompt=system_prompt
)
El InMemorySaver actúa como checkpointer para mantener el estado de la conversación dentro de un hilo. El InMemoryStore permite almacenar datos que persisten entre diferentes hilos de conversación.
Configuración de memoria a corto plazo
La memoria a corto plazo se gestiona mediante el thread_id en la configuración:
# Configuración para una sesión de conversación
config = {
"configurable": {
"thread_id": "sesion_investigacion_1"
}
}
# Contexto con el ID del usuario
context = AppContext(user_id="usuario_1")
# El agente recuerda el contexto dentro del mismo thread
respuesta1 = agent.invoke(
{"messages": [{"role": "user", "content": "Busca información sobre machine learning"}]},
config=config,
context=context
)
# En la siguiente pregunta, el agente recuerda el contexto anterior
respuesta2 = agent.invoke(
{"messages": [{"role": "user", "content": "¿Qué aplicaciones tiene?"}]},
config=config,
context=context
)
Al mantener el mismo thread_id, el agente conserva todo el historial de la conversación y puede responder preguntas de seguimiento correctamente.
Streaming y respuestas estructuradas
Implementación de streaming
El streaming permite mostrar el progreso del agente en tiempo real:
def ejecutar_con_streaming(pregunta: str, config: dict, context: AppContext):
"""Ejecuta una consulta mostrando el progreso en tiempo real."""
print(f"\n{'='*50}")
print(f"Pregunta: {pregunta}")
print(f"{'='*50}\n")
for modo, chunk in agent.stream(
{"messages": [{"role": "user", "content": pregunta}]},
config=config,
context=context,
stream_mode=["updates", "messages"]
):
if modo == "updates":
for paso, datos in chunk.items():
ultimo_mensaje = datos["messages"][-1]
# Mostrar llamadas a herramientas
if hasattr(ultimo_mensaje, "tool_calls") and ultimo_mensaje.tool_calls:
for tool_call in ultimo_mensaje.tool_calls:
print(f"[Herramienta] Usando: {tool_call['name']}")
print(f"[Herramienta] Args: {tool_call['args']}\n")
elif modo == "messages":
token, metadata = chunk
# Mostrar tokens de respuesta final
if metadata.get("langgraph_node") == "model":
if hasattr(token, "content") and token.content:
print(token.content, end="", flush=True)
print("\n")
Esta función muestra qué herramientas está usando el agente y va imprimiendo la respuesta token a token.
Respuestas estructuradas
Para ciertos casos, podemos solicitar respuestas en formato estructurado:
from pydantic import BaseModel, Field
from typing import List, Optional
class ResumenInvestigacion(BaseModel):
"""Estructura para resúmenes de investigación."""
tema: str = Field(description="Tema principal de la investigación")
puntos_clave: List[str] = Field(description="Puntos clave encontrados")
fuentes_consultadas: List[str] = Field(description="Fuentes de información")
proximos_pasos: Optional[List[str]] = Field(default=None, description="Siguientes pasos sugeridos")
# Usar con el modelo directamente para respuestas estructuradas
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-5.4")
llm_estructurado = llm.with_structured_output(ResumenInvestigacion)
def generar_resumen(tema: str, contenido: str) -> ResumenInvestigacion:
"""Genera un resumen estructurado de la investigación."""
prompt = f"""Genera un resumen estructurado sobre: {tema}
Contenido de la investigación:
{contenido}
"""
return llm_estructurado.invoke(prompt)
Aplicación completa
Código integrado final
A continuación el código completo del asistente de investigación:
import os
from dotenv import load_dotenv
from typing import List
from dataclasses import dataclass
from langchain.agents import create_agent
from langchain_core.tools import tool, ToolRuntime
from langchain_openai import OpenAIEmbeddings
from langchain_chroma import Chroma
from langchain_tavily import TavilySearch
from langchain_community.document_loaders import DirectoryLoader, TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.store.memory import InMemoryStore
# Cargar configuración
load_dotenv()
# === CONTEXTO DE APLICACIÓN ===
@dataclass
class AppContext:
user_id: str
# === CONFIGURACIÓN RAG ===
def inicializar_vectorstore():
"""Inicializa o carga el vector store."""
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
if os.path.exists("documentos/") and os.listdir("documentos/"):
loader = DirectoryLoader("documentos/", glob="**/*.txt", loader_cls=TextLoader)
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, chunk_overlap=200
)
chunks = text_splitter.split_documents(documents)
vectorstore = Chroma.from_documents(
documents=chunks,
embedding=embeddings,
persist_directory="datos/chroma_db",
collection_name="base_conocimientos"
)
print(f"Base de conocimientos creada con {len(chunks)} chunks")
else:
vectorstore = Chroma(
embedding_function=embeddings,
persist_directory="datos/chroma_db",
collection_name="base_conocimientos"
)
print("Base de conocimientos vacía inicializada")
return vectorstore
vectorstore = inicializar_vectorstore()
retriever = vectorstore.as_retriever(search_type="mmr", search_kwargs={"k": 4})
# === HERRAMIENTAS ===
@tool(response_format="content_and_artifact")
def buscar_documentos(consulta: str) -> tuple[str, List[dict]]:
"""Busca información en la base de conocimientos local."""
docs = retriever.invoke(consulta)
if not docs:
return "No se encontró información en los documentos.", []
contenido = "\n\n".join([
f"[{doc.metadata.get('source', 'documento')}]\n{doc.page_content}"
for doc in docs
])
metadatos = [{"fuente": doc.metadata.get("source")} for doc in docs]
return contenido, metadatos
buscar_web = TavilySearch(max_results=5, include_answer=True)
buscar_web.name = "buscar_web"
buscar_web.description = "Busca información actualizada en Internet."
@tool
def guardar_nota(titulo: str, contenido: str, runtime: ToolRuntime[AppContext]) -> str:
"""Guarda una nota para referencia futura."""
store = runtime.store
user_id = runtime.context.user_id
store.put(("notas", user_id), titulo.lower().replace(" ", "_"),
{"titulo": titulo, "contenido": contenido})
return f"Nota '{titulo}' guardada."
@tool
def listar_notas(runtime: ToolRuntime[AppContext]) -> str:
"""Lista las notas guardadas."""
store = runtime.store
user_id = runtime.context.user_id
items = list(store.search(("notas", user_id)))
if not items:
return "No hay notas guardadas."
return "\n".join([f"- {i.value['titulo']}" for i in items])
# === AGENTE ===
checkpointer = InMemorySaver()
store = InMemoryStore()
agent = create_agent(
model="gpt-5.4",
tools=[buscar_documentos, buscar_web, guardar_nota, listar_notas],
checkpointer=checkpointer,
store=store,
context_schema=AppContext,
system_prompt="""Eres un asistente de investigación. Combina búsqueda en documentos
locales y web para responder. Cita fuentes y sugiere guardar notas importantes."""
)
# === INTERFAZ ===
def chat():
"""Loop principal de interacción."""
config = {"configurable": {"thread_id": "sesion_1"}}
context = AppContext(user_id="usuario_1")
print("\nAsistente de Investigación Personal")
print("Comandos: 'salir' para terminar, 'nueva' para nueva sesión\n")
while True:
pregunta = input("Tú: ").strip()
if pregunta.lower() == "salir":
print("Hasta pronto.")
break
elif pregunta.lower() == "nueva":
config["configurable"]["thread_id"] = f"sesion_{hash(pregunta)}"
print("Nueva sesión iniciada.\n")
continue
elif not pregunta:
continue
print("\nAsistente: ", end="")
for modo, chunk in agent.stream(
{"messages": [{"role": "user", "content": pregunta}]},
config=config,
context=context,
stream_mode=["updates", "messages"]
):
if modo == "messages":
token, meta = chunk
if meta.get("langgraph_node") == "model" and hasattr(token, "content"):
print(token.content, end="", flush=True)
print("\n")
if __name__ == "__main__":
chat()
Ejemplo de sesión de uso
Asistente de Investigación Personal
Comandos: 'salir' para terminar, 'nueva' para nueva sesión
Tú: Busca información sobre redes neuronales en mis documentos
Asistente: He encontrado información en tus documentos sobre redes neuronales...
[Muestra contenido de los documentos locales]
Tú: ¿Cuáles son las últimas novedades en este campo?
Asistente: Según búsquedas recientes en la web, las principales novedades son...
[Muestra información actualizada de Tavily]
Tú: Guarda una nota con los puntos más importantes
Asistente: He guardado la nota "Puntos clave redes neuronales" con el resumen...
Tú: salir
Hasta pronto.
Este proyecto capstone demuestra cómo integrar RAG, herramientas personalizadas, búsqueda web, memoria a corto y largo plazo, y streaming en una aplicación cohesiva y funcional con LangChain 1.1.0. Los conceptos aprendidos durante el curso se combinan para crear un asistente de investigación completo que puede adaptarse a diferentes casos de uso.

Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, LangChain es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de LangChain
Explora más contenido relacionado con LangChain y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Cursos que incluyen esta lección
Esta lección forma parte de los siguientes cursos estructurados con rutas de aprendizaje